Things to consider before jumping to application-level caching
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
Relational database transactions are ACID and the strong consistency model simplifies application development. Because enabling Hibernate caching is one configuration away, it’s very appealing to turn to caching whenever the data access layer starts showing performance issues. Adding a caching layer can indeed improve application performance, but it has its price and you need to be aware of it.
Database performance tuning
The database is, therefore, the central part of any enterprise application, containing valuable business assets. A database server has limited resources and it can, therefore, serve a finite number of connections. The shorter the database transactions, the more transactions can be accommodated. The first performance tuning action is to reduce query execution times by indexing properly and optimizing queries.
When all queries and statements are optimized, we can either add more resources (scale up) or add more database nodes (scale-out). Horizontal scaling requires database replication, which implies synchronizing nodes. Synchronous replication preserves strong consistency, while asynchronous single-primary replication leads to eventual consistency.
Analogous to database replication challenges, cache nodes induce data synchronization issues, especially for distributed enterprise applications.
Caching
Even if the database access patterns are properly optimized, higher loads might increase latency. To provide predictable and constant response times, we need to turn to caching. Caching allows us to reuse a database response for multiple user requests.
The cache can therefore:
- reduce CPU/Memory/IO resource consumption on the database side
- reduce network traffic between application nodes and the database tier
- provide constant result fetch time, insensitive to traffic bursts
- provide a read-only view when the application is in maintenance mode (e.g. when upgrading the database schema)
The downside of introducing a caching solution is that data is duplicated in two separate technologies that may easily desynchronize.
In the simplest use case you have one database server and one cache node:
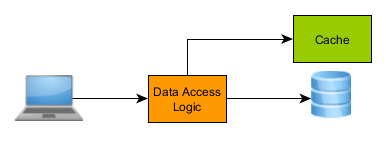
The caching abstraction layer is aware of the database server, but the database knows nothing of the application-level cache. If some external process updates the database without touching the cache, the two data sources will get out of sync. Because few database servers support application-level notifications, the cache may break the strong consistency guarantees.
To avoid eventual consistency, both the database and the cache need to be enrolled in a distributed XA transaction, so the affected cache entries are either updated or invalidated synchronously.
Most often, there are more application nodes or multiple distinct applications (web-fronts, batch processors, schedulers) comprising the whole enterprise system:

If each node has its own isolated cache node, we need to be aware of possible data synchronization issues. If one node updates the database and its own cache without notifying the rest, then other cache nodes get out of sync.
In a distributed environment, when multiple applications or application nodes use caching, we need to use a distributed caching solution, so that:
- cache nodes communicate in a peer-to-peer topology
- cache nodes communicate in a client-server topology and a central cache server takes care of data synchronization

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Caching is a fine scaling technique but you have to be aware of possible consistency issues. Taking into consideration your current project data integrity requirements, you need to design your application to take advantage of caching without compromising critical data.
Caching is not a cross-cutting concern, leaking into your application architecture and requiring a well-thought plan for compensating data integrity anomalies.








