9 High-Performance Tips when using PostgreSQL with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
To get the most out of the relational database in use, you need to make sure the data access layer resonates with the underlying database system.
In this article, we are going to see what you can do to boost up performance when using PostgreSQL with JPA and Hibernate.
How does MVCC (MultiVersion Concurrency Control) work
The first thing you need to take into consideration is how PostgreSQL works behind the scenes. Knowing its inner workings can make a difference between an application that barely crawls and one which runs at warp speed.
Behind the scenes, PostgreSQL uses MVCC (Multi-Version Concurrency Control) to manage concurrent access to table rows and indexes. For instance, the UPDATE operation consists of soft-deleting the previous record and inserting a new one, as illustrated by the following diagram:

Having multiple versions of the same tuple allows other transactions to see the previous entity version until the current modifying transaction manages to commit. Rollback is a rather cheap operation since it’s a matter of deleting the uncommitted records.
Thanks to MVCC, readers don’t block writers, and writers don’t block readers. For more details, check out this article.
Shared buffers and OS cache
Like any relational database system, PostgreSQL is designed to minimize disk access as much as possible.
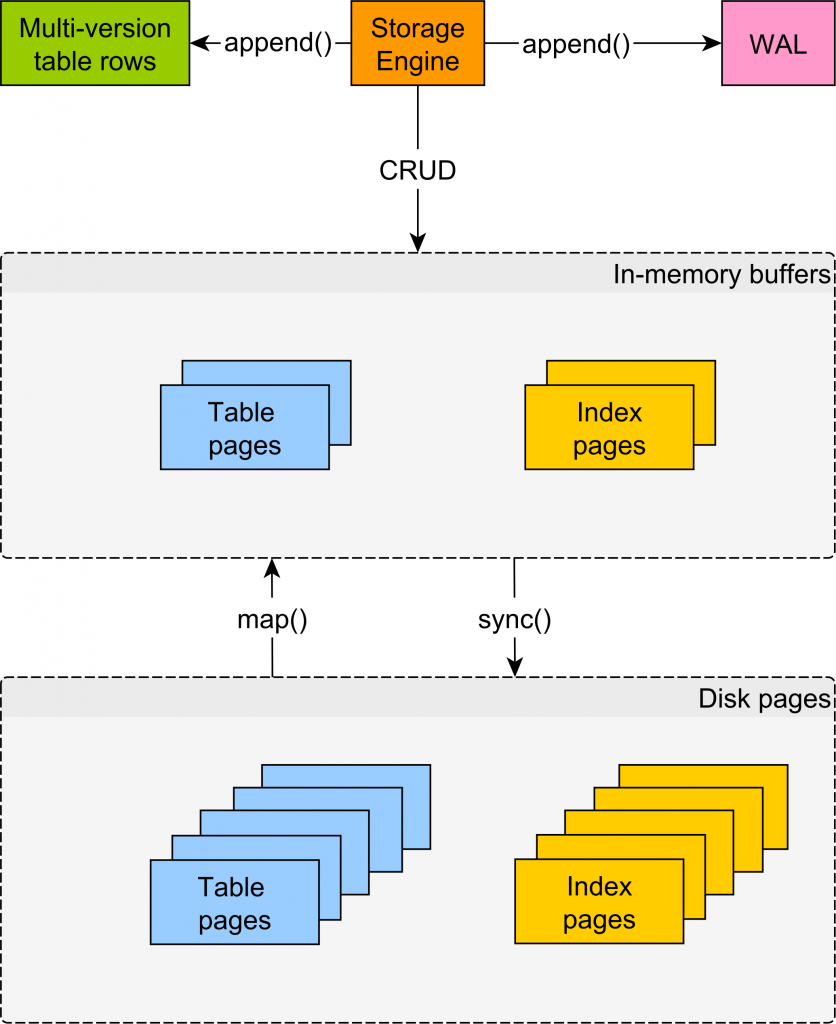
Traditionally, database systems use two logs to mark transaction modifications:
- the undo log is used to restore uncommitted changes in case of rollback. In Oracle and MySQL, the undo log stores the diff between the latest uncommitted tuple and the previous state. However, because PostgreSQL stores multiple versions of the same record in the table structure, it does not need what other RDBMS define as the undo log.
- the redo_log is called WAL (Write-Ahead Log) and ensures transaction durability. The WAL stores every transaction modification since in-memory changes are only flushed periodically during checkpoints.
For both tables and indexes, PostgreSQL loads data in pages of 8KB, which is the minimum unit of reading and writing data. PostgreSQL uses the shared_buffer to cache table and index pages that are read and modified. During a checkpoint, the dirty pages found in the shared_buffer are flushed to disk.
Aside from using the shared_buffer which is meant to store the working data set, PostgreSQL relies on the OS cache for speeding up reads and writes of pages that are not stored in the shared_buffer.
Why you should definitely learn SQL Window Functions
PostgreSQL has many advanced features, and you should definitely take advantage of them. Just because you are using JPA and Hibernate, it does not mean you have to restrict all your database interactions to JPQL or Criteria API queries.
Otherwise, why do you think the EntityManager allows you to run native SQL queries?
For more details about Window Functions, check out this article.
How to call PostgreSQL functions (stored procedures) with JPA and Hibernate
Using JPA and Hibernate for writing data is very convenient, especially for typical OLTP operations. However, processing large volumes of data is much more practical to be done in the database.
For this reason, using stored procedures (or functions as PostgreSQL calls them) allows you to avoid moving large volumes of data out of the database just to process them in the data access layer. For more details about using stored procedures with JPA and Hibernate, check out this article.
Speeding up integration tests
If you are using PostgreSQL in production and all your JPA and Hibernate code is tested on an in-memory database like H2 or HSQLDB, then you are doing it all wrong. First of all, you won’t be able to test Window Functions or other PostgreSQL-specific features. Second, just because all tests run on the in-memory DB, it does not guarantee that the same code will run just fine on the PostgreSQL DB you run in production.
The only reason developers choose an in-memory database for running integration tests is the associated speed of avoiding disk access. However, you can run integration tests on PostgreSQL almost as fast as on an in-memory database. All you have to do is to map the data folder on tmpfs. For more details, check out this article.
Testcontainers makes it easy to run database integration tests that can use
tmpfs. Check out this article for more details about using Testcontainers.
JSON type
In a relational database, it’s best to store data according to the principles of the relational model.
However, it might be that you also need to store schema-less data (non-structured logs) EAV (Entity-Attribute-Value) structures, in which case, a JSON column can help you deal with such as requirement.
So, just because you are using a RDBMS, it does not mean you cannot take advantage of flexible data storage when the application requirements demand it.
For more details about how to use JSON with JPA and Hibernate, check out this article.
PostgreSQL SERIAL column and Hibernate IDENTITY generator
When using PostgreSQL, it’s tempting to use a SERIAL or BIGSERIAL column type to auto-increment Primary Keys. However, for JPA and Hibernate, this is not recommended.
For more details, check out this article.
JDBC Batching
For writing data, JDBC batching can help you reduce transaction response time. When using Hibernate, enabling batching is just a matter of setting one configuration property.
More, PostgreSQL offers the reWriteBatchedInserts JDBC Driver configuration property, which can help you reduce execution costs even further.
PostgreSQL advisory locks
Although optimistic locking scales better, there are certain concurrency control scenarios that call for a pessimistic locking approach.
PostgreSQL provides advisory locks which can be used as building blocks for implementing various concurrency control schemes that go beyond controlling the data stored in the relational database.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
As you can see, there are many things to keep in mind when using PostgreSQL with JPA and Hibernate. Since PostgreSQL is one of the most advanced open-source RDBMS, it’s very useful to know all these tips and adjust your data access layer to get the most out of it.









