The best way to map a @OneToOne relationship with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to learn the best way to map a OneToOne association with JPA and Hibernate.
While there are many ways you can map a one-to-one relationship with Hibernate, I’m going to demonstrate which mapping is the most efficient one from a database perspective.
Great article ! The best way to map a OneToOne relationship with JPA and Hibernate https://t.co/p7TPsGoUxi via @vlad_mihalcea
— Martin Jeannot (@m4rtinjeannot) November 21, 2017
Domain Model
For the following examples, I’m going to use the following Post and PostDetails classes:
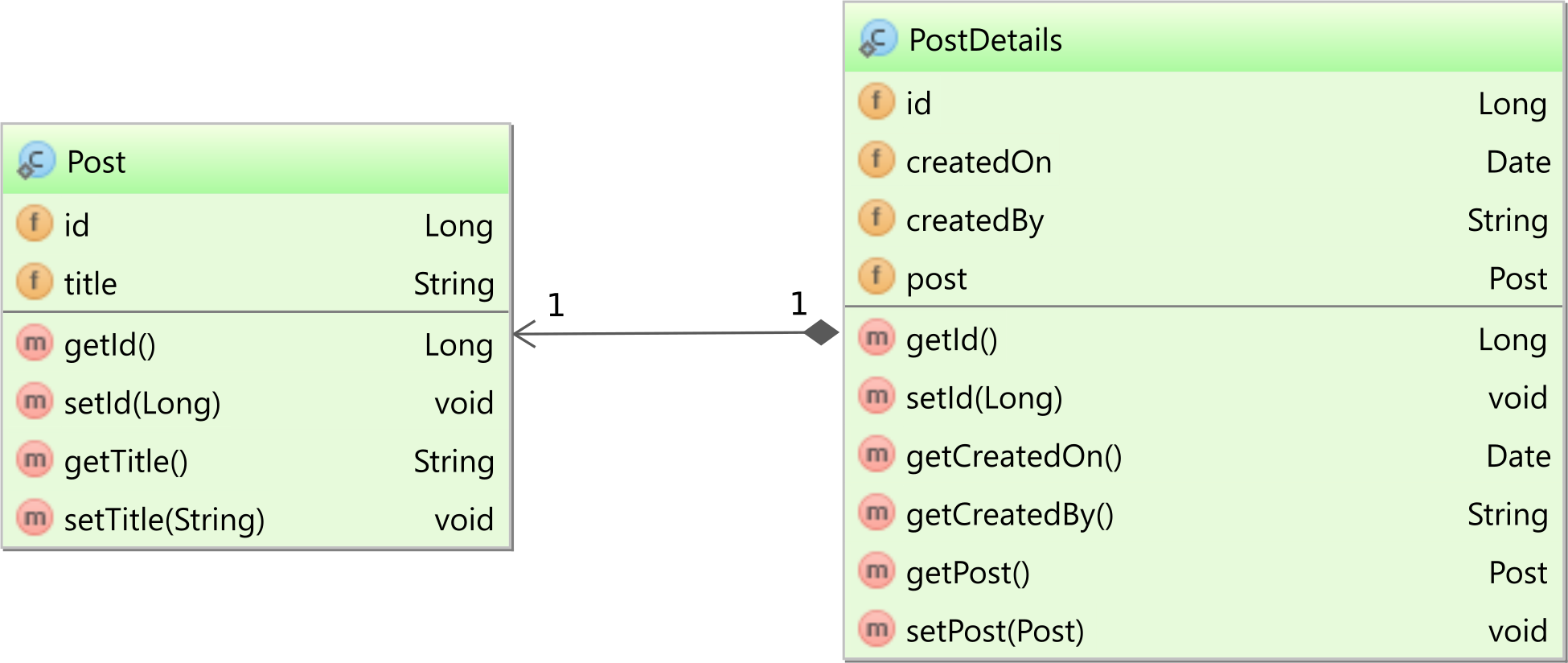
The Post entity is the parent, while the PostDetails is the child association because the Foreign Key is located in the post_details database table.
Typical mapping
Most often, this relationship is mapped as follows:
@Entity(name = "PostDetails")
@Table(name = "post_details")
public class PostDetails {
@Id
@GeneratedValue
private Long id;
@Column(name = "created_on")
private Date createdOn;
@Column(name = "created_by")
private String createdBy;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id")
private Post post;
public PostDetails() {}
public PostDetails(String createdBy) {
createdOn = new Date();
this.createdBy = createdBy;
}
//Getters and setters omitted for brevity
}
More, even the Post entity can have a PostDetails mapping as well:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
@Id
@GeneratedValue
private Long id;
private String title;
@OneToOne(mappedBy = "post", cascade = CascadeType.ALL,
fetch = FetchType.LAZY, optional = false)
private PostDetails details;
//Getters and setters omitted for brevity
public void setDetails(PostDetails details) {
if (details == null) {
if (this.details != null) {
this.details.setPost(null);
}
}
else {
details.setPost(this);
}
this.details = details;
}
}
However, this mapping is not the most efficient, as further demonstrated.
The post_details table contains a Primary Key (PK) column (e.g. id) and a Foreign Key (FK) column (e.g. post_id).

However, there can be only one post_details row associated with a post, so it makes more sense to have the post_details PK mirroring the post PK.

This way, the post_details Primary Key is also a Foreign Key, and the two tables are sharing their PKs as well.
PK and FK columns are most often indexed, so sharing the PK can reduce the index footprint by half, which is desirable since you want to store all your indexes into memory to speed up index scanning.
While the unidirectional @OneToOne association can be fetched lazily, the parent-side of a bidirectional @OneToOne association is not. Even when specifying that the association is not optional and we have the FetchType.LAZY, the parent-side association behaves like a FetchType.EAGER relationship. And EAGER fetching is bad.
This can be easily demonstrated by simply fetching the Post entity:
Post post = entityManager.find(Post.class, 1L);
Hibernate fetches the child entity as well, so, instead of only one query, Hibernate requires two select statements:
SELECT p.id AS id1_0_0_, p.title AS title2_0_0_
FROM post p
WHERE p.id = 1
SELECT pd.post_id AS post_id3_1_0_, pd.created_by AS created_1_1_0_,
pd.created_on AS created_2_1_0_
FROM post_details pd
WHERE pd.post_id = 1
Even if the FK is NOT NULL and the parent-side is aware about its non-nullability through the optional attribute (e.g. @OneToOne(mappedBy = "post", fetch = FetchType.LAZY, optional = false)), Hibernate still generates a secondary select statement.
For every managed entity, the Persistence Context requires both the entity type and the identifier,
so the child identifier must be known when loading the parent entity, and the only way to find the associated post_details primary key is to execute a secondary query.
Bytecode enhancement is the only viable workaround. However, it only works if the parent side is annotated with
@LazyToOne(LazyToOneOption.NO_PROXY).For more details about this topic, check out this article.
YouTube Video
I also published a YouTube video about the Bidirectional @OneToMany association, so enjoy watching it if you’re interested in this topic.
The most efficient mapping
The best way to map a @OneToOne relationship is to use @MapsId. This way, you don’t even need a bidirectional association since you can always fetch the PostDetails entity by using the Post entity identifier.
The mapping looks like this:
@Entity(name = "PostDetails")
@Table(name = "post_details")
public class PostDetails {
@Id
private Long id;
@Column(name = "created_on")
private Date createdOn;
@Column(name = "created_by")
private String createdBy;
@OneToOne(fetch = FetchType.LAZY)
@MapsId
private Post post;
public PostDetails() {}
public PostDetails(String createdBy) {
createdOn = new Date();
this.createdBy = createdBy;
}
//Getters and setters omitted for brevity
}
This way, the id property serves as both Primary Key and Foreign Key. You’ll notice that the @Id column no longer uses a @GeneratedValue annotation since the identifier is populated with the identifier of the post association.
If you want to customize the Primary Key column name when using
@MapsId, you need to use the@JoinColumnannotation. For more details, check out this article.
The PostDetails entity can be persisted as follows:
doInJPA(entityManager -> {
Post post = entityManager.find(Post.class, 1L);
PostDetails details = new PostDetails("John Doe");
details.setPost(post);
entityManager.persist(details);
});
And we can even fetch the PostDetails using the Post entity identifier, so there is no need for a bidirectional association:
PostDetails details = entityManager.find(
PostDetails.class,
post.getId()
);
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Knowing how to map entity relationships efficiently can make a lot of difference when it comes to application performance. When using JPA and Hibernate, the OneToOne association should always share the Primary Key with the parent table.
And, unless you are using bytecode enhancement, you should avoid the bidirectional association.
Code available on GitHub.









You are a lifesaver, man.
I REALLY appreciate your post.
Gabriel Cerioni,
Redis