Hibernate performance tuning tips
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to summarise the most common Hibernate performance tuning tips that can help you speed up your data access layer.
While getting started with JPA and Hibernate is fairly easy, if you want to get the most out of your data access layer, it’s very important to understand how the JPA provider works, as well as the configuration properties that can help you optimize application performance.
https://twitter.com/viktor_khan/status/1149281004957380608
Fetching only the data you really need
Fetching too much data is the number one problem that causes performance issues when it comes to using JPA and Hibernate. That’s because JPA makes it very easy to fetch more data than you really need.
Right from the very beginning, you should prefer using lazy fetching and keep in mind that @ManyToOne and @OneToOne associations are fetched eagerly by default. Prior to Hibernate 5.5, there was no way to switch the fetch strategy from EAGER to LAZY even if you are using JPA entity graphs.
As I explained in this article, since Hibernate 5.5 you can use fetchgraph to override the FetchType.EAGER strategy, but this solution is very brittle since if you forget to JOIN FETCH an EAGER association in a JPQL or Criteria API query, you’ll end up with an N+1 query issue.
For more details about why you should prefer lazy loading, check out this article.
Another very important aspect when fetching data with JPA and Hibernate is to differentiate the use cases that need entities versus the ones that can do just fine with a DTO projection. As a rule of thumb, if you want to INSERT, UPDATE or DELETE records, fetching entities is very convenient, especially due to the automatic dirty checking mechanism.
However, if you only need to display data (e.g. table, trees), and you don’t want to further modify it, then a DTO projection is much more suitable. Unlike entity fetching, a DTO projection allows you the number of columns that you are fetching from the database, and this can speed up queries significantly.
Not only that you should consider the number of columns that you are fetching from the database, but you should limit the number of records as well. If the data is meant to be displayed on the UI, there’s already a limit on how much data you can display in one view, so anything else becomes waste which affects application performance. Also, data tends to grow with time, and if you are not limiting the query result sets, the amount of data being fetched will grow larger and larger. If you want predictable response times, limiting the query result sets is the way to go.
For more details about how the query pagination works and why it provides better SQL execution plans, check out this article.
When mixing
JOIN FETCHand pagination, you might bump into theHHH000104: firstResult/maxResults specified with collection fetch; applying in memoryissue. To fix this problem, check out this article.
Open Session in View and temporary session anti-patterns
As a consequence of not following the previous tip, you might bump into various application architecture anti-patterns like Open Session in View or Temporary Session.
Open Session in View (OSIV) will keep the Hibernate Session open even after leaving the boundary of the transactional service layer. While this will prevent the LazyInitializationException from being thrown, the performance price is considerable since every additional non-transactional Proxy initialization will require a new database connection, therefore putting pressure on the underlying connection pool. For more details about why you should always avoid the Open Session in View architecture design, check out this article.
Another variant of the OSIV anti-pattern is the Temporary Session anti-pattern, which is actually even worse than OSIV since not only it uses a new database connection for every new Proxy initialization, but it also requires opening a new Hibernate Session as well. For more details about this anti-pattern, check out this article.
Streaming pitfalls
While the Java 1.8 Stream support is very convenient for processing in-memory collection, this is not necessarily true for streaming data coming from a relational database system. JPA 2.2 even added a getResultStream on the javax.persistence.Query object which allows you to return a Stream instead of a List.
Behind the scenes, Hibernate has long supported ResultSet streaming via the scroll method of the org.hibernate.query.Query object which relies on JDBC ResultSet scrolling. However, scrolling is not as trivial as one might think.
First of all, not all JDBC drivers resort to scrolling when setting the fetchSize property on the underlying Statement or PrepareStatement object. For instance, in MySQL, to activate result set scrolling, you need to either set the Statement fetch size to Integer.MIN_VALUE or set it to a positive integer value while also setting the useCursorFetch connection property to true.
More, as explained in this article, a scrolling ResultSet perform worse than the default forward-only ResultSet.
More, as explained in this article, a scrolling query might not provide the maximum result set to the database, which, can cause the database to choose a full-table scan over an index scan even if the application requires a small number of records from the underlying ResultSet.
Optimizing the number of database roundtrips
Unlike database cursors or streams, Hibernate traverses the entire JDBC ResultSet and builds the list of entities or DTO objects. The number of roundtrips needed to fetch an entire ResultSet is given by the fetchSize property of the JDBC Statement or PreparedStatement objects.
When using PostgreSQL or MySQL, you don’t have to worry about the fetch size since the JDBC driver caches the entire result set up front, so there’s a single database roundtrip to materialize the result set and make it available to the application.
However, when using Oracle, the default fetch size is just 10, meaning that fetching 100 records requires 10 roundtrips. When using Hibernate, you can easily increase the fetch size of every PreparedStatement via the hibernate.jdbc.fetch_size configuration property. For more details about JDBC statement fetch size, check out this article.
Read-only queries
By default, all JPA and Hibernate entity queries execute in read-write mode, meaning that the returning entities are managed by the current Persistence Context, hence entity state modifications are going to be detected and translated to an UPDATE SQL statement.
However, you don’t want to modify the returning entities, it’s much better to fetch the entities in read-only mode. This will allows Hibernate to discard the associated detached state which is used by the dirty checking mechanism to detect entity state modifications. More, read-only entities are skipped during flushing.
To fetch entities in read-only mode you can do it either at the Session level as illustrated in the following example:
Session session = entityManager.unwrap(Session.class); session.setDefaultReadOnly(true);
or Query level:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
""", Post.class)
.setHint(QueryHints.HINT_READONLY, true)
.getResultList();
By fetching entities in read-only mode, you will reduce memory allocation as the detached state is no longer saved by the Persistence Context. Having fewer Java objects to discard, the read-only strategy is more efficient from the Garbage Collector perspective as well. So, this strategy saves more than just memory. It also saves CPU cycles which would be otherwise spent on collecting the detached state array objects after the current Persistence Context is closed.
Awesome collection of Hibernate performance tips with a ton of links to other related articles. Thanks @vlad_mihalcea! https://t.co/mKZNb2vfXk
— Vedran Pavić (@vedran_pavic) September 18, 2018
Statement caching
While statement caching is handled by the underlying JDBC Driver, the data access framework can also help improve the likelihood of a statement cache hit.
First of all. Hibernate executes all SQL queries and DML operations using prepared statements. Not only that prepared statements help to prevent SQL injection attacks, but they can help speed up query executions, especially when the underlying database provides an execution plan cache (e.g. Oracle, SQL Server).
Hibernate also offers the hibernate.query.in_clause_parameter_padding configuration property. For more details, check out this article.
Note that some JDBC Drivers emulate prepared statements even when using the JDBC
PreparedStatementobject. For more details, check out this article.
Another optimization added by Hibernate which helps reuse a given execution plan is the configurable Criteria API literal handling mode. Traditionally, numeric literals were inlined while String literals were provided as prepared statement bind parameters. With the hibernate.criteria.literal_handling_mode you can now choose to bind all literals, therefore increasing the likelihood of a statement cache hit. For more details about the Criteria literal handling mode, check out this article.
Statement batching
When it comes to batching, Hibernate offers multiple optimizations. First of all, the Persistence Context acts as a transactional write-behind cache. The write-behind cache allows Hibernate to delay the statement execution until the Session flush time, therefore giving the opportunity to group statements of the same type in batches.

When doing batch processing with Hibernate, it’s common knowledge that the Persistence Context needs to be flushed and cleared periodically, to avoid running out of memory and increase the flush time due to processing more and more entities on every flush call. However, what’s less obvious is that the database transaction is worth committing periodically as well, especially when processing large volumes of data. This can help you avoid long-running transactions, as well as losing all the work done just because of a single error towards the end of the batch. For more details about the best way to do batch processing with JPA and Hibernate, check out this article.
To enable JDBC batching, you only have to set the hibernate.jdbc.batch_size configuration property and Hibernate will automatically switch to using JDBC statement batching. This is very convenient since most applications are not written with batching in mind, and switching from non-batching to batching might require rewriting the entire data access layer in case the underlying framework offers a different API for when batching is to be used.
Besides the SessionFactory-level configuration property, you can also use a Session-level JDBC batch size, therefore choosing the right batch size on a per business use case. For more details, check out this article.
When batching INSERT and UPDATE statements, besides the hibernate.jdbc.batch_size configuration property, you should consider enabling the following two properties as well:
<property name="hibernate.order_inserts" value="true"/> <property name="hibernate.order_updates" value="true"/>
These two properties allow Hibernate to reorder statements so that statements of the same type are being batches instead of being interleaved with other statements. For more details, check out this article.
Although Hibernate 4 and 5 does not offer a possibility to order DELETE statements, you can work around this limitation as explained in this article.
Apart from all the Hibernate-specific batch optimizations, you can also take advantage of what the underlying JDBC driver has to offer. For instance, PostgreSQL allows you to group SQL statements using the reWriteBatchedInserts mode. For more details about this property, check out this article.
Connection management
The database connection acquisition is an expensive operation, and that’s why it’s a good idea to use a connection pooling technique. Hibernate offers multiple connection pooling integrations: Hikari, Vibur DBCP, c3p0.
However, the best way to integrate a pooling solution with Hibernate is to use an external DataSource and provide it via the hibernate.connection.datasource configuration property. This way, not only that you can use any connection pooling solution, but you can integrate a connection pooling monitoring solution, like FlexyPool.
Other than connection pooling, there two aspects you need to take into considerations when using Hibernate:
- connection acquisition
- connection release
For JTA transactions, connections are acquired lazily prior to executing a query or before flushing the Persistence Context. For RESOURCE_LOCAL transactions, the database connection is acquired right way when starting a JPA transaction because Hibernate needs to make sure that the auto-commit flag is disabled on the underlying JDBC Connection. If the connection pool already disables the auto-commit mode, then you can tell Hibernate to avoid acquiring the connection eagerly via the hibernate.connection.provider_disables_autocommit connection property. For more details, check out this article.
When it comes to releasing connections, a RESOURCE_LOCAL transaction will give back the connection to the pool after committing or rolling back the current running transaction. For JTA transactions, the connection is released after every statement, only to be acquired again prior to executing a new statement. Because this process might incur an additional overhead, it’s worth setting the hibernate.connection.release_mode connection property to after_transaction if the JTA transaction manager works properly in this mode. For more details, check out this article.
Logging
Although Hibernate can log SQL statements by setting the proper log appender, it’s much better to delegate this responsibility to a JDBC DataSource or Driver proxy solution with logging capabilities as explained in this article. Not only that you can log bind parameter values along the executing SQL statement, but you can print if batching is used as well as the statement execution time.
More, when using a tool like datasource-proxy, you can assert the number of statements Hibernate generates on your behalf, therefore preventing N+1 query issues during testing, long before they become a problem in production.
Mapping
When using JPA and Hibernate, you have to pay attention when mapping entities as this can impact application performance. As a rule of thumb, it’s important to use very compact columns on the database side to reduce disk and memory footprint.
For identifiers, the SEQUENCE generator performs the best, especially when used with the pooled or pooled-lo optimizers.
The IDENTITY generator, although a viable alternative from a database perspective, it makes Hibernate miss the opportunity of batching statements at flush time since, by the time Hibernate tries to group INSERT statements, the statements have already been executing in order for Hibernate to fetch the entity identifier.
The TABLE generator is the worst choice and should be avoided. If portability is the only reason you chose the TABLE generator, you are better off using SEQUENCE by default and override the identifier strategy at build time using the orm.xml JPA configuration file as explained in this article.
Pay attention to the
AUTOidentifier generator on MySQL and MariaDB prior to version 10.3 since it defaults to theTABLEgenerator which performs poorly and may lead to performance bottlenecks.
For association, a picture is worth 1000 words:
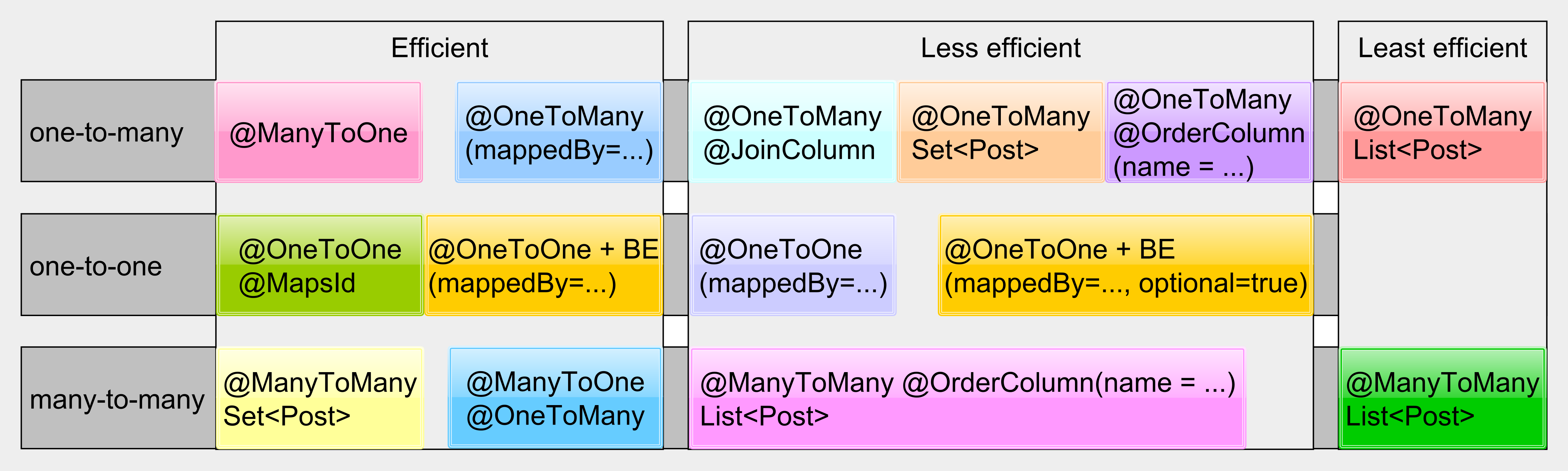
For more details check out the following articles:
- The best way to map a @OneToMany relationship with JPA and Hibernate
- The best way to map a @OneToOne relationship with JPA and Hibernate
- The best way to use the @ManyToMany annotation with JPA and Hibernate
- The best way to map a many-to-many association with extra columns when using JPA and Hibernate
Database-level processing
While Hibernate is suitable for OLTP use cases, if you want to process large volumes of data, it’s not worth moving all the data from the database, over the network into the JVM heap, only to do the processing in the application layer.
If you want to update or delete records that fit a given filtering logic, you are better off using a bulk statement. You can even vary the filtering logic of the bulk update or delete statement using Criteria API as explained in this article.
For more complex processing scenarios, you can use stored procedures as explained in the following articles:
- How to call Oracle stored procedures and functions with JPA and Hibernate
- How to call SQL Server stored procedures and functions with JPA and Hibernate
- How to call PostgreSQL functions (stored procedures) with JPA and Hibernate
- How to call MySQL stored procedures and functions with JPA and Hibernate
Another cold winter weekend. A perfect time to spend some time to sharpen our #Hibernate/#JPA #performance skills with @vlad_mihalcea. A must read that I recommend to all my trainees: https://t.co/Pi45ZUO6JM
— Victor Rentea (@VictorRentea) December 15, 2018
Caching
Although Hibernate provides a second-level cache, prior to deciding using it, you are better off configuring the database server properly so that the buffer pool or shared buffers can store the working set in memory and, therefore, avoiding loading too many data pages from the disk.
Also, if your application takes read traffic mostly, then database replication is a very efficient way to accommodate more incoming traffic load.
On the other hand, the second-level cache can be a good approach to off-load the Primary node even when using database replication.
For more details about how to use the Hibernate 2nd-level cache, check out these articles:
- How does Hibernate store second-level cache entries
- How does Hibernate READ_ONLY CacheConcurrencyStrategy work
- How does Hibernate NONSTRICT_READ_WRITE CacheConcurrencyStrategy work
- How does Hibernate READ_WRITE CacheConcurrencyStrategy work
- How does Hibernate TRANSACTIONAL CacheConcurrencyStrategy work
- How does Hibernate Collection Cache work
- How does Hibernate Query Cache work
- How to use the Hibernate Query Cache for DTO projections
- How to avoid the Hibernate Query Cache N+1 issue
- How to cache non-existing entity fetch results with JPA and Hibernate
Query plan cache
Another lesser-known topic when configuring Hibernate is the query plan cache. All entity queries (e.g. JPQL or Criteria API) need to be parsed in order to generate the proper SQL statement. This processes of parsing an entity query take time, so Hibernate offers a plan cache to reuse already computed plan.
If your application generates many queries, it’s important to configure the query plan cache properly. For more details, check this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
If you’re using JPA and Hibernate, there are many things you can do to speed up your data access layer. By following the tips provided in this article, you are going to get a better understanding of how Hibernate works so that you can design your application to get the most out of the underlying database, JDBC driver, and JPA implementation.









