A beginner’s guide to Read and Write Skew phenomena
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In my article about ACID and database transactions, I introduced the three phenomena described by the SQL standard:
- dirty read
- non-repeatable read
- phantom read
While these are good to differentiate the four isolation levels (Read Uncommitted, Read Committed, Repeatable Read and Serializable), in reality, there are more phenomena to take into consideration as well. The 1995 paper (A Critique of ANSI SQL Isolation Levels) introduces the other phenomena that are omitted from the standard specification.
In my High-Performance Java Persistence book, I decided to insist on the Transaction chapter as it is very important for both data-access effectiveness and efficiency.
Domain model
For the following examples, I’m going to use the following two entities:
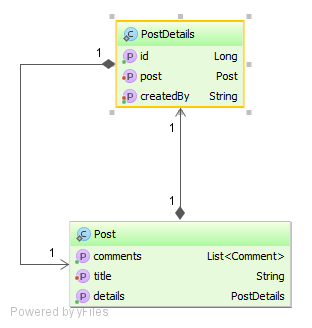
In our fictional application, when the Post title is changed, the author must be recorded in the associated PostDetails record.
If the read and write skew anomalies are not prevented, this domain model constraint can be compromised, as you will see in the following test cases.
Read skew
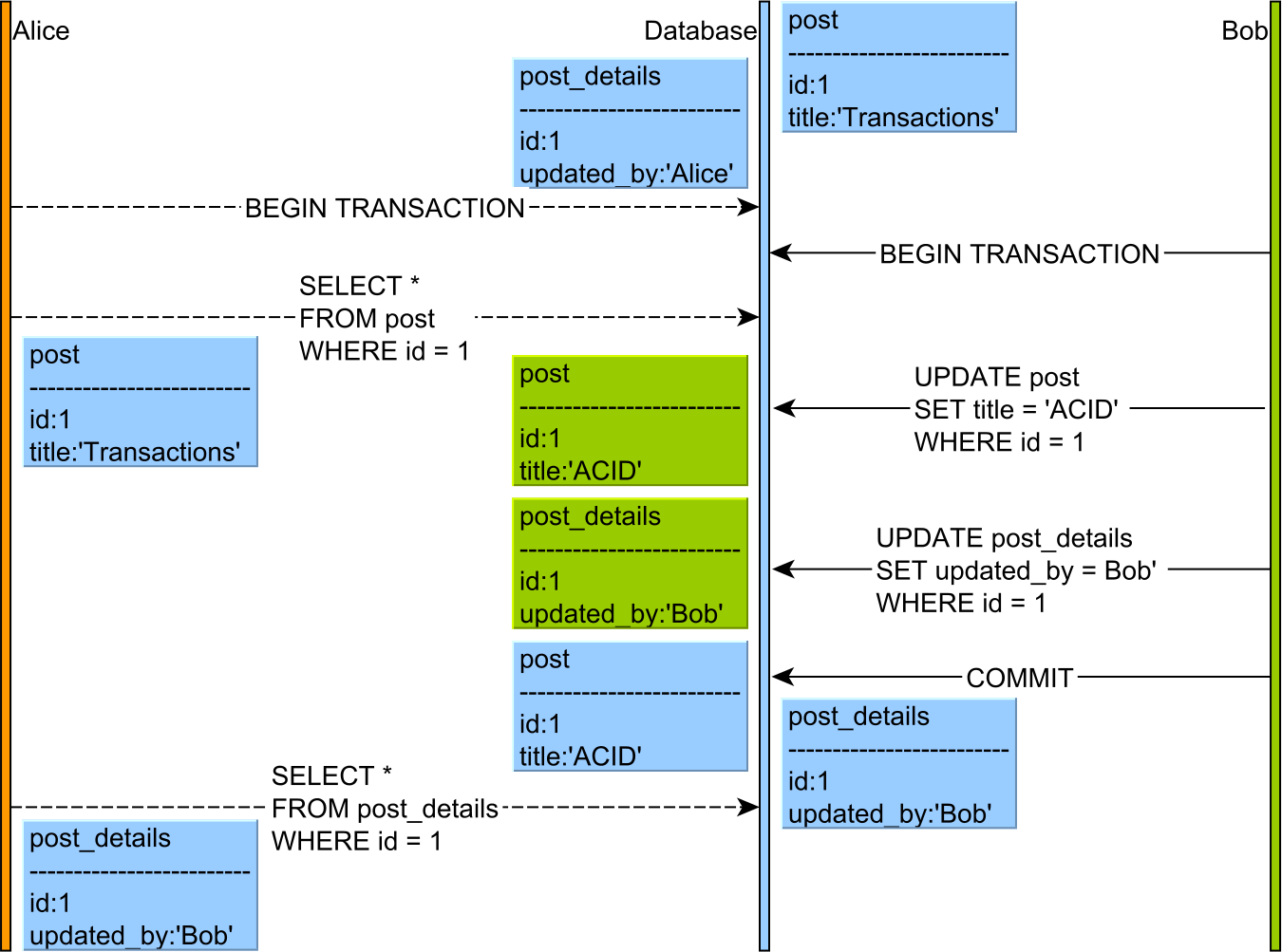
- Alice selects a
Postentity. - Bob sneaks in and updates both the
Postand thePostDetailsentities. - Alice thread is resumed and she selects the
PostDetailsrecord.
If read skew is permitted, Alice sees Bob’s update and she can assume that the previous Post version (that she read at the beginning of her transaction) was issued by Bob, therefore breaking consistency.
Running this test on the four most common relation database systems gives the following results:
| Database isolation level | Read skew |
|---|---|
| Oracle Read Committed | Yes |
| Oracle Serializable | No |
| SQL Server Read Uncommitted | Yes |
| SQL Server Read Committed | Yes |
| SQL Server Read Committed Snapshot Isolation | Yes |
| SQL Server Repeatable Read | No |
| SQL Server Serializable | No |
| SQL Server Snapshot Isolation | No |
| PostgreSQL Read Uncommitted | Yes |
| PostgreSQL Read Committed | Yes |
| PostgreSQL Repeatable Read | No |
| PostgreSQL Serializable | No |
| MySQL Read Uncommitted | Yes |
| MySQL Read Committed | Yes |
| MySQL Repeatable Read | No |
| MySQL Serializable | No |
Write skew
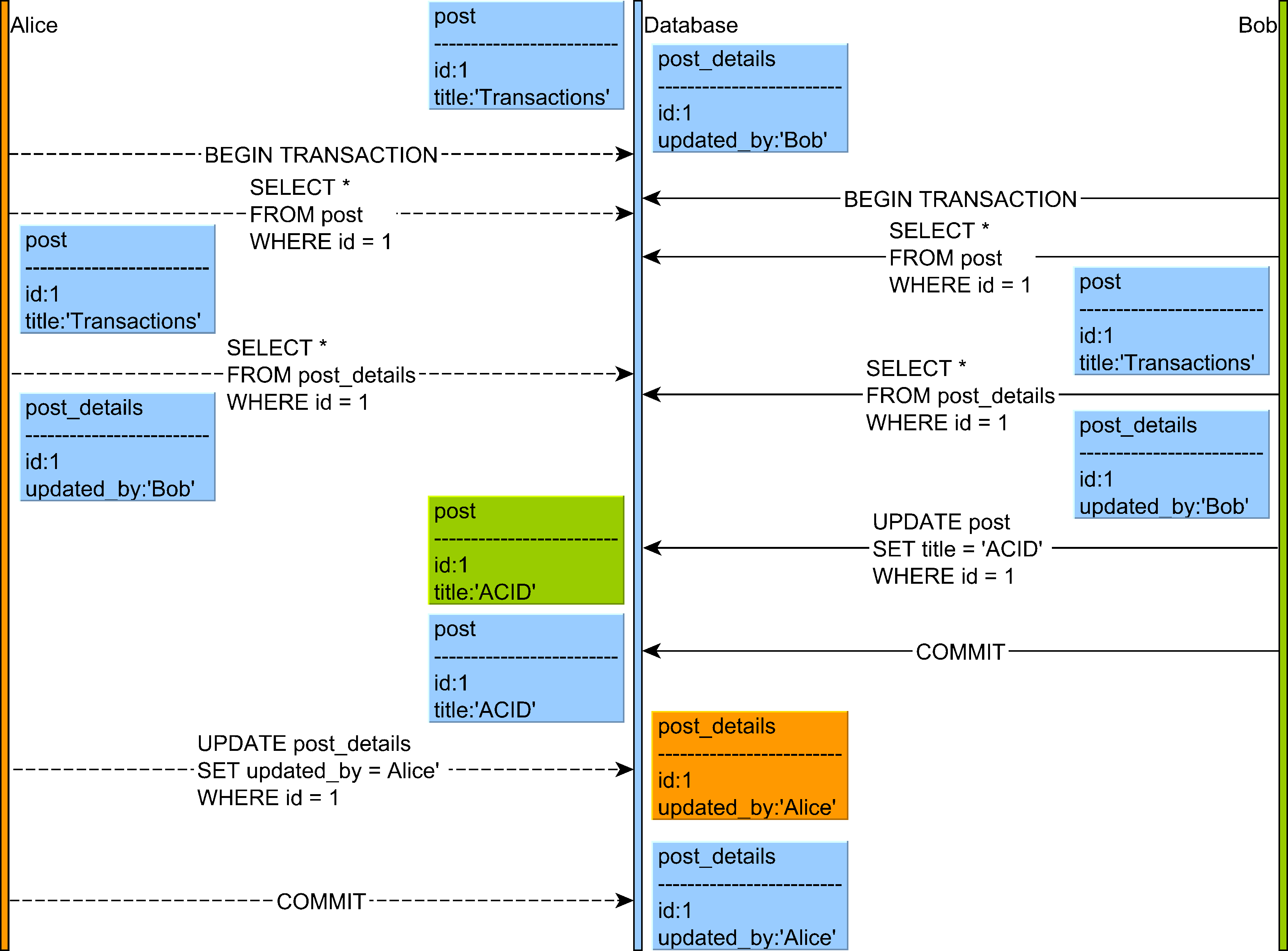
- Both Alice and Bob select the
Postand thePostDetailsentities. - Bob modifies the
Posttitle, but, since thePostDetailsis already marked as updated by Bob, the dirty checking mechanism will skip updating thePostDetailsentity, therefore preventing a redundant UPDATE statement. - Alice wants to update the
Postentity, but the entity already has the same value as the one she wants to apply so only thePostDetailsrecord will mark that the latest change is the one proposed by Alice.
If write skew is permitted, Alice and Bob disjoint writes will proceed, therefore breaking the guarantee that
PostandPostDetailsshould always be in sync.
Running this test on the four most common relation database systems gives the following results:
| Database isolation level | Write skew |
|---|---|
| Oracle Read Committed | Yes |
| Oracle Serializable | Yes |
| SQL Server Read Uncommitted | Yes |
| SQL Server Read Committed | Yes |
| SQL Server Read Committed Snapshot Isolation | Yes |
| SQL Server Repeatable Read | No |
| SQL Server Serializable | No |
| SQL Server Snapshot Isolation | Yes |
| PostgreSQL Read Uncommitted | Yes |
| PostgreSQL Read Committed | Yes |
| PostgreSQL Repeatable Read | Yes |
| PostgreSQL Serializable | No |
| MySQL Read Uncommitted | Yes |
| MySQL Read Committed | Yes |
| MySQL Repeatable Read | Yes |
| MySQL Serializable | No |
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
- Write skew is prevalent among MVCC (Multi-Version Concurrency Control) mechanisms and Oracle cannot prevent it even when claiming to be using Serializable, which in fact is just the Snapshot Isolation level.
- SQL Server default locking-based isolation levels can prevent write skews when using Repeatable Read and Serializable. Neither one of its MVCC-based isolation levels (MVCC-based) can prevent/detect it instead.
- PostgreSQL prevents it by using its more advanced Serializable Snapshot Isolation level.
- MySQL employs shared locks when using Serializable so the write skew can be prevented even if InnoDB is also MVCC-based.








