Hibernate pooled and pooled-lo identifier generators
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this post, we’ll uncover a sequence identifier generator combining identifier assignment efficiency and interoperability with other external systems (concurrently accessing the underlying database system).
Traditionally there have been two sequence identifier strategies to choose from: sequence and seqhilo.
The sequence identifier, always hitting the database for every new value assignment. Even with database sequence preallocation, we have a significant database round-trip cost.
The seqhilo identifier, using the hilo algorithm. This generator calculates some identifier values in-memory, therefore reducing the database round-trip calls. The problem with this optimization technique is that the current database sequence value no longer reflects the current highest in-memory generated value.
The database sequence is used as a bucket number, making it difficult for other systems to interoperate with the database table in question. Other applications must know the inner-workings of the hilo identifier strategy to properly generate non-clashing identifiers.
The enhanced identifiers
Hibernate offers a new class of identifier generators, addressing many shortcomings of the original hilo optimizer.
The new optimization strategy is configurable and we can even supply our own optimization implementation. By default, Hibernate comes with the following built-in optimizers:
nonecauses every identifier to be fetched from the database, so it’s equivalent to the original sequence generator.hilouses the hilo algorithm and it’s equivalent to the original seqhilo generator.pooleduses a hilo-like optimization strategy, but the current in-memory identifiers highest boundary is extracted from an actual database sequence value.pooled-lois similar to thepooledoptimizer but the database sequence value is used as the current in-memory lowest boundary.
The major advantage of the pooled optimizers is that they are interoperable with other external systems, and this is actually what we are looking for, an identifier generator that’s both efficient and doesn’t clash when other external systems are concurrently inserting rows into the same database tables.
The pooled optimizer
The pooled optimizer works as illustrated by the following diagram.
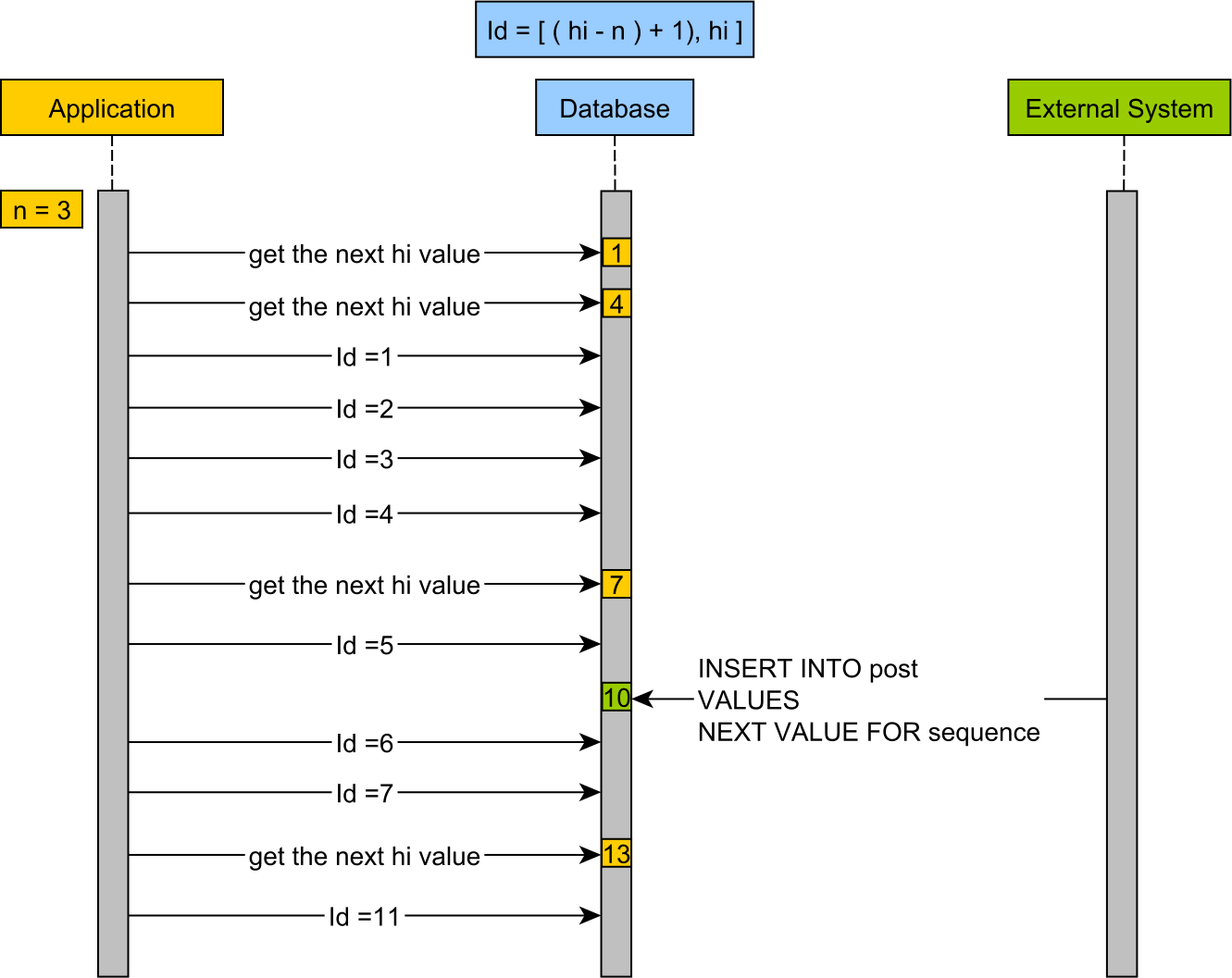
As you can see, even if we have an external client inserting a row using a new database sequence value, this will not conflict with our application.
To use the pooled optimizer, the entity identifier mapping looks as follows:
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "post_sequence"
)
@SequenceGenerator(
name = "post_sequence",
sequenceName = "post_sequence",
allocationSize = 3
)
private Long id;
The pooled-lo optimizer
The pooled-lo optimizer is similar to pooled, the only difference being that the database sequence value is used as the lower boundary of the identifier values generated by the application.
To understand how the pooled-lo works, check out this diagram:
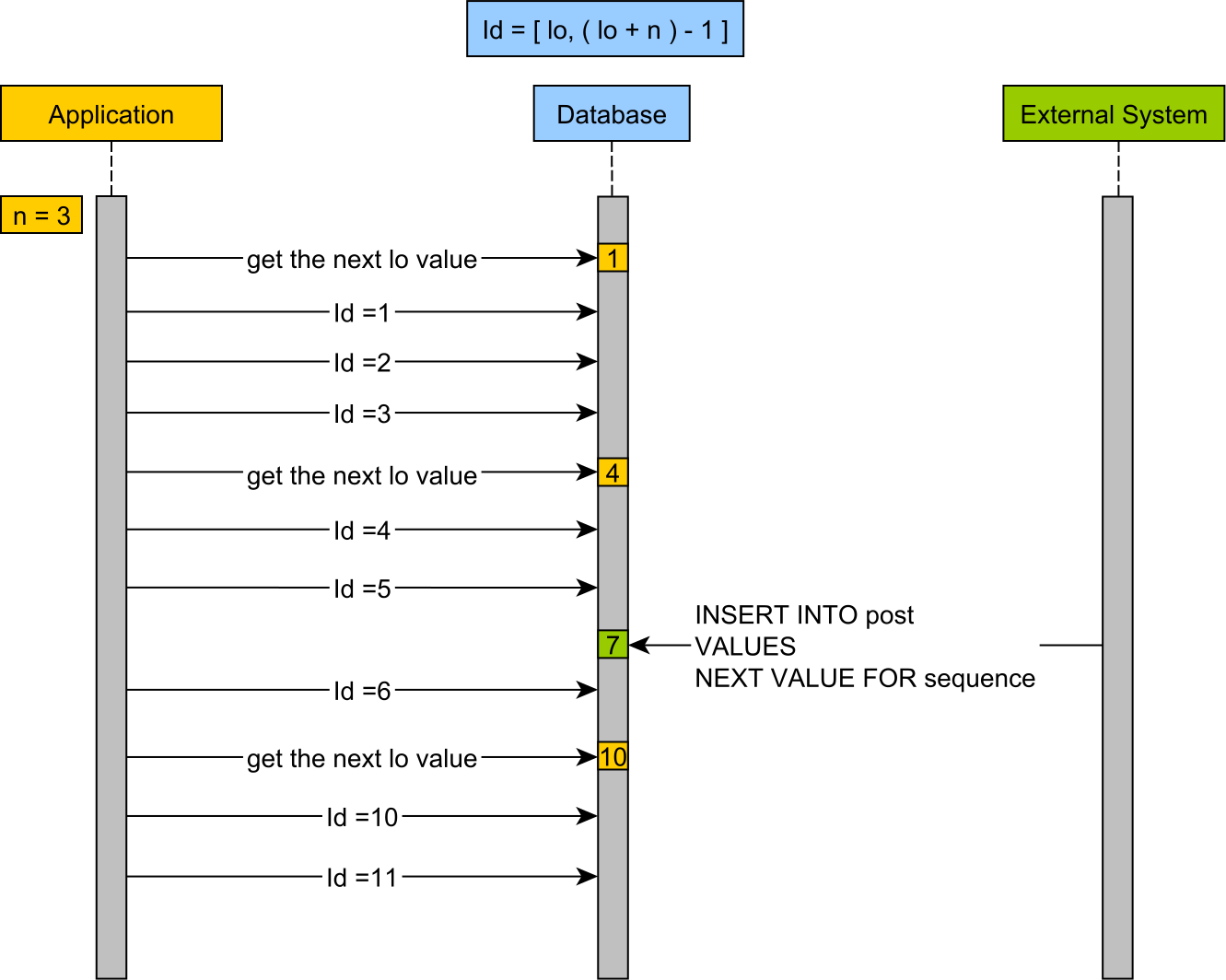
To use the pooled-lo optimizer, the entity identifier mapping will look as follows:
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "pooled-lo"
)
@GenericGenerator(
name = "pooled-lo",
strategy = "sequence",
parameters = {
@Parameter(name = "sequence_name", value = "post_sequence"),
@Parameter(name = "initial_value", value = "1"),
@Parameter(name = "increment_size", value = "3"),
@Parameter(name = "optimizer", value = "pooled-lo")
}
)
Unlike pooled, the pooled-lo mapping is more verbose as we need to use the @GenericGenerator to pass the optimizer parameter, as the JPA @SequenceGenerator doesn’t offer this option. The more-compact @SequenceGenerator is only useful for the pooled generator as Hibernate chooses to use that one by default if the allocationSize attribute is greater than 1.
Since the @SequenceGenerator mapping is more straightforward than using the Hibernate-specific @GenericGenerator, you can switch to pooled-lo instead of the default pooled optimizer if you provide this Hibernate configuration property:
<property name="hibernate.id.optimizer.pooled.preferred" value="pooled-lo" />
With this property set, you can use the @SequenceGenerator mapping and Hibernate is going to use pooled-lo instead of pooled:
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "post_sequence"
)
@SequenceGenerator(
name = "post_sequence",
sequenceName = "post_sequence",
allocationSize = 3
)
private Long id;
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Awesome, right?
Conclusion
The pooled and pooled-lo optimizers are extremely useful, yet not all developers know of their existence. If you have previously used the hilo generator, you might want to switch to pooled or pooled-lo. Check out this article more a step-by-step guide of how you can migrate from hilo to the pooled optimizer.







