PostgreSQL reWriteBatchedInserts configuration property
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
The PostgreSQL JDBC Driver has been adding a lot of very useful optimizations, and one of the lesser-known ones is the reWriteBatchedInserts configuration property.
In this article, you will see how the reWriteBatchedInserts JDBC configuration property works in PostgreSQL, and how it allows you to rewrite INSERT statements into a multi-VALUE INSERT.
Default PostgreSQL batching behavior
Assuming we have the following Post entity:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
@Id
@GeneratedValue(
strategy = GenerationType.SEQUENCE
)
private Long id;
private String title;
public Post() {}
public Post(String title) {
this.title = title;
}
//Getters and setters omitted for brevity
}
As I explained in this article, to enable JDBC batching, we need to set the following Hibernate configuration property:
spring.jpa.properties.hibernate.jdbc.batch_size=10
When persisting 10 Post entities:
for (int i = 0; i < 10; i++) {
entityManager.persist(
new Post(
String.format("Post no. %d", i + 1)
)
);
}
Hibernate will execute the following SQL INSERT statement:
Query: ["insert into post (title, id) values (?, ?)"],
Params:[(Post no. 1, 1), (Post no. 2, 2), (Post no. 3, 3),
(Post no. 4, 4), (Post no. 5, 5), (Post no. 6, 6),
(Post no. 7, 7), (Post no. 8, 8), (Post no. 9, 9),
(Post no. 10, 10)
]
This is a JDBC-level log taken by datasource-proxy, but to be really sure what happens behind the scenes we need to activate the PostgreSQL log as well. For this, we need to open the postgresql.conf file and set the log_statements property to all:
log_statement = 'all'
Upon inspecting the PostgreSQL log, we can see that, although there was a single database roundtrip, the database server has to process each EXECUTE call individually, and that can take time:
LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 1', $2 = '1' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 2', $2 = '2' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 3', $2 = '3' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 4', $2 = '4' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 5', $2 = '5' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 6', $2 = '6' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 7', $2 = '7' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 8', $2 = '8' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 9', $2 = '9' LOG: execute S_2: insert into post (title, id) values ($1, $2) DETAIL: parameters: $1 = 'Post no. 10', $2 = '10'
Activating reWriteBatchedInserts
Now, let’s activate the PostgreSQL reWriteBatchedInserts configuration and rerun our test case. To set the reWriteBatchedInserts property, we can use the PGSimpleDataSource as follows:
PGSimpleDataSource dataSource =
(PGSimpleDataSource) super.dataSource();
dataSource.setReWriteBatchedInserts(true);
Now, when rerunning our test case that inserts 10 post records, PostgreSQL logs the following entries:
LOG: execute <unnamed>: insert into post (title, id) values ($1, $2),($3, $4),($5, $6),($7, $8),($9, $10),($11, $12),($13, $14),($15, $16) DETAIL: parameters: $1 = 'Post no. 1', $2 = '1', $3 = 'Post no. 2', $4 = '2', $5 = 'Post no. 3', $6 = '3', $7 = 'Post no. 4', $8 = '4', $9 = 'Post no. 5', $10 = '5', $11 = 'Post no. 6', $12 = '6', $13 = 'Post no. 7', $14 = '7', $15 = 'Post no. 8', $16 = '8' LOG: execute <unnamed>: insert into post (title, id) values ($1, $2),($3, $4) DETAIL: parameters: $1 = 'Post no. 9', $2 = '9', $3 = 'Post no. 10', $4 = '10'
This time, we only have 2 executions instead of 10, which can speed up the batch processing on the database side.
In this StackOverflow answer, Vladimir has given another reason why you should consider the setting. If the batch is fairly large, the PostgreSQL driver will split it into smaller ones to address TCP deadlock issues.
Testing Time
When running a test that inserts 5000 post records using a batch size of 100 for a duration of 60 seconds, we get the following results:
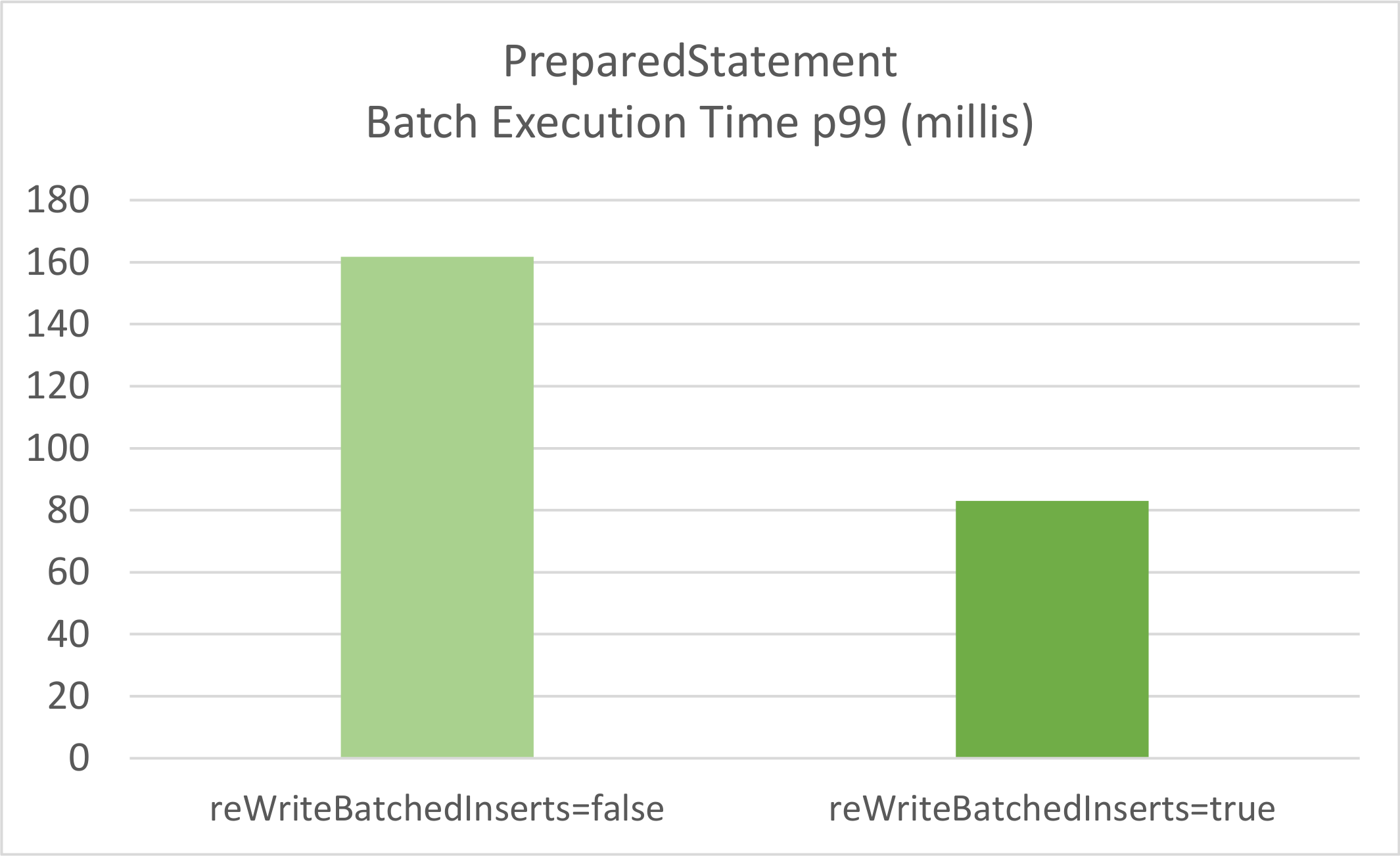
And here are the Dropwizard Metrics for both scenarios:
Test PostgreSQL batch insert with reWriteBatchedInserts=false type=TIMER, name=batchInsertTimer, count=333, min=71.5937, max=325.14279999999997, mean=91.34904044301564, stddev=22.316325243052066, median=83.9949, p75=95.10539999999999, p95=129.6009, p98=143.3825, p99=161.7466, p999=325.14279999999997, mean_rate=5.238711880855167, m1=3.758268697646252, m5=1.6133255862424578, m15=1.0870828419425205, rate_unit=events/second, duration_unit=milliseconds Test PostgreSQL batch insert with reWriteBatchedInserts=true type=TIMER, name=batchInsertTimer, count=421, min=39.052, max=86.5551, mean=51.55079159218259, stddev=9.83495820324783, median=48.783899999999996, p75=55.518699999999995, p95=73.2745, p98=79.12519999999999, p99=83.01989999999999, p999=86.5551, mean_rate=6.951990342367673, m1=6.7641359611940555, m5=6.500792095013239, m15=6.435603976938309, rate_unit=events/second, duration_unit=milliseconds
Clearly, the PostgreSQL reWriteBatchedInserts setting provides an advantage as the total batch execution time is way shorter when activating this property.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The PostgreSQL reWriteBatchedInserts configuration property was added in the PostgreSQL JDBC version 9.4.1209, so if you are still using the same JDBC Driver version set up when your project was started, you might want to consider upgrading it if you want to speed up batch inserts.
For more details about this configuration property and some benchmarks Vladimir run, check out this GitHub issue.








