How does the 2PL (Two-Phase Locking) algorithm work
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
The 2PL (Two-Phase Locking) algorithm is one of the oldest concurrency control mechanisms used by relational database systems to guarantee data integrity.
In this article, I’m going to explain how the 2PL algorithm works and how you can implement it in any programming language.
How does the 2PL (Two-Phase Locking) algorithm work? @vlad_mihalcea explains.https://t.co/J4BtK3qQJn pic.twitter.com/pm12b3tE7t
— Java (@java) December 4, 2019
Lock types
Before we start discussing the 2PL algorithm implementation, it’s very important to explain how the read and write locks work.
A read or share lock prevents a resource from being written while allowing other concurrent reads.
A write or exclusive lock disallows both read and write operations on a given resource.
| Compatibility matrix | Read lock | Write Lock |
|---|---|---|
| Read lock | Allow | Prevent |
| Write lock | Prevent | Prevent |
Some database systems, like PostgreSQL, MySQL, or SQL Server, offer the possibility of acquiring read and write locks on a given tuple or range of tuples. Other database systems, like Oracle, only allow write/exclusive locks to be acquired via the FOR UPDATE clause.
| Database name | Read lock clause | Write lock clause |
|---|---|---|
| Oracle | FOR UPDATE | FOR UPDATE |
| SQL Server | WITH (HOLDLOCK, ROWLOCK) |
WITH (HOLDLOCK, UPDLOCK, ROWLOCK) |
| PostgreSQL | FOR SHARE | FOR UPDATE |
| MySQL | LOCK IN SHARE MODE | FOR UPDATE |
For more details about how you can acquire read or write locks with JPA and Hibernate, check out this article.
However, read and write locks are not limited to database systems only. While traditionally, entering a Java synchronized block allows the acquisition of an exclusive lock, since version 1.5, Java allows both read and write locks via the ReentrantReadWriteLock object.
Two-Phase Locking
Locks alone are not sufficient for preventing conflicts. A concurrency control strategy must define how locks are being acquired and released because this also has an impact on transaction interleaving.
For this purpose, the 2PL protocol defines a lock management strategy for ensuring Strict Serializability.
The 2PL protocol splits a transaction into two sections:
- expanding phase (locks are acquired, and no lock is allowed to be released)
- shrinking phase (all locks are released, and no other lock can be further acquired).
For a database transaction, the expanding phase means that locks are allowed to be acquired from the beginning of the transaction until its end, while the shrinking phase is represented by the commit or rollback phase, as at the end of a transaction, all the acquired locks are being released.
The following diagram shows how transaction interleaving is coordinated by 2PL:
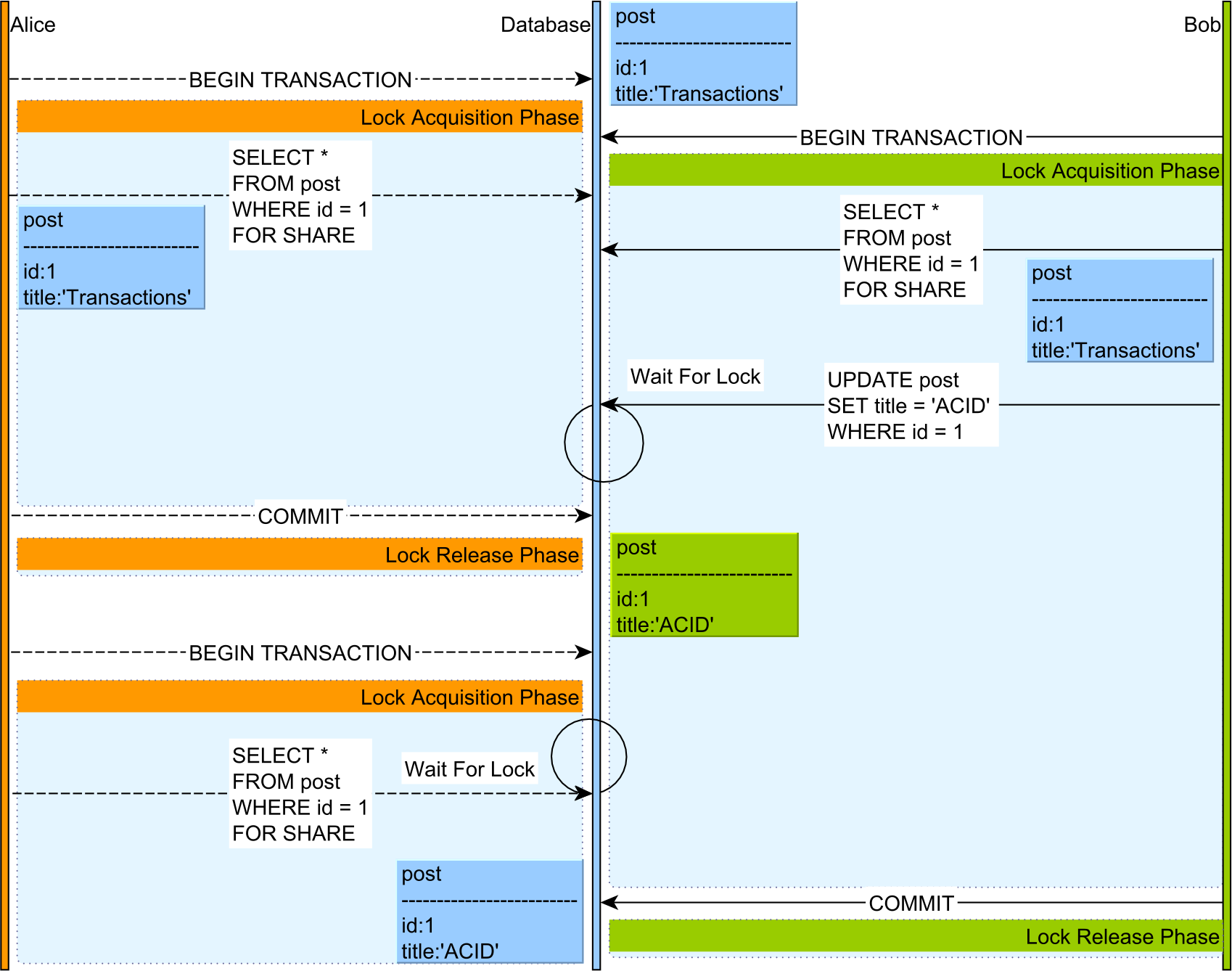
- Both Alice and Bob acquire a read lock on a given a
postrecord via aSELECT FOR SHAREPostgreSQL clause. - When Bob attempts to execute an UPDATE statement on the
postentry, his statement is blocked by the Lock Manager because the UPDATE statement needs to acquire a write lock on thepostrow while Alice is still holding a read lock on this database record. - Only after Alice’s transaction ends and all her locks are being released, Bob can resume his UPDATE operation.
- Bob’s UPDATE statement will generate a lock upgrade, so his previously acquired read lock is replaced by an exclusive lock, which will prevent other transactions from acquiring a read or write lock on the same
postrecord. - Alice starts a new transaction and issues a
SELECT FOR SHAREquery with a read lock acquisition request for the samepostentry, but the statement is blocked by the Lock Manager since Bob owns an exclusive lock on this record. - After Bob’s transaction is committed, all his locks are released, and Alice’s SELECT query can be resumed.
Strict Serializability
The 2PL algorithm offers Strict Serializability, which is the golden standard when it comes to data integrity. Strict Serializability means that the outcome is both Serializable and Linearizable.
Two or more transactions are Serializable if their associated read and write operations are interleaved in such a way that the outcome is equivalent to some serial execution. For example, if we have two transactions A and B, as long as the outcome is either A, B or B, A, the two transactions are Serializable. For N transactions, the outcome must be equivalent to one of the N! transaction permutations.
However, Serializability does not take the flow of time into consideration. On the other hand, Linearizability implies time-based ordering. For example, a system is linearizable if any subsequent read will reflect the changes done by a previous write operation. For more details about Lienearizbaility, check out this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The 2PL (Two-Phase Locking) algorithm was introduced in 1976 in The Notions of Consistency and Predicate Locks in a Database System paper by Kapali Eswaran and Jim Gray (et al.), which demonstrated that Serializability could be obtained if all transactions used the 2PL algorithm.
Initially, all database systems employed 2PL for implementing Serializable transactions, but, with time, many vendors have moved towards MVCC (Multi-Version Concurrency Control) concurrency control mechanisms.
Nowadays, only SQL Server uses the 2PL algorithm by default. However, if you set the READ_COMMITTED_SNAPSHOT orALLOW_SNAPSHOT_ISOLATION MVCC modes at the database level, then SQL Server will switch to using MVCC.
Even if the InnoDB MySQL storage engine is MVCC-based when switching to the Serializable isolation level, the database will use the 2PL algorithm since locks will be acquired on both read and write operations.
For this reason, it’s very important to understand how the 2PL algorithm works and that it can guarantee Strict Serializability.








