Strong Consistency with YugabyteDB
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see why the default strong consistency guarantees offered by YugabyteDB allow you to design applications that are more resilient than when using traditional relational database systems.
If you’re new to YugabyteDB, check out this article first, in which I explain what YugabyteDB is and why you should consider using it.
The race condition that led to bankruptcy
As I explained in this article, Flexycoin went bankrupt because of a data anomaly that got exploited by hackers.
Now, replicating such a race condition is actually very easy. All we need to do is create a TransferService interface and implementation and an AccountRepository, as illustrated by the following diagram:
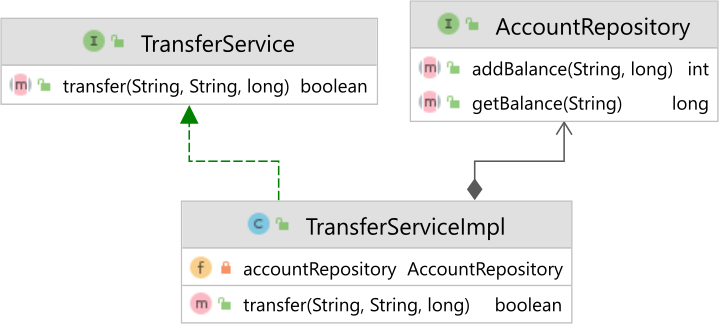
The TransferServiceImpl implements the transfer method like this:
@Service
public class TransferServiceImpl implements TransferService {
@Autowired
private AccountRepository accountRepository;
@Transactional
public boolean transfer(String fromIban, String toIban, long cents) {
boolean status = true;
long fromBalance = accountRepository.getBalance(fromIban);
if(fromBalance >= cents) {
status &= accountRepository.addBalance(
fromIban,
(-1) * cents
) > 0;
status &= accountRepository.addBalance(
toIban,
cents
) > 0;
}
return status;
}
}
And the AccountRepository defines the getBalance and addBalance methods using simplest-possible SQL statements:
@Repository
@Transactional(readOnly = true)
public interface AccountRepository
extends JpaRepository<Account, String> {
@Query(value = """
SELECT balance
FROM account
WHERE iban = :iban
""",
nativeQuery = true)
long getBalance(@Param("iban") String iban);
@Query(value = """
UPDATE account
SET balance = balance + :cents
WHERE iban = :iban
""",
nativeQuery = true)
@Modifying
@Transactional
int addBalance(@Param("iban") String iban, @Param("cents") long cents);
}
And, when running a transfer between two accounts using multiple concurrent threads on PostgreSQL:
assertEquals(10L, accountRepository.getBalance("Alice-123"));
assertEquals(0L, accountRepository.getBalance("Bob-456"));
CountDownLatch startLatch = new CountDownLatch(1);
CountDownLatch endLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
new Thread(() -> {
try {
startLatch.await();
transferService.transfer("Alice-123", "Bob-456", 5L);
} catch (Exception e) {
LOGGER.error("Transfer failed", e);
} finally {
endLatch.countDown();
}
}).start();
}
LOGGER.info("Starting threads");
startLatch.countDown();
endLatch.await();
LOGGER.info("Alice's balance: {}", accountRepository.getBalance("Alice-123"));
LOGGER.info("Bob's balance: {}", accountRepository.getBalance("Bob-456"));
We are going to get the following account balances at the end:
Alice's balance: -35 Bob's balance: 45
And, it doesn’t matter if we’re using PostgreSQL, MySQL, Oracle, or SQL Server. We are always going to get this anomaly because the default isolation level of each and every one of those relational databases does not prevent the Lost Update phenomenon.
Default Strong Consistency with YugabyteDB
However, if we run the same test case on YugabyteDB, we get the following outcome:
Alice's balance: 0 Bob's balance: 10
Why does it work just fine on YugabyteDB while the concurrent transfer fails on PostgreSQL, MySQL, Oracle, or SQL Server?
And the answer is given by the default isolation level used by Yugabyte, which is Snapshot Isolation.
Snapshot isolation is a very popular isolation level when using MVCC (Multi-Version Concurrency Control) since it allows transactions to view the database as of the beginning of each transaction, therefore preventing Non-Repeatable Reads, Phantom Reads, or Read Skews.
And that’s why many relational database systems use Snapshot Isolation. For instance, the Repeatable Read isolation level in PostgreSQL is basically Snapshot Isolation.
However, the Snapshot isolation can also prevent Lost Updates, and that’s why we don’t get this anomaly when using the default Yugabyte isolation level.
In fact, we can easily validate how Yugabyte behaves when changing the transaction isolation level using the YugabyteDBPhenomenaTest integration test.
And, we get the following result:
| Isolation level | Dirty Read | Non-Repeatable Read | Phantom Read | Read Skew | Write Skew | Lost Update | |------------------|------------|---------------------|--------------|-----------|------------|-------------| | Read Uncommitted | No | No | No | No | Yes | No | | Read Committed | No | No | No | No | Yes | No | | Repeatable Read | No | No | No | No | Yes | No | | Serializable | No | No | No | No | No | No |
You can read the table like this:
Yesmeans the anomaly is allowed for that particular isolation levelNomeans the anomaly is prevented by that particular isolation level
By default, the SQL standard Repeatable Read, Read Committed, and Read Uncommitted isolation levels are mapped to Snapshot Isolation, which can prevent almost every anomaly except for the Write Skew anomaly while the Serializable isolation level prevents all anomalies.
The reason why YugabyteDB uses a stronger isolation level by default is that it cannot afford inconsistencies when executing SQL statements that are distributed across multiple shards.
By using the RAFT consensus protocol to synchronize changes between cluster nodes, Snapshot Isolation becomes the right choice. And, since Snapshot Isolation is an optimistic concurrency control mechanism, this allows YugabyteDB to find the right balance between performance and consistency.
In fact, as explained in the documentation, the Read Committed isolation level requires you to set the yb_enable_read_committed_isolation setting to true in order to use it.
If you want to enable the yb_enable_read_committed_isolation setting, you could do it like this when starting the Docker container:
docker run
-d --name yugabyte \
-p7000:7000 -p9000:9000 -p5433:5433 -p9042:9042 \
yugabytedb/yugabyte:2.15.1.0-b175 bin/yugabyted start \
--daemon=false --ui=false \
--tserver_flags="yb_enable_read_committed_isolation=true"
And, when rerunning the YugabyteDBPhenomenaTest, we get the following output:
| Isolation level | Dirty Read | Non-Repeatable Read | Phantom Read | Read Skew | Write Skew | Lost Update | |------------------|------------|---------------------|--------------|-----------|------------|-------------| | Read Uncommitted | No | Yes | Yes | Yes | Yes | Yes | | Read Uncommitted | No | Yes | Yes | Yes | Yes | Yes | | Repeatable Read | No | No | No | No | Yes | No | | Serializable | No | No | No | No | No | No |
While it was not initially supported, YugabyteDB decided to support Read Committed to improve compatibility with PostgreSQL, which uses Read Committed by default. Since Snapshot Isolation (Repeatable Read) increases the likelihood of conflicts, the application behavior could change as more transactions will have to be rolled back in case of data anomalies.
Having a Read Committed isolation level allows YugabyteDB to behave like PostgreSQL, Oracle, or SQL Server when running in the default Read Committed mode, therefore making the migration to YugabyteDB a very simple process that requires no change to the application data access logic.
Any isolation level higher than Read Committed requires the application to handle serialization errors (e.g.,
SQLSTATE 40001) with an additional retry logic. For this reason, Read Committed is required to migrate applications without changing code.
YugabyteDB is really a truly MVCC database
Now, what caused my attention while reading the YugabyteDB documentation was the fact that the Read Committed isolation level was implemented using pessimistic locking, which made me curious since most relational databases use MVCC by default.
After digging more into it, I realized that YugabyteDB has a completely different approach to preventing Dirty Writes than all relational database systems I’ve tested. A Dirty Write anomaly would happen if two concurrent transactions were allowed to modify the same record at the same time, and this is a very dangerous anomaly as it could compromise Atomicity (the A in ACID) since rollbacks will not allow the database to return to the previous consistent state in which the database was at the beginning of the transaction.
Even if Oracle, PostgreSQL, or MySQL use MVCC, as opposed to the 2PL (Two-Phase Locking) mechanism used by default by SQL Server, only one transaction is allowed to change a given record, meaning that a Write or Exclusive Lock is acquired whenever a transaction issues an UPDATE or DELETE on a given table row.
This is what YugabyteDB means when it says that it implemented the Read Committed isolation level using pessimistic locking. When using Read Committed, YugabyteDB will also lock modified records until the transaction is committed or rolled back, just like PostgreSQL, Oracle, MySQL, or SQL Server do.
In fact, I could actually validate this behavior with my AbstractPhenomenaTest as I had to change the Dirty Write anomaly detection to support MVCC. Due to its distributed nature, YugabyteDB is required to reduce the use of locks as much as possible, and that’s why its default Snapshot Isolation level is able to detect all anomalies using optimistic locking, even for Dirty Writes.
Impressive, to say the least! I didn’t even know this was possible. I always took the Oracle, SQL Server, PostgreSQL, or MySQL behavior for granted, believing that you cannot have Atomicity unless you are locking the records that you are modifying. Well, you can actually use optimistic locking for that, therefore increasing scalability.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
YugabyteDB uses a much stronger consistency model than most relational database systems. While Oracle, PostgreSQL, and SQL Server use Read Committed by default, YugabyteDB prefers the Snapshot Isolation mode, which is a strong isolation level.
Using a stronger isolation level by default makes it much easier to implement a database application as there are fewer data integrity issues you should prevent explicitly.
Concurrency control issues are very hard to reason about. Even Google developers are better off using a stronger consistency model when developing all the Google services that require data integrity, as depicted by the Google Spanner paper:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise rather than always coding around the lack of transactions.
So, if it’s hard for Google developers to use weaker consistency models to develop software systems that work correctly, you might also benefit from using a stronger isolation level by default.
This research was funded by Yugabyte and conducted in accordance with the blog ethics policy.
While the article was written independently and reflects entirely my opinions and conclusions, the amount of work involved in making this article happen was compensated by Yugabyte.








