A beginner’s guide to Cache synchronization strategies
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
A system of record is the authoritative data source when information is scattered among various data providers. When we introduce a caching solution, we automatically duplicate our data. To avoid inconsistent reads and data integrity issues, it’s very important to synchronize the database and the cache (whenever a change occurs in the system).
There are various ways to keep the cache and the underlying database in sync and this article will present some of the most common cache synchronization strategies.
Cache-aside
The application code can manually manage both the database and the cache information. The application logic inspects the cache before hitting the database and it updates the cache after any database modification.
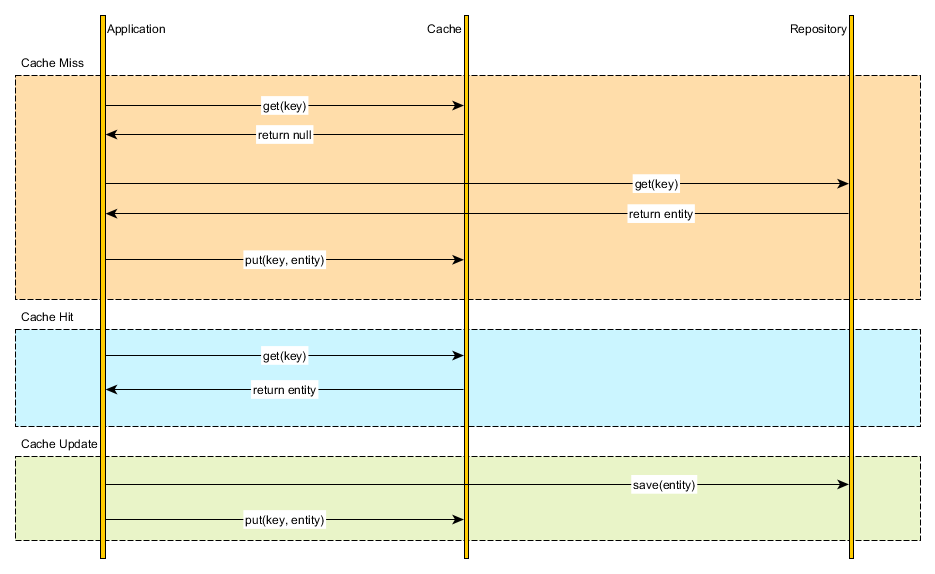
Mixing caching management and application is not very appealing, especially if we have to repeat these steps in every data retrieval method. Leveraging an Aspect-Oriented caching interceptor can mitigate the cache leaking into the application code, but it doesn’t exonerate us from making sure that both the database and the cache are properly synchronized.
Read-through
Instead of managing both the database and the cache, we can simply delegate the database synchronization to the cache provider. All data interaction is, therefore, done through the cache abstraction layer.
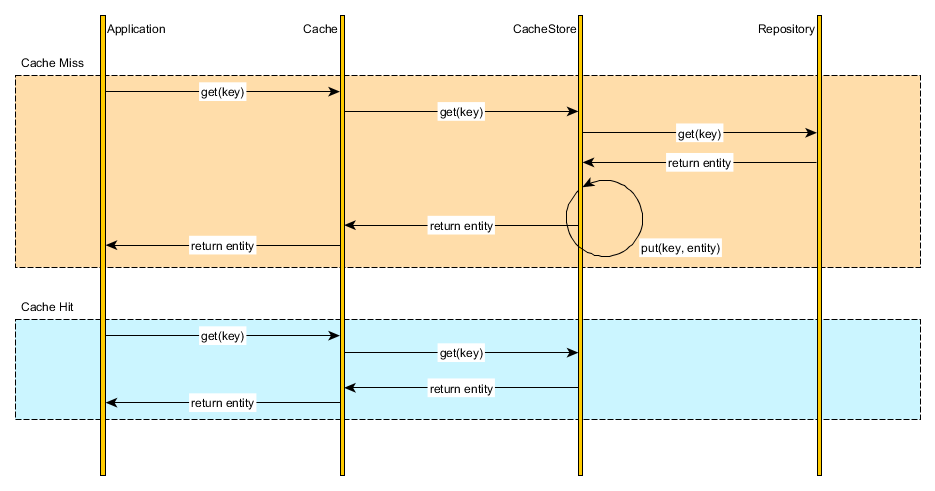
Upon fetching a cache entry, the Cache verifies the cached element availability and loads the underlying resource on our behalf. The application uses the cache as the system of record and the cache is able to auto-populate on demand.
Write-through
Analogous to the read-through data fetching strategy, the cache can update the underlying database every time a cache entry is changed.

Although the database and the cache are updated synchronously, we have the liberty of choosing the transaction boundaries according to our current business requirements.
- If strong consistency is mandatory and the cache provider offers an XAResource we can then enlist the cache and the database in the same global transaction. The database and the cache are therefore updated in a single atomic unit-of-work
- If consistency can be weaken, we can update the cache and the database sequentially, without using a global transaction. Usually the cache is changed first and if the database update fails, the cache can use a compensating action to roll-back the current transaction changes
Write-behind caching
To speed up the write operations, we can simply enqueue the cache changes and periodically flush them to the database.

This strategy is employed by the Java Persistence EntityManager (first-level cache), all entity state transitions being flushed towards the end of the current running transaction (or when a query is issued).
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



To guarantee strong consistency, the buffer must be flushed prior to executing any query or read operation.
The advantage of the write-behind caching strategy is that we can batch the database DML statements, therefore improving transaction response time.








