PostgreSQL triggers and isolation levels
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see how the PostgreSQL isolation levels guarantee read and write consistency when executing database triggers.
While relational database systems provide strong data integrity guarantees, it’s very important to understand how the underlying transactional engine works in order to choose the right design for your data access layer.
Database transactions
In a relational database system, transactions have ACID properties, meaning they are Atomic, Consistent, Isolated, and Durable.
Transactions allow the database to move from one consistent state to another. So, all statements executed during the scope of a given transaction must pass all constraint checks (e.g., NULL, Foreign Key, Unique Key, custom CHECK constraints) in order for the transaction to be successfully committed.
Because all transaction changes happen against the latest state of the underlying data (tables and indexes), the database system must employ a mechanism to ensure that uncommitted changes are not visible to other concurrent transactions.
2PL and MVCC
There are two concurrency control mechanisms employed by relational database systems:
The 2PL mechanism was the first one to be employed, and SQL Server still uses it by default (although it can also use MVCC). The 2PL mechanism is very easy to understand. Reads acquire share locks while writes acquire exclusive locks. Locks are only released at the end of the database transactions, be it a commit or a rollback. So, 2PL is a pessimistic locking concurrency control mechanism since it prevents conflicts by locking database records.
Nowadays, Oracle, PostgreSQL, and the MySQL InnoDB engine use the MVCC mechanism since it provides better performance compared to the 2PL mechanism. When using MVCC, share locks are no longer acquired when reading data, and a record that gets modified does not prevent other transactions from reading its previous state. So, instead of locking tuples, MVCC allows storing multiple versions of a given record.
Database model
In this article, we are going to reuse the same entity-relationship model we used in this article about PostgreSQL custom consistency rules.
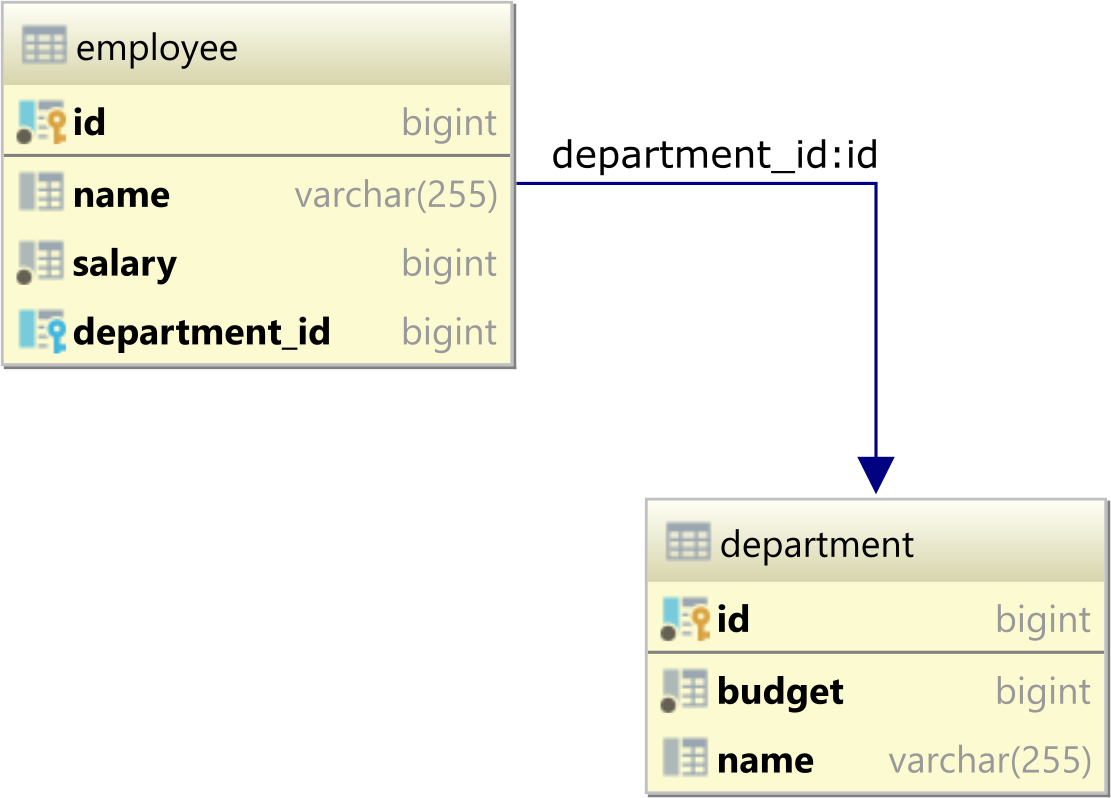
The department table has a single record:
| id | budget | name | |----|--------|------| | 1 | 100000 | IT |
And, there are three employee rows currently working in the IT department:
| id | name | salary | department_id | |----|-------|--------|---------------| | 1 | Alice | 40000 | 1 | | 2 | Bob | 30000 | 1 | | 3 | Carol | 20000 | 1 |
Over-budget prevention
Now, let’s consider we have two users, Alice and Bob, who both want to change the sum of salaries, as follows:
- Alice wants to give a 10% end-of-the-year raise to all employees in the IT department, which should raise the budget from
90000to99000 - Bob wants to hire
Davewith a salary of9000, which should also raise the budget from90000to99000
If both Alice and Bob are allowed to commit, then we will risk going over the budget. So, we need to define a check_department_budget trigger-based function that ensures the sum of salaries in a given department does not exceed the pre-defined budget:
CREATE OR REPLACE FUNCTION check_department_budget()
RETURNS TRIGGER AS $$
DECLARE
allowed_budget BIGINT;
new_budget BIGINT;
BEGIN
SELECT INTO allowed_budget budget
FROM department
WHERE id = NEW.department_id;
SELECT INTO new_budget SUM(salary)
FROM employee
WHERE department_id = NEW.department_id;
IF new_budget > allowed_budget
THEN
RAISE EXCEPTION 'Overbudget department [id:%] by [%]',
NEW.department_id,
(new_budget - allowed_budget);
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
The check_department_budget function is executed on every INSERT and UPDATE in the employee table via the check_department_budget_trigger PostgreSQL TRIGGER.
CREATE TRIGGER check_department_budget_trigger AFTER INSERT OR UPDATE ON employee FOR EACH ROW EXECUTE PROCEDURE check_department_budget();
SERIALIZABLE isolation level
Using the SERIALIZABLE isolation level is the safest bet because it’s the only isolation level that guarantees both read and write stability. When running our example using SERIALIZABLE, we can see that Bob’s transaction proceeds while Alice’s transaction is rolled back.

When using the SERIALIZABLE isolation level, a query will see the database as of the beginning of the transaction, and, at commit time, the rows we have previously read are checked to see if they were modified in the meanwhile by some concurrent transaction.
For this reason, Alice’s transaction is rolled back because the transaction engine has detected a dependency cycle between Alice’s read of employee salaries and Bob’s write.
Being the first one to commit, Bob’s transaction succeeds. On the other hand, Alice’s transaction fails as Alice assumes a database state that’s stale at the end of her transaction. The SERIALIZABLE isolation level in PostgreSQL uses an enhanced version of the standard Snapshot Isolation algorithm that can detect Write Skew anomalies.
This enhanced MVCC Snapshot Isolation mechanism is called Serializable Snapshot Isolation, and it’s based on Michael James Cahill Ph.D. thesis.
REPEATABLE READ isolation level
When switching to REPEATABLE READ and rerunning our previous example, we can see that the check_department_budget_trigger is no longer able to prevent the Write Skew anomaly:

Just like SERIALIZABLE, when using REPEATABLE READ, a query will see the database as of the beginning of the transaction. So, when the check_department_budget_trigger is executed due to Alice’s UPDATE statement, the sum of salaries will be 90 000 as it were at the beginning of Alice’s transaction.
But, unlike SERIALIZABLE, REPEATABLE READ does not roll back the transaction for Write Skew anomalies. So, both Bob and Alice are allowed to commit, and the sum of salaries goes over the budget.
The REPEATABLE READ isolation level in PostgreSQL is, in reality, the Snapshot Isolation consistency model. While Snapshot Isolation can prevent the Phantom Read anomaly, it cannot prevent the Write Skew phenomenon.
READ COMMITTED isolation level
When using the default READ COMMITTED isolation level, we can see that the check_department_budget database function prevents the Write Skew anomaly that, otherwise, would cause an over-budgeting issue:

In READ COMMITTED, the MVCC database engine allows the database transactions to read the latest committed state of records. So, even if our currently running transaction has previously read the version N of a given record if the current version of this record is now N+1 because other concurrent transaction has just changed it and committed, our transaction will read the version N+1 via a subsequent SELECT statement.
Unlike REPEATABLE READ, when using READ COMMITTED, a query will see the database as of the beginning of the query.
For this reason, the UPDATE statement will fail because the check_department_budget_trigger detected that the UPDATE would go over the budget. Even if Alice read the sum of salaries at the beginning of her transaction, the second SELECT executed by the check_department_budget function will read the latest employee salary sum, meaning that it will take Bob’s INSERT into consideration.
But, in this particular case, the Write Skew can only be prevented if Bob’s transaction is committed before Alice’s transaction calls the check_department_budget function. If Bob’s change is pending, Alice won’t be able to read the modification, and both transactions will be allowed to commit. To fix this issue, we can use either pessimistic or optimistic locking.
When using pessimistic locking, both transactions will have to lock the associated department row in the check_department_budget function. This way, once the department row is locked, the other transaction concurrent transaction attempting to acquire the same lock will block and wait for the lock to be released. This way, Alice’s transaction will wait for Bob to commit, and the Write Skew anomaly will be prevented. For more details about how you can acquire a pessimistic lock, check out this article.
Another option is to use optimistic locking and force a version increment on the associated department row, as explained in this article. This way, each employee change will trigger a version incrementation in the associated department row. At the end of Alice’s transaction, the UPDATE statement trying to increment the department will fail if the version column value was changed by Bob’s transaction, and the Write Skew anomaly will be prevented.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Understanding the isolation level guarantees provided by the underlying database system is very important when designing a data access layer. In this case,
When defining a trigger-based function that enforces a certain constraint, it’s better to test it against the isolation level you are going to use in production, as, otherwise, you might end up with data integrity issues that are very hard to spot after the fact.








