How do UPSERT and MERGE work in Oracle, SQL Server, PostgreSQL and MySQL
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
Last week, Burkhard Graves asked me to answer the following StackOverflow question:
@vlad_mihalcea Hi Vlad, do you know this one: https://t.co/Rs0SbogHoV? I have a sim prob (w/o unique key) and don't find efficient solution.
— Burkhard Graves (@dhukas) November 3, 2017
And, since he wasn’t convinced about my answer:
Hi @vlad_mihalcea, I've created a small test: https://t.co/trs709WJvr . Have a good start into the week!
— Burkhard Graves (@dhukas) November 5, 2017
I decided to turn it into a dedicated article and explain how UPSERT and MERGE work in the top 4 most common relational database systems: Oracle, SQL Server, PostgreSQL, and MySQL.
Domain Model
For this article, let’s assume we have the following post and post_details tables which have a one-to-one table relationship.

The problem
The original StackOverflow question asks for a find-or-insert mechanism in Hibernate. Basically, we want to retrieve a record from the database, and if the record is not found, we want to safely insert it. However, the solution must work in a multi-threaded environment, so we need a solid concurrency control mechanisms.
On duplicate key, ignore!
Although there are several answers based on Hibernate pessimistic locking mechanism, I came up with a different approach. Instead of finding the record, we can try to insert it first. For this to work, we need a way to skip the INSERT when there’s already a row that was inserted previously.
Now, Hibernate does not support UPSERT or MERGE, but, even if we use Hibernate in our project, it does not mean we cannot combine it with other data access frameworks as well. Many times, only a native SQL query could satisfy a given requirement.
Therefore, you should take advantage of everything the underlying RDBMS has to offer.
For our example, we are going to use jOOQ because it exposes a unified API that translates to the proper UPSERT or MERGE syntax supported by the underlying database.
When using jOOQ, the aforementioned INSERT then SELECT solution can be expressed as follows:
sql
.insertInto(POST_DETAILS)
.columns(
POST_DETAILS.ID,
POST_DETAILS.CREATED_BY,
POST_DETAILS.CREATED_ON
)
.values(
postId,
"Alice",
Timestamp.from(
LocalDateTime.now().toInstant(ZoneOffset.UTC)
)
)
.onDuplicateKeyIgnore()
.execute();
PostDetailsRecord postDetailsRecord = sql.selectFrom(POST_DETAILS)
.where(field(POST_DETAILS.ID).eq(postId))
.fetchOne();
Let’s see how the INSERT statement is generated depending on the database system we are using.
Oracle
If you’re using Oracle, jOOQ is going to use the MERGE statement:
MERGE INTO "ORACLE"."POST_DETAILS"
USING
(SELECT 1 "one" FROM dual)
ON
("ORACLE"."POST_DETAILS"."ID" = 1)
WHEN NOT matched THEN
INSERT (
"ID",
"CREATED_BY",
"CREATED_ON"
)
VALUES (
1,
'Alice',
TIMESTAMP '2017-11-06 16:12:18.407'
)
Just like its name implies, MERGE is meant to select records from one or more tables so that we can insert or update a given table or view.
In our case, the INSERT is executed only when there is no post_details record with the given identifier.
SQL Server
If you’re using, SQL Server, jOOQ is going to use the MERGE statement:
MERGE INTO [high_performance_java_persistence].[dbo].[post_details]
USING
(SELECT 1 [one]) AS dummy_82901439([one])
ON
[high_performance_java_persistence].[dbo].[post_details].[id] = 1
WHEN NOT matched THEN
INSERT (
[id],
[created_by],
[created_on]
)
VALUES (
1,
'Alice',
'2017-11-06 16:34:11.509'
)
Just like Oracle, the SQL Server MERGE statement is used to execute INSERT, UPDATE or DELETE statements on a target table based on the result set generated from a source table. A typical scenario for using MERGE would be when you have to synchronize two tables having the same structure but potentially different data sets. The MERGE statement would then allow you to generate a diff between these two tables.
In our example, the INSERT is executed only when there is no post_details record with the given identifier.
PostgreSQL
Unlike Oracle and SQL Server which implement the SQL:2003 MERGE statement, PostgreSQL does not, and they offer the UPSERT alternative via the ON CONFLICT DO UPDATE / NOTHING SQL clause.
So, when running our example on PostgreSQL, jOOQ generates the following SQL statement:
INSERT INTO "public"."post_details" (
"id",
"created_by",
"created_on")
VALUES (
1,
'Alice',
TIMESTAMP '2017-11-06 16:42:37.692')
ON CONFLICT DO NOTHING
Because of the ON CONFLICT DO NOTHING clause, the INSERT will not fail if there is already a record satisfying the same filtering criteria, which, in our case, means that it has the same Primary Key value.
MySQL
Even if MySQL 5.7 does not implement the SQL:2003 MERGE statement, it offers the INSERT IGNORE and ON DUPLICATE KEY UPDATE syntax is similar to PostgreSQL UPSERT feature.
So, when running our example on MySQL, jOOQ generates the following SQL statement:
INSERT
IGNORE INTO `post_details` (
`id`,
`created_by`,
`created_on`
)
VALUES (
1,
'Alice',
{ts '2017-11-06 16:53:34.127'}
)
So far, so good!
Concurrency Control
However, how does the database ensures consistency when having multiple threads operating MERGE or UPSERT?
As I explained before, once a transaction has inserted, updated or deleted a record, the row is locked until the transaction ends, either via a commit or a rollback.
Hence, the concurrency control comes via standard exclusive locking, even when the database uses MVCC (Multi-Version Concurrency Control).
Now, to prove it, I have built the following test case:
doInJOOQ(sql -> {
sql.delete(POST_DETAILS).execute();
sql.delete(POST).execute();
PostRecord postRecord = sql
.insertInto(POST).columns(
POST.ID,
POST.TITLE
)
.values(
HIBERNATE_SEQUENCE.nextval(),
val("High-Performance Java Persistence"
)
.returning(POST.ID)
.fetchOne();
final Long postId = postRecord.getId();
sql
.insertInto(POST_DETAILS)
.columns(
POST_DETAILS.ID,
POST_DETAILS.CREATED_BY,
POST_DETAILS.CREATED_O
)
.values(
postId,
"Alice",
Timestamp.from(
LocalDateTime
.now()
.toInstant(ZoneOffset.UTC)
)
)
.onDuplicateKeyIgnore()
.execute();
final AtomicBoolean preventedByLocking =
new AtomicBoolean();
executeAsync(() -> {
try {
doInJOOQ(_sql -> {
Connection connection = _sql
.configuration()
.connectionProvider()
.acquire();
setJdbcTimeout(connection);
_sql
.insertInto(POST_DETAILS)
.columns(
POST_DETAILS.ID,
POST_DETAILS.CREATED_BY,
POST_DETAILS.CREATED_ON
)
.values(
postId,
"Bob",
Timestamp.from(
LocalDateTime
.now()
.toInstant(ZoneOffset.UTC)
)
)
.onDuplicateKeyIgnore()
.execute();
});
} catch (Exception e) {
if( ExceptionUtil.isLockTimeout( e )) {
preventedByLocking.set( true );
}
}
aliceLatch.countDown();
});
awaitOnLatch(aliceLatch);
PostDetailsRecord postDetailsRecord = sql
.selectFrom(POST_DETAILS)
.where(field(POST_DETAILS.ID).eq(postId))
.fetchOne();
assertTrue(preventedByLocking.get());
});
Looks scary, but it’s actually pretty simple! The test executes the following steps:
- First, we delete everything from the
post_detailsandposttables. - Alice, who executes the main thread, is going to insert a
postrow and fetch the newly inserted record identifier. - Alice executes a
MERGEorUPSERTfor thepost_detailsrecord that has the same Primary Key as the newly insertedpostrecord. - After Alixa has executed the
MERGEorUPSERT, Bob will start a new transaction and attempt to execute aMERGEorUPSERTfor the samepost_detailsrecord, meaning we are going to use the same Primary Key value. - Bob’s
MERGEorUPSERTwill be blocked by Alice lock and a timeout exception will be thrown. - Once we catch the timeout exception, we count down the latch on which Alice awaits.
- Alice thread can resume and generate the
SELECTstatement.
The process can be better visualized in the following diagram:
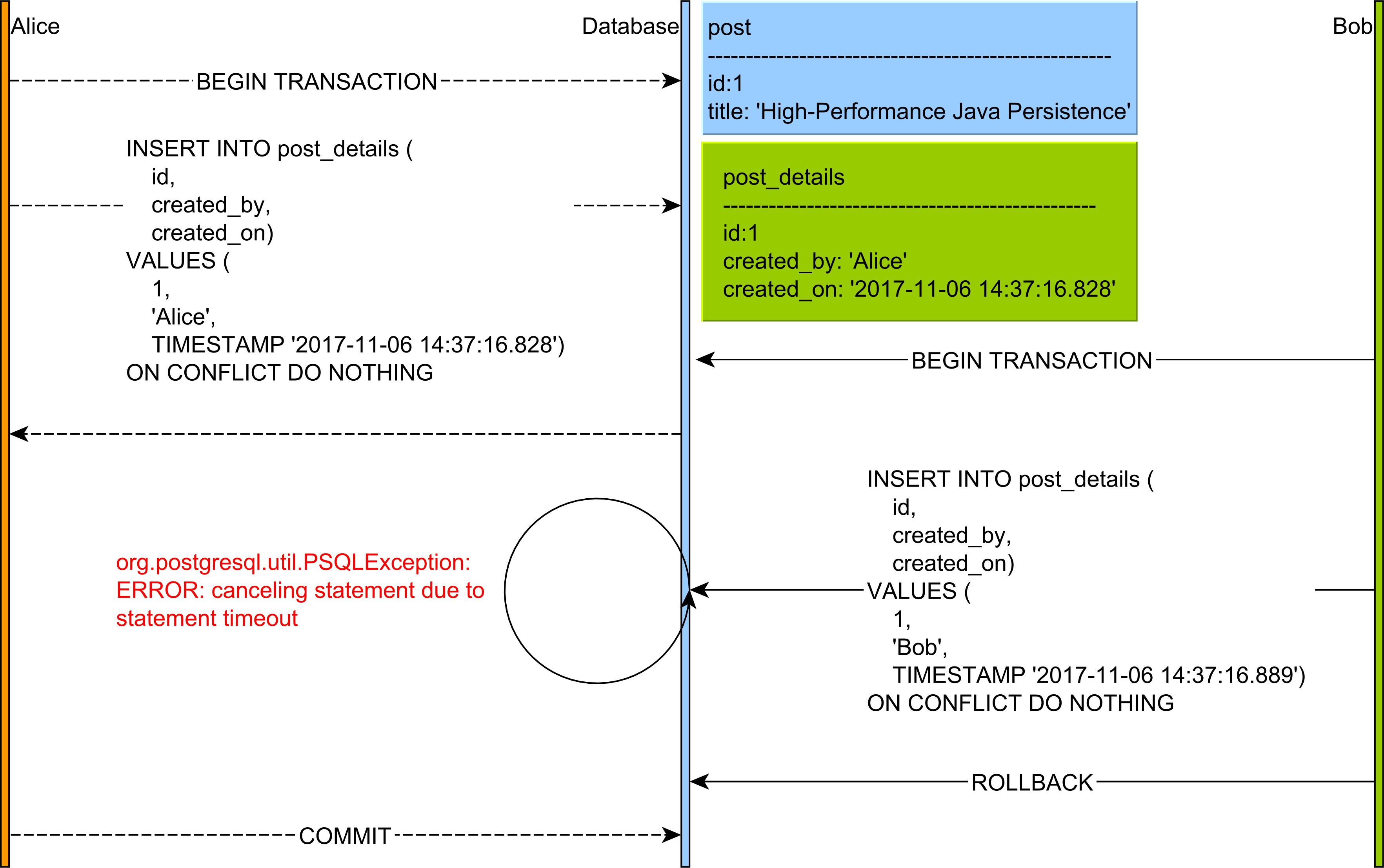
It’s as easy as that!
All tests are available on GitHub, so feel free to fork my GitHub repository and run them yourself:
Cool, right?
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The way a relational database implements its concurrency control mechanism might not be always obvious for a data access developer. However, it’s very important to understand it, especially in regards to transaction isolation level.
For more details, check out my Transactions and Concurrency Control presentation or, even better, buy my book. I have two very detailed chapters on this topic.








