A beginner’s guide to Serializability
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see what Serializability means and what guarantees does it offer.
Relational database systems provide a Serializable isolation level that’s supposed to provide transaction Serializability. However, as you will soon see, some databases even provide Strict Serializability, which is a combination of Serializability and Linearizability.
Serial execution
Before explaining what Serializability means, let’s see what a Serial execution is because Serializability is very different from a Serial execution.
Serial execution provides exclusive access to shared resources to one and only one client at a time, as illustrated by the following diagram:
By providing exclusive access to the shared resources, data anomalies can be prevented since every transaction is going to see the database in the consistent state the previous transaction has left it.
There are many technologies using Serial execution, the most popular being JavaScript, Node.js, or Volt DB.
However, there’s a catch. According to Amdahl’s law, the degree of parallelization is inversely proportional to the percentage of Serial execution of a given workload.
Therefore, Serial execution scales poorly; hence it’s limited to systems where data is stored in memory, and each execution takes a very small amount of time.
Concurrency conflicts
The vast majority of relational database systems provide concurrent access via multiple connections. So, at any given time, there could be multiple transactions reading and writing data.
If Serializability is not enforced, conflicts can occur. In the context of database transactions, these conflicts are called phenomena or data anomalies.
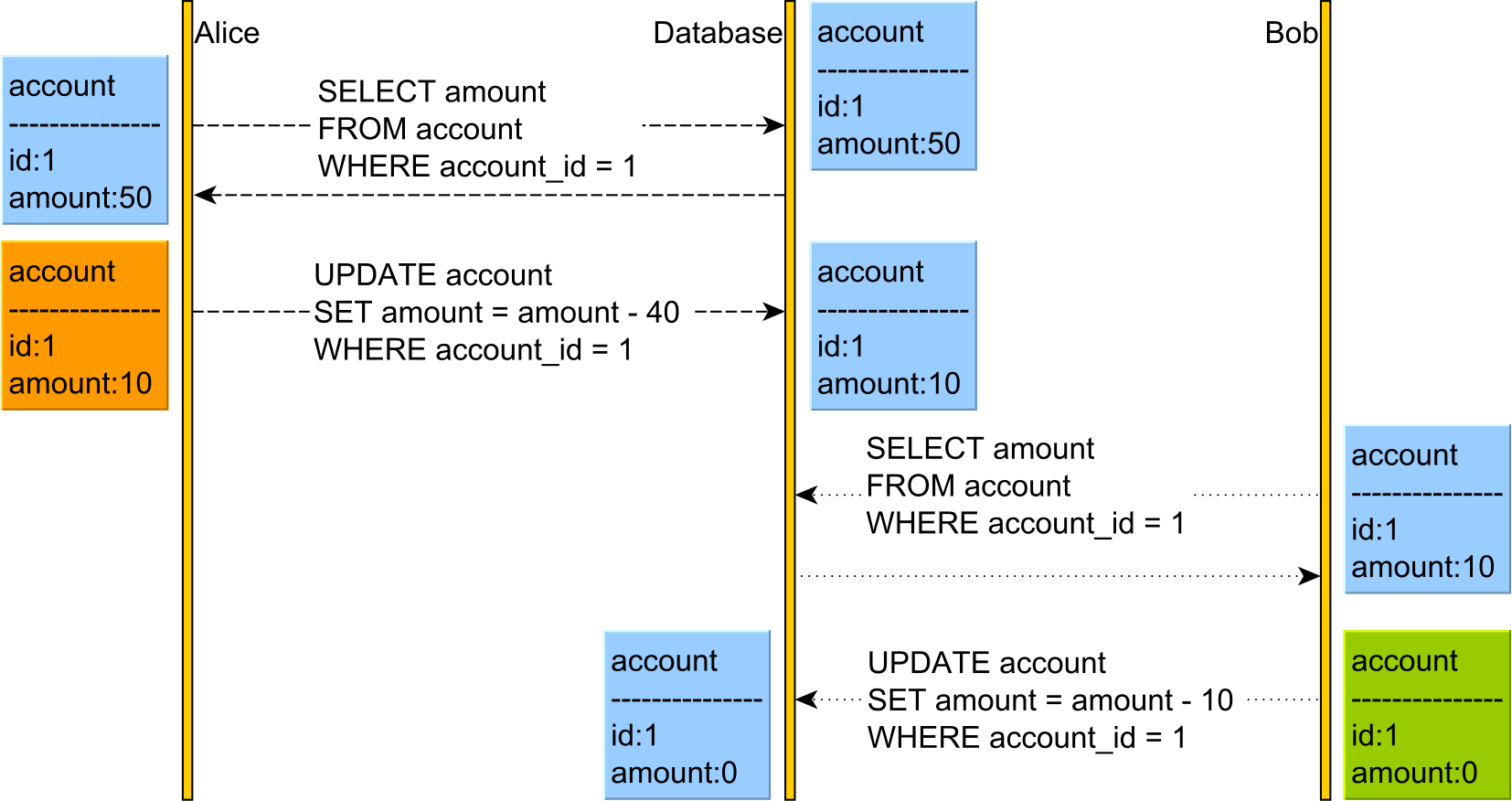
For instance, the following diagram shows you a Lost Update anomaly that can occur in the absence of Serializability:

If you compare the Lost Update anomaly diagram with the Serial execution one, you will see that the reads and writes belonging to different transactions are interleaved in the Lost Update anomaly example.
To avoid data anomalies, the transaction log should linearize transactions so that there is no interleaving of reads and writes belonging to different transactions.
Serializability
So, to avoid conflicts, we must not interleave transactions. While the Serial execution avoids transaction interleaving since every transaction has exclusive access to the database, there is one way we could achieve the same goal without sacrificing parallelism.
And that solution is called Serializability. Unlike Serial execution, Serializability allows multiple concurrent transitions to run, with one catch. The outcome needs to be equivalent to a Serial execution.
Therefore, if both Alice and Bob are running two concurrent transactions, there are only two possible Serial execution outcomes:
- Alice followed by Bob
- Bob followed by Alice
If the statements in the transaction log follow this pattern, the outcome is said to be Serializable.
In case there are three concurrent transactions, A, B, and C, there are 3! = 6 possible Serial execution outcomes. The order doesn’t really matter for Serializability to be achieved. The only constraint is to get a Serial execution outcome.
For N concurrent transactions, there are
N!possible Serial executions, each one providing a proper Serializable execution flow.
However, if the transaction flow is both Serializable and Linarizable (operations are applied instantaneously), then we get a Strict Serializable consistency model.

Serializability implementations
There are two possible ways to implement Serializability:
- 2PL (Two-Phase Locking), and this is what SQL Server and MySQL use to implement the Serializable isolation level,
- Serializable Snapshot Isolation, implemented by PostgreSQL.
The Serializable isolation level in Oracle is actually Snapshot Isolation, and while it prevents many anomalies, it does not prevent all possible Write Skew phenomena.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Serializability allows us to prevent concurrency conflicts without sacrificing parallelism, as Serial execution does.
As long as the outcome is equivalent to any possible Serial execution, multiple transactions can commit successfully, and database systems can use either locks or an MVCC (Multi-Version Concurrency Control) mechanism to achieve that goal.








