How does Hibernate store second-level cache entries
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
The benefit of using a database access abstraction layer is that caching can be implemented transparently, without leaking into the business logic code. Hibernate Persistence Context acts as a transactional write-behind cache, translating entity state transitions into DML statements.
The Persistence Context acts as a logical transaction storage, and each Entity instance can have at-most one managed reference. No matter how many times we try to load the same Entity, the Hibernate Session will always return the same object reference. This behavior is generally depicted as the first-level cache.
The Hibernate Persistence Context is not a caching solution per se, serving a different purpose than boosting application read operation performance. Because the Hibernate Session is bound to the currently running logical transaction, once the transaction is over, the Session is being destroyed.
The second-level cache
A proper caching solution would have to span across multiple Hibernate Sessions and that’s the reason Hibernate supports an additional second-level cache as well. The second-level cache is bound to the SessionFactory life-cycle, so it’s destroyed only when the SessionFactory is closed (typically when the application is shutting down). The second-level cache is primarily entity-based oriented, although it supports an optional query-caching solution as well.
By default, the second-level cache is enabled so you don’t need to activate it. However, if you want to explicitly enable it, you need to set the following Hibernate configuration property:
<property
name="hibernate.cache.use_second_level_cache"
value="true"
/>
However, enabling the second level cache is not sufficient because, by default, the NoCachingRegionFactory is used, hence the second-level calls are simply discarded.
For this reason, you need to configure a proper third-party RegionFactory, like Ehcacahe or Infinispan:
<property
name="hibernate.cache.region.factory_class"
value="org.hibernate.cache.ehcache.EhCacheRegionFactory"
/>
The RegionFactory defines the second-level cache implementation provider, and the hibernate.cache.region.factory_class configuration is mandatory, once the hibernate.cache.use_second_level_cache property is set to true.
To enable entity-level caching, we need to annotate our cacheable entities as follows:
@Entity
@org.hibernate.annotations.Cache(usage =
CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
JPA also defines the @Cacheable annotation, but it doesn’t support setting the concurrency strategy on entity-level.
The entity loading flow
Whenever an entity is to be loaded, a LoadEevent is fired and the DefaultLoadEventListener handles it as follows:
Object entity = loadFromSessionCache( event,
keyToLoad, options );
if ( entity == REMOVED_ENTITY_MARKER ) {
LOG.debug("Load request found matching entity
in context, but it is scheduled for removal;
returning null" );
return null;
}
if ( entity == INCONSISTENT_RTN_CLASS_MARKER ) {
LOG.debug("Load request found matching entity
in context, but the matched entity was of
an inconsistent return type;
returning null"
);
return null;
}
if ( entity != null ) {
if ( traceEnabled ) {
LOG.tracev("Resolved object in "
+ "session cache: {0}",
MessageHelper.infoString( persister,
event.getEntityId(),
event.getSession().getFactory() )
);
}
return entity;
}
entity = loadFromSecondLevelCache( event,
persister, options );
if ( entity != null ) {
if ( traceEnabled ) {
LOG.tracev("Resolved object in "
+ "second-level cache: {0}",
MessageHelper.infoString( persister,
event.getEntityId(),
event.getSession().getFactory() )
);
}
}
else {
if ( traceEnabled ) {
LOG.tracev("Object not resolved in "
+ "any cache: {0}",
MessageHelper.infoString( persister,
event.getEntityId(),
event.getSession().getFactory() )
);
}
entity = loadFromDatasource( event, persister,
keyToLoad, options );
}
The Session is always inspected first because it might already contain a managed entity instance. The second-level cache is verified before hitting the database, so its main purpose is to reduce the number of database accesses.
Second-level cache internals
Every entity is stored as a CacheEntry, and the entity hydrated state is used for creating the cache entry value.
Hydration
In Hibernate nomenclature, hydration is when a JDBC ResultSet is transformed to an array of raw values:
final Object[] values = persister.hydrate(
rs, id, object,
rootPersister, cols, eagerPropertyFetch, session
);
The hydrated state is saved in the currently running Persistence Context as an EntityEntry object, which encapsulated the loading-time entity snapshot. The hydrated state is then used by:
- the default dirty checking mechanism, which compares the current entity data against the loading-time snapshot
- the second-level cache, whose cache entries are built from the loading-time entity snapshot
The inverse operation is called dehydration and it copies the entity state into an INSERT or UPDATE statement.
The second-level cache elements
Although Hibernate allows us to manipulate entity graphs, the second-level cache uses a disassembled hydrated state instead:
final CacheEntry entry = persister.buildCacheEntry(
entity, hydratedState, version, session );
The hydrated state is disassembled prior to being stored in the CacheEntry:
this.disassembledState = TypeHelper.disassemble(
state, persister.getPropertyTypes(),
persister.isLazyPropertiesCacheable()
? null : persister.getPropertyLaziness(),
session, owner
);
Starting from the following entity model diagram:
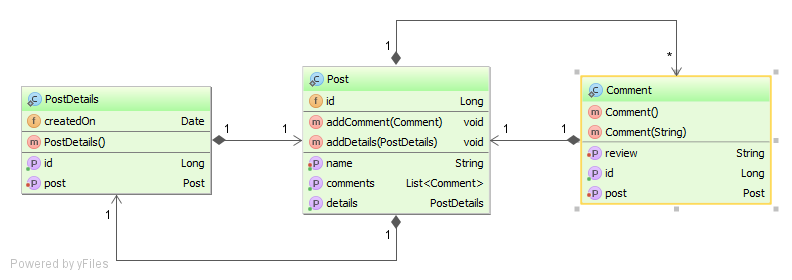
We’ll insert the following entities:
Post post = new Post();
post.setName("Hibernate Master Class");
post.addDetails(new PostDetails());
post.addComment(new Comment("Good post!"));
post.addComment(new Comment("Nice post!"));
session.persist(post);
Now, we are going to check each individual entity cache element.
The Post entity cache element
The Post entity has a one-to-many association to the Comment entity and an inverse one-to-one association to a PostDetails:
@OneToMany(cascade = CascadeType.ALL,
mappedBy = "post")
private List<Comment> comments = new ArrayList<>();
@OneToOne(cascade = CascadeType.ALL,
mappedBy = "post", optional = true)
private PostDetails details;
When fetching a Post entity:
Post post = (Post) session.get(Post.class, 1L);
The associated cache element looks like this:
key = {org.hibernate.cache.spi.CacheKey@3855}
key = {java.lang.Long@3860} "1"
type = {org.hibernate.type.LongType@3861}
entityOrRoleName = {java.lang.String@3862} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$Post"
tenantId = null
hashCode = 31
value = {org.hibernate.cache.spi.entry.StandardCacheEntryImpl@3856}
disassembledState = {java.io.Serializable[3]@3864}
0 = {java.lang.Long@3860} "1"
1 = {java.lang.String@3865} "Hibernate Master Class"
subclass = {java.lang.String@3862} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$Post"
lazyPropertiesAreUnfetched = false
version = null
The CacheKey contains the entity identifier and the CacheEntry contains the entity disassembled hydrated state.
The Post entry cache value consists of the name column and the id, which is set by the one-to-many Comment association.
Neither the one-to-many nor the inverse one-to-one associations are embedded in the Post CacheEntry.
The PostDetails entity cache element
The PostDetails entity Primary Key is referencing the associated Post entity Primary Key, and it therefore has a one-to-one association with the Post entity.
@OneToOne @MapsId private Post post;
When fetching a PostDetails entity:
PostDetails postDetails =
(PostDetails) session.get(PostDetails.class, 1L);
The second-level cache generate the following cache element:
key = {org.hibernate.cache.spi.CacheKey@3927}
key = {java.lang.Long@3897} "1"
type = {org.hibernate.type.LongType@3898}
entityOrRoleName = {java.lang.String@3932} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$PostDetails"
tenantId = null
hashCode = 31
value = {org.hibernate.cache.spi.entry.StandardCacheEntryImpl@3928}
disassembledState = {java.io.Serializable[2]@3933}
0 = {java.sql.Timestamp@3935} "2015-04-06 15:36:13.626"
subclass = {java.lang.String@3932} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$PostDetails"
lazyPropertiesAreUnfetched = false
version = null
The disassembled state contains only the createdOn entity property, since the entity identifier is embedded in the CacheKey.
The Comment entity cache element
The Comment entity has a many-to-one association to a Post:
@ManyToOne private Post post;
When we fetch a Comment entity:
Comment comments =
(Comment) session.get(Comment.class, 1L);
Hibernate generates the following second-level cache element:
key = {org.hibernate.cache.spi.CacheKey@3857}
key = {java.lang.Long@3864} "2"
type = {org.hibernate.type.LongType@3865}
entityOrRoleName = {java.lang.String@3863} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$Comment"
tenantId = null
hashCode = 62
value = {org.hibernate.cache.spi.entry.StandardCacheEntryImpl@3858}
disassembledState = {java.io.Serializable[2]@3862}
0 = {java.lang.Long@3867} "1"
1 = {java.lang.String@3868} "Good post!"
subclass = {java.lang.String@3863} "com.vladmihalcea.hibernate.masterclass.laboratory.cache.SecondLevelCacheTest$Comment"
lazyPropertiesAreUnfetched = false
version = null
The disassembled state contains the Post.id Foreign Key reference and the review column, therefore mirroring the associated database table definition.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The second-level cache is a relational data cache, so it stores data in a normalized form, and each entity update affects only one cache entry. Reading a whole entity graph is not possible since the entity associations are not materialized in the second-level cache entries.
An aggregated entity graph yields better performance for read operations at the cost of complicating write operations. If the cached data is not normalized and scattered across various aggregated models, an entity update would have to modify multiple cache entries, therefore, affecting the write operations performance.
Because it mirrors the underlying relation data, the second-level cache offers various concurrency strategy mechanisms so we can balance read performance and strong consistency guarantees.









