PostgreSQL Heap-Only-Tuple or HOT Update Optimization
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to analyze how PostgreSQL Heap-Only-Tuple or HOT Update optimization works, and why you should avoid indexing columns that change very frequently.
PostgreSQL Tables and Indexes
Unlike SQL Server or MySQL, which store table records in a Clustered Index, in Oracle and PostgreSQL, records are stored in Heap Tables that have unique row identifiers. A Primary Key index will use the Primary Key column to build the B+Tree index, and the index leaves will store the row identifiers, as illustrated by the following diagram:
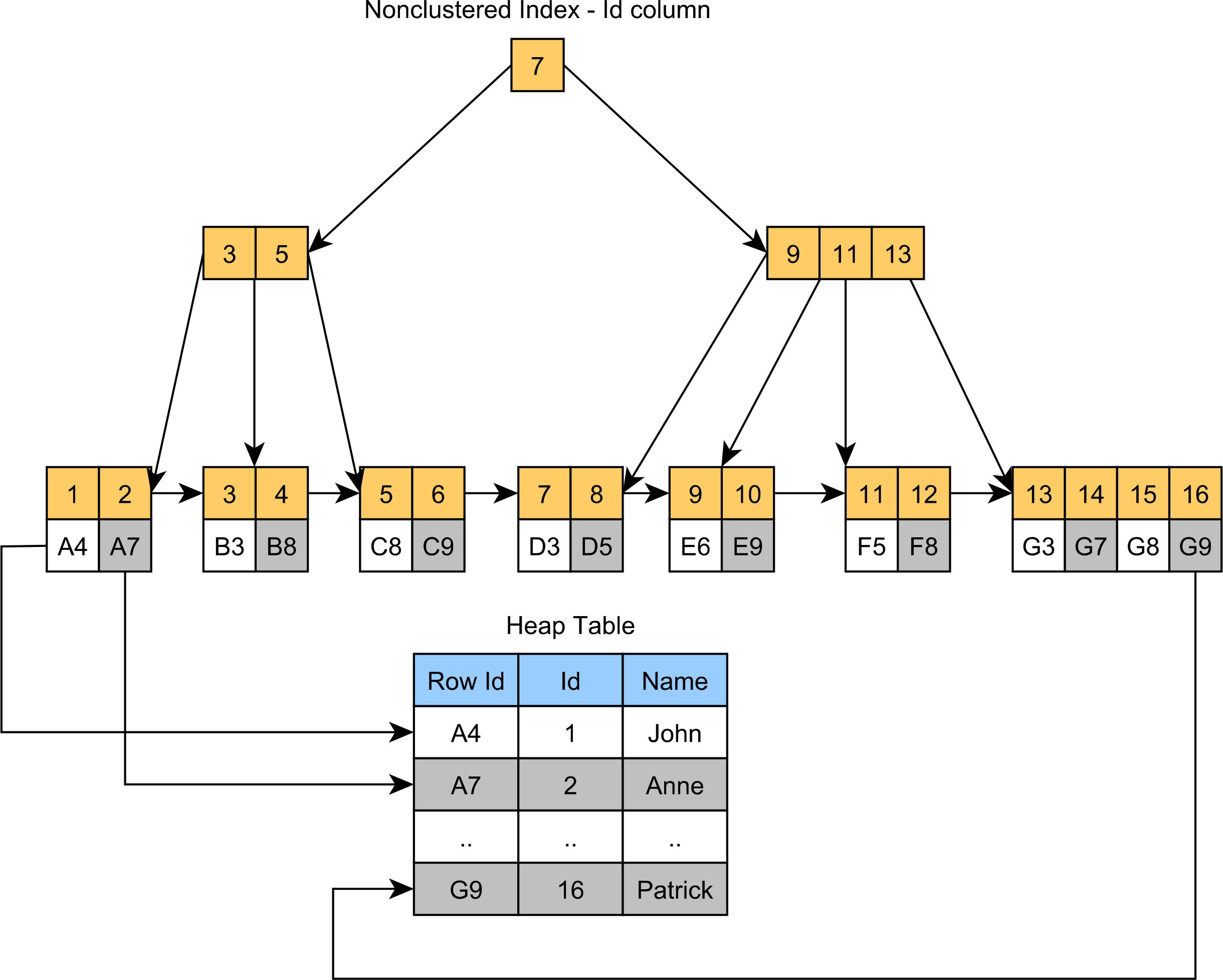
Now, in PostgreSQL, the row identifier is stored in the Heap Table in a column called ctid and looks like this:
(page_number, tuple_number)
The page_number is the number of the page in the shared_buffers that contains the record, and the tuple_number is the offset number inside the in-memory page where the current version of this record resides.
For instance, if we create a new post record, using the following INSERT statement:
INSERT INTO post (id, title) VALUES (1, 'High-Performance Java Persistence, revision 1')
We can extract the ctid column value from the associated table record like this:
SELECT ctid, id, title FROM post WHERE id = 1
When executing the SQL query above, we get the following result set:
| ctid | id | title | | ----- | -- | --------------------------------------------- | | (0,1) | 1 | High-Performance Java Persistence, revision 1 |
So, the current version of this post record was stored in the first page, and it’s located in the first tuple inside that page.
When changing the post record using the following UPDATE statement:
UPDATE post SET title = 'High-Performance Java Persistence, revision 2' WHERE id = 1
The ctid value now indicates that the record is now stored in a second tuple inside the first page:
| ctid | id | title | | ----- | -- | --------------------------------------------- | | (0,2) | 1 | High-Performance Java Persistence, revision 2 |
As I explained in this article, the UPDATE in PostgreSQL is basically equivalent to soft deleting the old tuple and creating a new tuple containing the latest record state, as illustrated by the following diagram:

PostgreSQL Heap-Only Tuple or HOT Update Optimization
Now, if the Primary and Secondary indexes reference the ctid column value, it means that every time we modify a table record, all the associated index entries have to be modified as well to reference the new ctid value.
To avoid the overhead of updating all index entries, PostgreSQL provides the Heap-Only-Tuple or HOT Update optimization. However, this optimization can only happen if the page is not fully filled and can accommodate a new tuple version and if the UPDATE does not change any column that has an associated index.
If those two conditions are met, then PostgreSQL can create a reference between the old and the new tuple so that when the query executor follows a row identifier from the index to the table record, PostgreSQL will locate the tuple provided by the old ctid value that was given by the index leaf and navigate the HOT ctid references up to the latest tuple version.
To verify if the UPDATE statements use the PostgreSQL Heap-Only-Tuple or HOT Update optimization, you can query the n_tup_upd and n_tup_hot_upd columns of the pg_stat_user_tables view like this:
SELECT n_tup_upd, n_tup_hot_upd FROM pg_stat_user_tables WHERE relname = 'post'
The n_tup_upd value provides the number of tuples that got updated and the n_tup_hot_upd value tells how many tuple updates had used the HOT optimization.
To inspect the n_tup_upd and n_tup_hot_upd values for our post table, we are going to use the following checkHeapOnlyTuples utility method:
private void checkHeapOnlyTuples() {
doInJDBC(connection -> {
try (Statement statement = connection.createStatement()) {
ResultSet resultSet = statement.executeQuery("""
SELECT n_tup_upd, n_tup_hot_upd
FROM pg_stat_user_tables
WHERE relname = 'post'
"""
);
while (resultSet.next()) {
int i = 0;
long n_tup_upd = resultSet.getLong(++i);
long n_tup_hot_upd = resultSet.getLong(++i);
LOGGER.info(
"n_tup_upd: {}, n_tup_hot_upd: {}",
n_tup_upd,
n_tup_hot_upd
);
}
} catch (SQLException e) {
throw new IllegalStateException(e);
}
});
}
And, when running the following test case that upserts the post record 5 times:
AtomicInteger revision = new AtomicInteger();
checkHeapOnlyTuples();
while (revision.incrementAndGet() <= 5){
doInStatelessSession(session -> {
String title = String.format(
"High-Performance Java Persistence, revision %d",
revision.get()
);
session.upsert(
new Post()
.setId(1L)
.setTitle(title)
);
});
}
checkHeapOnlyTuples();
We will get the following results:
n_tup_upd: 0, n_tup_hot_upd: 0 Query:[" merge into post as t using (select cast(? as bigint) id, cast(? as text) title) as s on (t.id=s.id) when not matched then insert (id, title) values (s.id, s.title) when matched then update set title=s.title "], Params:[(1, High-Performance Java Persistence, revision 1)] Query:[" merge into post as t using (select cast(? as bigint) id, cast(? as text) title) as s on (t.id=s.id) when not matched then insert (id, title) values (s.id, s.title) when matched then update set title=s.title "], Params:[(1, High-Performance Java Persistence, revision 2)] Query:[" merge into post as t using (select cast(? as bigint) id, cast(? as text) title) as s on (t.id=s.id) when not matched then insert (id, title) values (s.id, s.title) when matched then update set title=s.title "], Params:[(1, High-Performance Java Persistence, revision 3)] Query:[" merge into post as t using (select cast(? as bigint) id, cast(? as text) title) as s on (t.id=s.id) when not matched then insert (id, title) values (s.id, s.title) when matched then update set title=s.title "], Params:[(1, High-Performance Java Persistence, revision 4)] Query:[" merge into post as t using (select cast(? as bigint) id, cast(? as text) title) as s on (t.id=s.id) when not matched then insert (id, title) values (s.id, s.title) when matched then update set title=s.title "], Params:[(1, High-Performance Java Persistence, revision 5)] n_tup_upd: 4, n_tup_hot_upd: 4
For more details about the
MERGEstatement, check out this article.And, if you’re interested in learning about the Hibernate
upsertmethod, then check out this article as well.
Because we are running the test on an empty database, the first MERGE statement does not find any post record, so the INSERT gets executed. Afterwards, the next 4 MERGE statements will find the previously created post record, and 4 UPDATE statements will be executed. That’s why the n_tup_upd has a value of 4.
The n_tup_hot_upd metric has a value of 4, meaning that the 4 UPDATE statements executed by the MERGE statements had benefited from the PostgreSQL Heap-Only-Tuple optimization or HOT Update optimization.
Frequently updated columns and Indexing
Now, if we modify the post table so that we add a version column:
CREATE TABLE post (
id bigint NOT NULL,
title varchar(100),
version smallint NOT NULL,
PRIMARY KEY (id)
)
And we instruct Hibernate to use the version column for optimistic locking via the @Version annotation:
@Version private short version;
Now, when fetching a Post entity:
Post post = entityManager.find(Post.class, 1L);
Hibernate extracts the version column value and stores it inside the entity loadedState that’s used for the dirty checking mechanism:
SELECT
p.id,
p.title,
p.version
FROM post p
WHERE p.id = 1
Afterward, when updating the Post entity in the same Persistence Context:
post.setTitle(
String.format(
"High-Performance Java Persistence, revision %d",
revision.incrementAndGet()
)
);
Hibernate will change the title property and increment the version column if and only if the post record matches the version value that was previously fetched when we read the Post entity:
UPDATE post
SET
title = 'High-Performance Java Persistence, revision 2',
version = 1
WHERE
id = 1 AND
version = 0
However, if we add an index on the version column:
CREATE INDEX IF NOT EXISTS idx_post_version ON post (version)
And, we run the following test case that inserts a post record followed by 5 updates executed in 5 successive transactions:
AtomicInteger revision = new AtomicInteger();
doInJPA(entityManager -> {
String title = String.format(
"High-Performance Java Persistence, revision %d",
revision.get()
);
entityManager.persist(
new Post()
.setId(1L)
.setTitle(title)
);
});
checkHeapOnlyTuples();
while (revision.incrementAndGet() <= 5){
doInJPA(entityManager -> {
Post post = entityManager.find(Post.class, 1L);
post.setTitle(
String.format(
"High-Performance Java Persistence, revision %d",
revision.get()
)
);
});
}
checkHeapOnlyTuples();
We can see that this time, PostgreSQL can no longer take advantage of the Heap-Only-Tuple optimization:
n_tup_upd: 0, n_tup_hot_upd: 0 Query:["select p1_0.id,p1_0.title,p1_0.version from post p1_0 where p1_0.id=?"], Params:[(1)] Query:["update post set title=?,version=? where id=? and version=?"], Params:[(High-Performance Java Persistence, revision 1, 1, 1, 0)] Query:["select p1_0.id,p1_0.title,p1_0.version from post p1_0 where p1_0.id=?"], Params:[(1)] Query:["update post set title=?,version=? where id=? and version=?"], Params:[(High-Performance Java Persistence, revision 2, 2, 1, 1)] Query:["select p1_0.id,p1_0.title,p1_0.version from post p1_0 where p1_0.id=?"], Params:[(1)] Query:["update post set title=?,version=? where id=? and version=?"], Params:[(High-Performance Java Persistence, revision 3, 3, 1, 2)] Query:["select p1_0.id,p1_0.title,p1_0.version from post p1_0 where p1_0.id=?"], Params:[(1)] Query:["update post set title=?,version=? where id=? and version=?"], Params:[(High-Performance Java Persistence, revision 4, 4, 1, 3)] Query:["select p1_0.id,p1_0.title,p1_0.version from post p1_0 where p1_0.id=?"], Params:[(1)] Query:["update post set title=?,version=? where id=? and version=?"], Params:[(High-Performance Java Persistence, revision 5, 5, 1, 4)] n_tup_upd: 5, n_tup_hot_upd: 0
The n_tup_hot_upd value is 0 because the idx_post_version index on the version column has prevented PostgreSQL from applying the Heap-Only-Tuple optimization, and all the indexes that point to the updated post record will have to be updated as well to match the latest table row identifier.
Another aspect that can prevent the Heap-Only-Tuple optimization in the page fill factor.
Check out this article for more details about how the page fill factor can influence the HOT optimization.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Without the Heap-Only Tuple or HOT Update optimization, PostgreSQL can suffer from Write Amplification. This was one of the problems that contributed to Uber migrating from PostgreSQL to MySQL in 2016.
Monitoring the n_tup_upd and n_tup_hot_upd metrics of the pg_stat_user_tables view can reveal whether your PostgreSQL database can take advantage of the Heap-Only-Tuple optimization when executing the Update statements.









