A beginner’s guide to Non-Repeatable Read anomaly
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
Database transactions are defined by the four properties known as ACID. The Isolation Level (I in ACID) allows you to trade off data integrity for performance.
The weaker the isolation level, the more anomalies can occur, and in this article, we are going to describe the Non-Repeatable Read phenomenon.
A beginner’s guide to Non-Repeatable Read anomaly - @vlad_mihalcea https://t.co/AZzNpLPBkf pic.twitter.com/tZsH7XGwlV
— Java (@java) June 25, 2018
Observing data changed by a concurrent transaction
If one transaction reads a database row without applying a shared lock on the newly fetched record, then a concurrent transaction might change this row before the first transaction has ended.
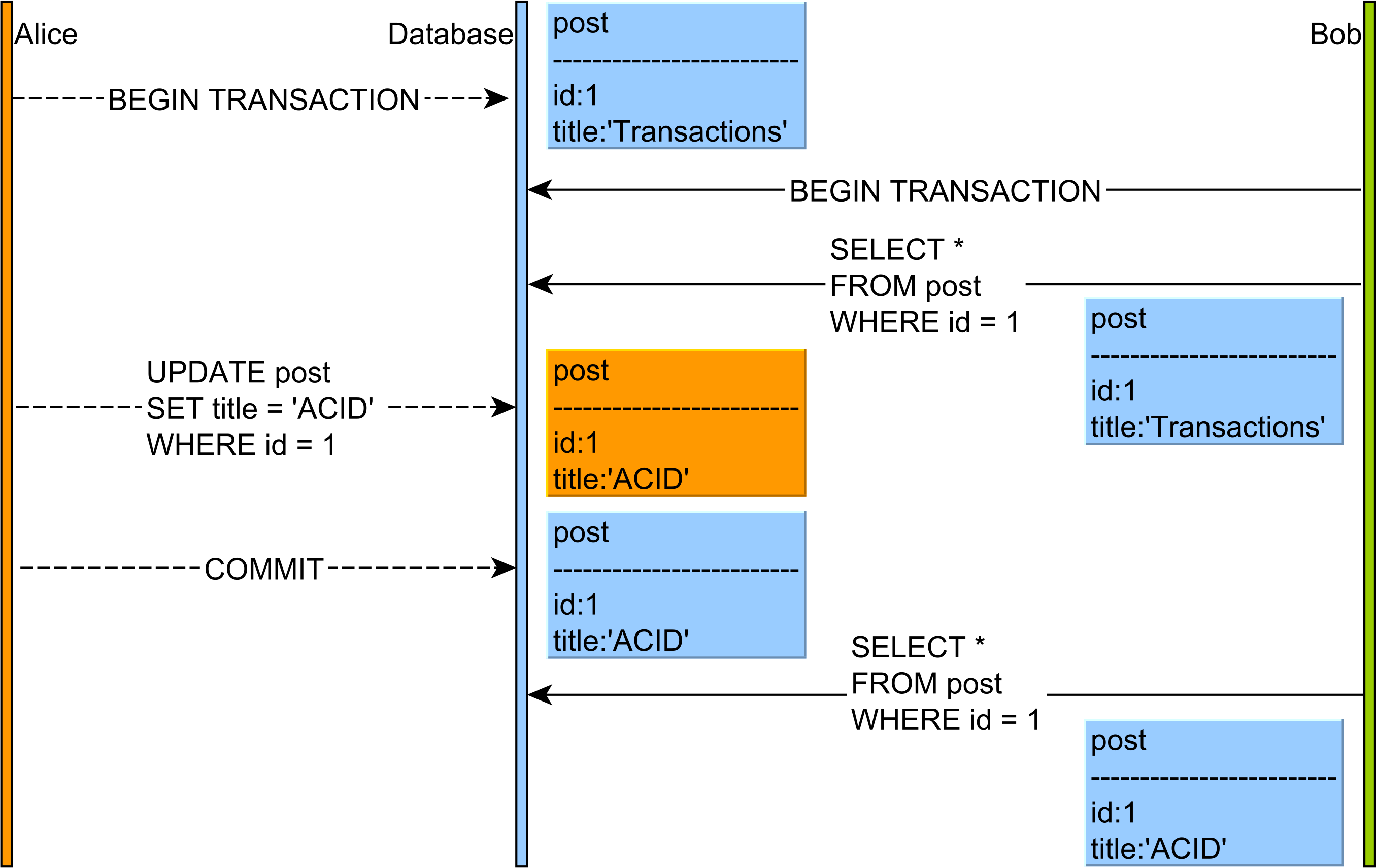
In the diagram above, the flow of statements goes like this:
- Alice and Bob start two database transactions.
- Bob reads the
postrecord andtitlecolumn value isTransactions. - Alice modifies the
titleof a givenpostrecord to the value ofACID. - Alice commits her database transaction.
- If Bob’s re-reads the
postrecord, he will observe a different version of this table row.
This phenomenon is problematic when the current transaction makes a business decision based on the first value of the given database row (a client might order a product based on a stock quantity value that is no longer a positive integer).
How the database prevents it
If a database uses a 2PL (Two-Phase Locking) and shared locks are taken on every read, this phenomenon will be prevented since no concurrent transaction would be allowed to acquire an exclusive lock on the same database record.
Most database systems have moved to an MVCC (Multi-Version Concurrency Control) model, and shared locks are no longer mandatory for preventing non-repeatable reads.
By verifying the current row version, a transaction can be aborted if a previously fetched record has changed in the meanwhile.
Repeatable Read and Serializable prevent this anomaly by default. With Read Committed, it is possible to avoid non-repeatable (fuzzy) reads if the shared locks are acquired explicitly (e.g. SELECT FOR SHARE).
Some ORM frameworks (e.g. JPA/Hibernate) offer application-level repeatable reads. The first snapshot of any retrieved entity is cached in the currently running Persistence Context.
Any successive query returning the same database row is going to use the very same object that was previously cached. This way, the fuzzy reads may be prevented even in Read Committed isolation level.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
This phenomenon is typical for both Read Uncommitted and Read Committed isolation levels. The problem is that Read Committed is the default isolation level for many RDBMS like Oracle, SQL Server or PostgreSQL, so this phenomenon can occur if nothing is done to prevent it.
Nevertheless, preventing this anomaly is fairly simple. All you need to do is use a higher isolation level like Repeatable Read (which is the default in MySQL) or Serializable. Or, you can simply lock the database record using a share(read) lock or an exclusive lock if the underlying database does not support shared locks (e.g. Oracle).







