How do PostgreSQL advisory locks work
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
PostgreSQL, like many modern RDBMS, offers both MVCC (Multi-Version Concurrency Control) and explicit pessimistic locking for various use cases when you want a custom concurrency control mechanism.
However, PostgreSQL also offers advisory locks which are very convenient to implement application-level concurrency control patterns. In this article, we are going to explain how PostgreSQL advisory locks work and how you should use them.
Exclusive and Shared advisory locks
Just like explicit pessimistic locks, advisory locks can be split into two categories:
- exclusive advisory locks
- shared advisory locks
Exclusive advisory locks
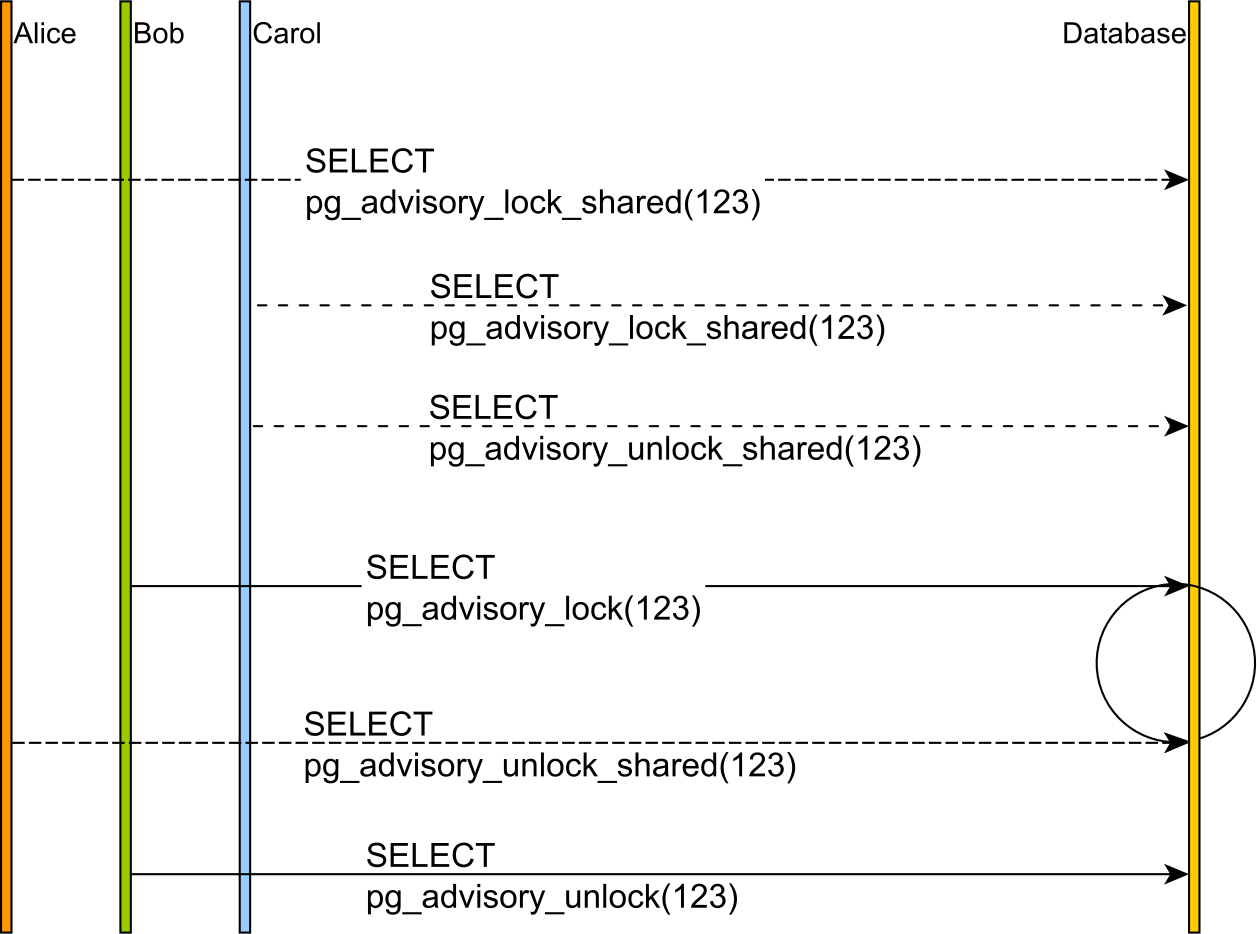
An exclusive advisory lock will block any exclusive or shared advisory lock on the same lock key.

Shared advisory locks
A shared advisory lock will block any exclusive advisory lock on the same lock key while still allowing other shared advisory locks to be acquired for the same lock key.
Session-level and Transaction-level advisory locks
Based on their scope, there are two types of advisory locks that you can acquire in PostgreSQL:
- Session-level advisory locks
- Transaction-level advisory locks
The Session-level locks are not bound to any database transaction and, once acquired, they need to be explicitly released by the application developer. Transaction-level advisory locks are bound to the currently executing transaction, and so the locks are released when the transaction ends, either with a commit or a rollback.
Session-level advisory locks
PostgreSQL defines multiple API functions which allow you to acquire a session-level advisory lock:
void pg_advisory_lock(bigint key) void pg_advisory_lock(int… key) boolean pg_try_advisory_lock(bigint key) boolean pg_try_advisory_lock(int… key) void pg_advisory_lock_shared(bigint key) void pg_advisory_lock_shared(int… key) boolean pg_try_advisory_lock_shared(bigint key) boolean pg_try_advisory_lock_shared(int… key)
Every lock is associated with an identifier, which can be a 32-bits integer or a 64-bits bigint. While the pg_advisory_lock method will block the currently executing thread if the advisory lock is already acquired by a different Session, the try_ variants return right away and you can use the boolean result value to verify if the lock has been successfully acquired.
Session-level advisory locks need to be released explicitly. Even if advisory locks are reentrant, if you acquired the same lock twice, you need to release it twice as well.
To release a Session-level advisory lock, you can use one of the following PostgreSQL functions:
void pg_advisory_unlock(bigint key) void pg_advisory_unlock(int… key) void pg_advisory_unlock_shared(bigint key) void pg_advisory_unlock_shared(int… key) void pg_advisory_unlock_all()
Transaction-level advisory locks
To acquire a transaction-level advisory lock, you need to use one of the following PostgreSQL functions:
void pg_advisory_xact_lock(bigint key) void pg_advisory_xact_lock(int… key) boolean pg_try_advisory_xact_lock(bigint key) boolean pg_try_advisory_xact_lock(int… key) void pg_advisory_xact_lock_shared(bigint key) void pg_advisory_xact_lock_shared(int… key) boolean pg_try_advisory_xact_lock_shared(bigint key) boolean pg_try_advisory_xact_lock_shared(int… key)
You don’t have to release these locks since they are automatically released at the end of their parent transaction.
Application-level Concurrency Control
Now that you understand what advisory locks are and how you can acquire and release them, it’s time to see when you need to use them. It turns out that advisory locks are very suitable for implementing various application-level concurrency control mechanisms.
For instance, let’s assume we need to coordinate access to a shared document storage. Since we have multiple nodes that can read and write these documents, we need a way to prevent both file corruption as well as reading intermediary results.

Typically, this task is very well suited for a read/write locking mechanism. However, we cannot use a Java ReadWriteLock since that would only work for a single JVM (a single node).
So, we need a way to coordinate all nodes that read and write documents, and PostgreSQL advisory locks are a very good fit for this task.
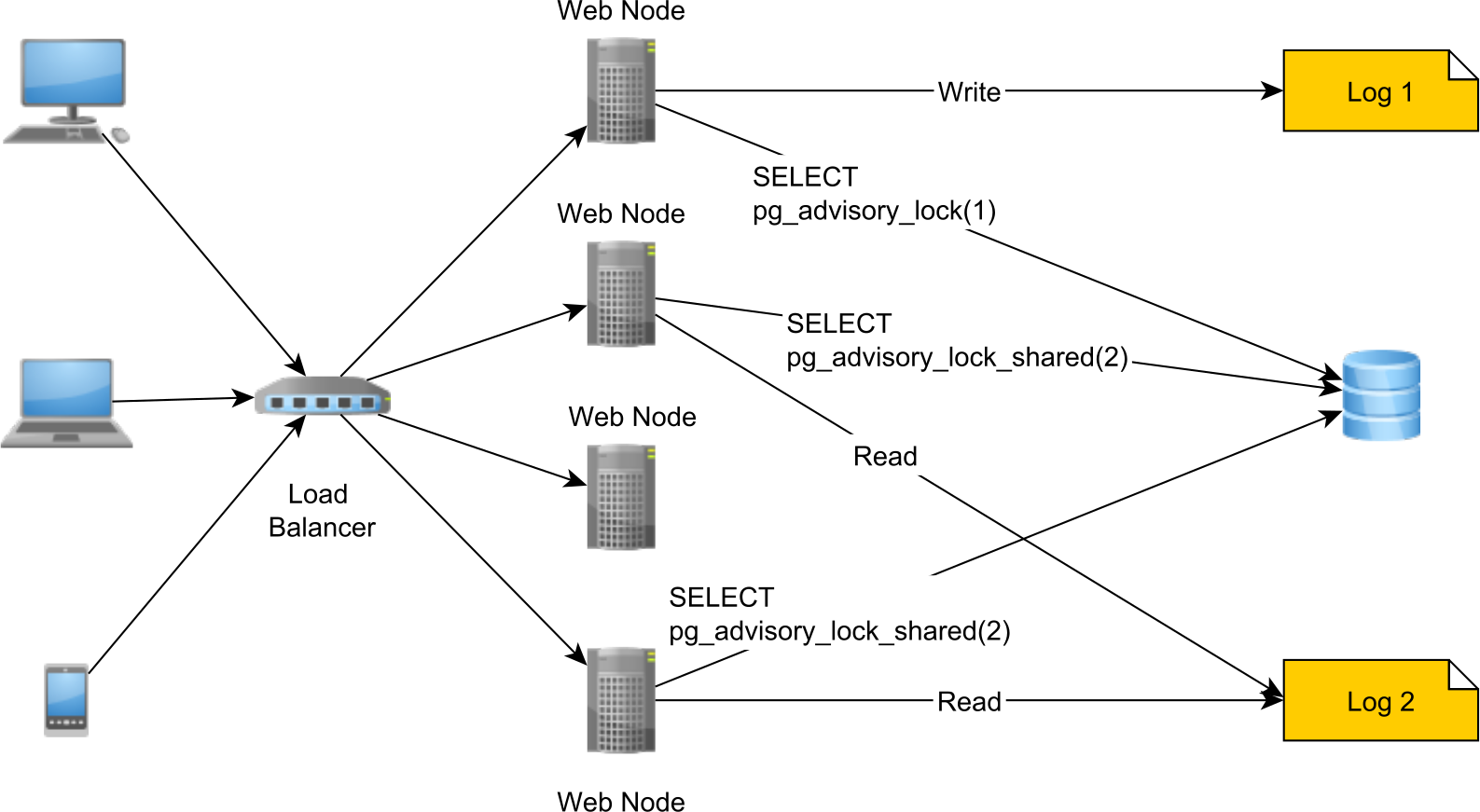
This way, whenever we want to write a document, we need to acquire an exclusive lock first. Once we acquired the exclusive lock, no other concurrent Session can acquire a shared or an exclusive lock for this document, so we block both reads and writes. When we are done writing the document, we release the exclusive lock.
If we want to read a document, we need to acquire a shared lock for the duration of the read operation to block other concurrent Sessions from writing the same document while we are still reading it.
Why not use row-level locks instead?
Although PostgreSQL offers the possibility to acquire exclusive and shared locks on a per table row basis, this is not always convenient. What if we stored the document metadata in Apache Cassandra? To use row-level locks, we need to store a row for each document that we administer. But if we have billions of documents, we don’t want to end up with a billion-row table whose only purpose is to allow us to acquire a shared or an exclusive lock on a per-row basis.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
PostgreSQL advisory locking is a very useful concurrency control mechanism, and you should definitely use it to coordinate access among multiple microservices.









