14 High-Performance Java Persistence Tips
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to show you various high-performance Java Persistence optimization tips that will help you get the most out of your data access layer.
A high-performance data access layer requires a lot of knowledge about database internals, JDBC, JPA, Hibernate, and this post summarizes some of the most important techniques you can use to optimize your enterprise application.
1. SQL statement logging
If you’re using a framework that generates statements on your behalf, you should always validate the effectiveness and efficiency of each executed statement. A testing-time assertion mechanism is even better because you can catch N+1 query problems even before you commit your code.
2. Connection management
Database connections are expensive, therefore you should always use a connection pooling mechanism.
Because the number of connections is given by the capabilities of the underlying database cluster, you need to release connections as fast as possible.
In performance tuning, you always have to measure, and setting the right pool size is no different. A tool like FlexyPool can help you find the right size even after you deployed your application into production.
3. JDBC batching
JDBC batching allows us to send multiple SQL statements in a single database roundtrip. The performance gain is significant both on the Driver and the database side. PreparedStatements are very good candidates for batching, and some database systems (e.g. Oracle) support batching only for prepared statements only.
Since JDBC defines a distinct API for batching (e.g. PreparedStatement.addBatch and PreparedStatement.executeBatch), if you’re generating statements manually, then you should know right from the start whether you should be using batching or not. With Hibernate, you can switch to batching with a single configuration.
Hibernate 5.2 offers Session-level batching, so it’s even more flexibile in this regard.
4. Statement caching
Statement caching is one of the least-known performance optimizations that you can easily take advantage of. Depending on the underlying JDBC Driver, you can cache PreparedStatements both on the client-side (the Driver) or databases-side (either the syntax tree or even the execution plan).
5. Hibernate identifiers
When using Hibernate, the IDENTITY generator is not a good choice since it disables JDBC batching.
TABLE generator is even worse since it uses a separate transaction for fetching a new identifier, which can put pressure on the underlying transaction log, as well as the connection pool since a separate connection is required every time we need a new identifier.
SEQUENCE is the right choice, and even SQL Server supports since version 2012. For SEQUENCE identifiers, Hibernate has long been offering optimizers like pooled or pooled-lo which can reduce the number of database roundtrips required for fetching a new entity identifier value.
6. Choosing the right column types
You should always use the right column types on the database side. The more compact the column type is, the more entries can be accommodated in the database working set, and indexes will better fit into memory. For this purpose, you should take advantage of database-specific types (e.g. inet for IPv4 addresses in PostgreSQL), especially since Hibernate is very flexible when it comes to implementing a new custom Type.
7. Relationships
Hibernate comes with many relationship mapping types, but not all of them are equal in terms of efficiency.
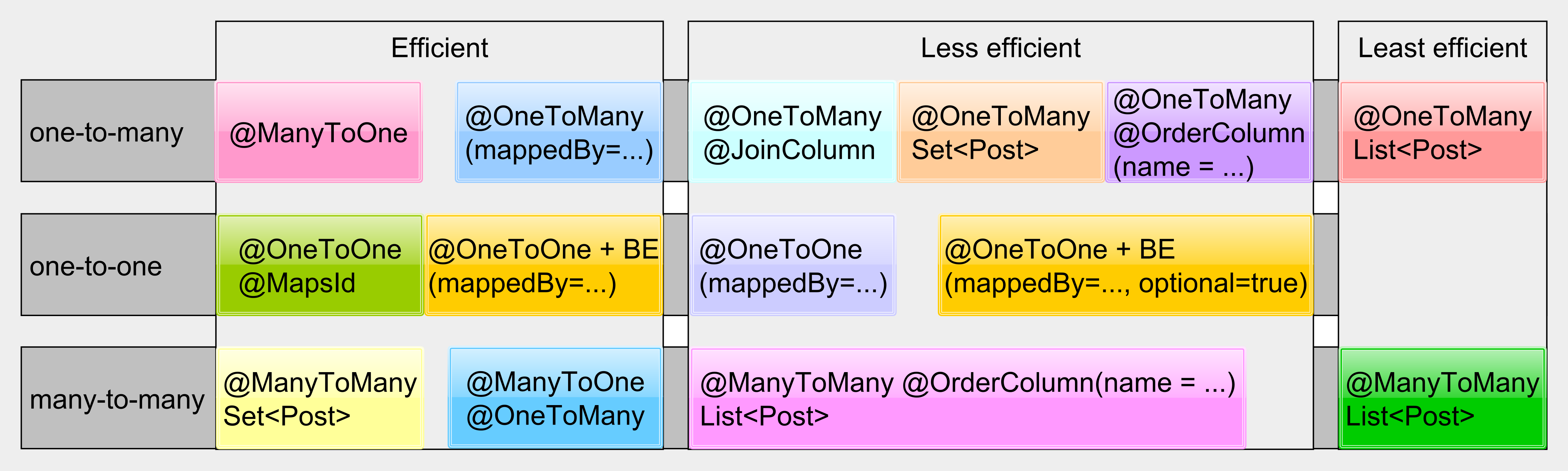
Unidirectional collections and @ManyToMany List(s) should be avoided. If you really need to use entity collections, then bidirectional @OneToMany associations are preferred. For the @ManyToMany relationship, use Set(s) since they are more efficient in this case or simply map the linked many-to-many table as well and turn the @ManyToMany relationship into two bidirectional @OneToMany associations.
However, unlike queries, collections are less flexible since they cannot be easily paginated, meaning that we cannot use them when the number of child associations is rather high. For this reason, you should always question if a collection is really necessary. An entity query might be a better alternative in many situations.
8. Inheritance
When it comes to inheritance, the impedance mismatch between object-oriented languages and relational databases becomes even more apparent. JPA offers SINGLE_TABLE, JOINED, and TABLE_PER_CLASS to deal with inheritance mapping, and each of these strategies has pluses and minuses.
SINGLE_TABLE performs the best in terms of SQL statements, but we lose on the data integrity side since we cannot use NOT NULL constraints.
JOINED addresses the data integrity limitation while offering more complex statements. As long as you don’t use polymorphic queries or @OneToMany associations against base types, this strategy is fine. Its true power comes from polymorphic @ManyToOne associations backed by a Strategy pattern on the data access layer side.
TABLE_PER_CLASS should be avoided since it does not render efficient SQL statements.
9. Persistence Context size
When using JPA and Hibernate, you should always mind the Persistence Context size. For this reason, you should never bloat it with tons of managed entities. By restricting the number of managed entities, we gain better memory management, and the default dirty checking mechanism is going to be more efficient as well.
10. Fetching only what’s necessary
Fetching too much data is probably the number one cause for data access layer performance issues. One issue is that entity queries are used exclusively, even for read-only projections.
DTO projections are better suited for fetching custom views, while entities should only be fetched when the business flow requires to modify them.
EAGER fetching is the worst, and you should avoid anti-patterns such as Open-Session in View.
11. Caching
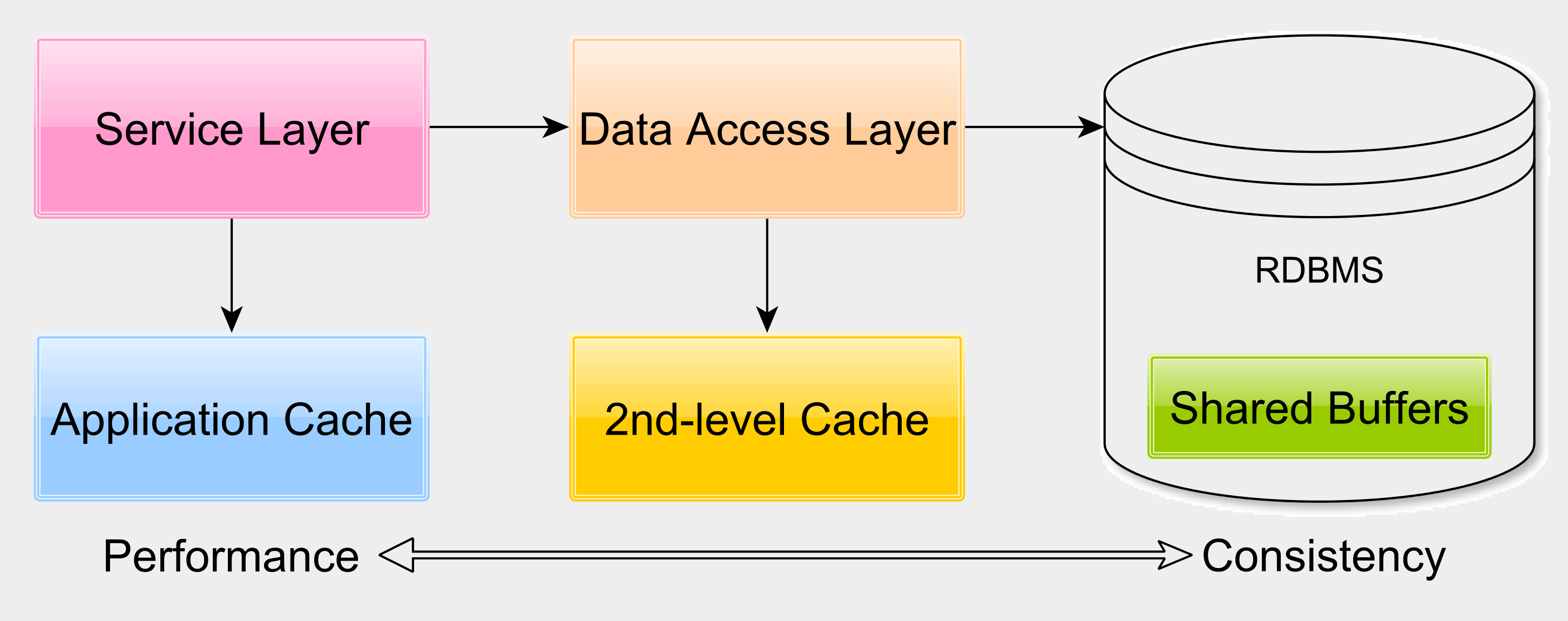
Relational database systems use many in-memory buffer structures to avoid disk access. Database caching is very often overlooked. We can lower response time significantly by properly tuning the database engine so that the working set resides in memory and is not fetched from disk all the time.
Application-level caching is not optional for many enterprise applications. Application-level caching can reduce response time while offering a read-only secondary store for when the database is down for maintenance or because of some serious system failure.
The second-level cache is very useful for reducing read-write transaction response time, especially in Single-Primary Replication architectures. Depending on application requirements, Hibernate allows you to choose between READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, and TRANSACTIONAL.
12. Concurrency control
The choice of transaction isolation level is of paramount importance when it comes to performance and data integrity. For multi-request web flows, to avoid lost updates, you should use optimistic locking with detached entities or an EXTENDED Persistence Context.
To avoid optimistic locking false positives, you can use versionless optimistic concurrency control or split entities based write-based property sets.
13. Unleash database query capabilities
Just because you use JPA or Hibernate, it does not mean that you should not use native queries. You should take advantage of Window Functions, CTE (Common Table Expressions), CONNECT BY, PIVOT.
These constructs allow you to avoid fetching too much data just to transform it later in the application layer. If you can let the database do the processing, you can fetch just the end result, therefore, saving lots of disk I/O and networking overhead. To avoid overloading the Master node, you can use database replication and have multiple replica nodes available so that data-intensive tasks are executed on a replica rather than on the Master.
14. Scale up and scale out
Relational databases do scale very well. If Facebook, Twitter, Pinterest or StackOverflow can scale their database system, there is a good chance you can scale an enterprise application to its particular business requirements.

Database replication and sharding are very good ways to increase throughput, and you should totally take advantage of these battle-tested architectural patterns to scale your enterprise application.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
A high-performance data access layer must resonate with the underlying database system. Knowing the inner workings of a relational database and the data access frameworks in use can make the difference between a high-performance enterprise application and one that barely crawls.
There are many things you can do to improve the performance of your data access layer, and I’m only scratching the surface here.
If you want to read more on this particular topic, you should check my High-Performance Java Persistence book as well. With over 450 pages, this book explains all these concepts in great detail.









I know, thanks to your posts elsewhere, but I hadn’t made the connection.
Thanks you !
You’re welcome. If you liked the articles, you are going to love my video course as well.
Hi,
It’s very helpfull.
At chapter 7. Relationships, what do you mean by @OneToOne + BE.
The BE is set for what ?
Thanks for your help
It means Bytecode Enhancement. Check out this article for more details.