The JPA and Hibernate first-level cache
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to explain how the JPA and Hibernate first-level mechanism works and how it can improve the performance of your data access layer.
In JPA terminology, the first-level cache is called Persistence Context, and it’s represented by the EntityManager interface. In Hibernate, the first-level cache is represented by the Session interface, which extends the JPA EntityManager one.
JPA entity states and the associated state transition methods
A JPA entity can be in one of the following states:
- New (Transient)
- Managed (Associated)
- Detached (Dissociated)
- Removed (Deleted)
To change the entity state, you can use the persist, merge, or remove methods of the JPA EntityManager, as illustrated by the following diagram:
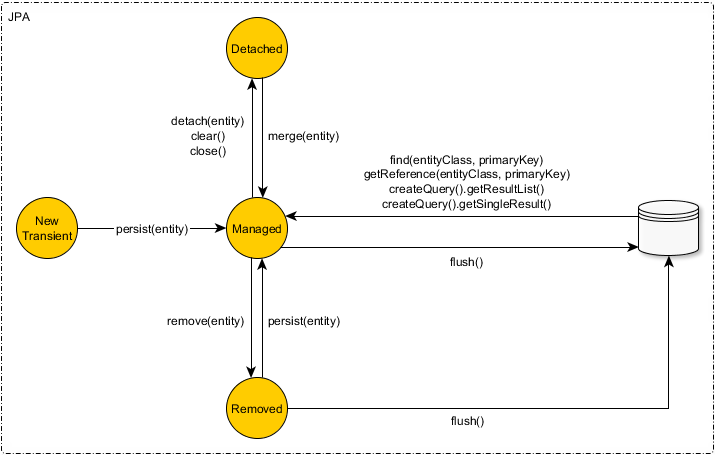
When you are calling the persist method, the entity state changes from New to Managed.
And, when calling the find method, the state of the entity is also Managed.
After closing the EntityManager or calling the evict method, the entity state becomes Detached.
When the entity is passed to the remove method of the JPA EntityManager, the entity state becomes Removed.
The Hibernate first-level cache implementation
Internally, Hibernate stores the entities in the following map:
Map<EntityUniqueKey, Object> entitiesByUniqueKey = new HashMap<>(INIT_COLL_SIZE);
And, the EntityUniqueKey is defined like this:
public class EntityUniqueKey implements Serializable {
private final String entityName;
private final String uniqueKeyName;
private final Object key;
private final Type keyType;
...
@Override
public boolean equals(Object other) {
EntityUniqueKey that = (EntityUniqueKey) other;
return that != null &&
that.entityName.equals(entityName) &&
that.uniqueKeyName.equals(uniqueKeyName) &&
keyType.isEqual(that.key, key);
}
...
}
When an entity state becomes Managed, it means it is stored in this entitiesByUniqueKey Java Map.
So, in JPA and Hibernate, the first-level cache is a Java
Map, in which theMapkey represented by an object that encapsulates the entity name and its identifier, and theMapvalue is the entity object itself.Therefore, in a JPA
EntityManageror HibernateSession, there can be only one and only one entity stored using the same identifier and entity class type.
The reason why we can have at most one representation of an entity stored in the first-level cache is that, otherwise, we could end up having different representations of the same database row without knowing which one is the right version that should be synchronized with the associated database record.
Transactional-write behind cache
To understand the benefits of using the first-level cache, it’s important to understand how the transactional write-behind cache strategy works.
As already explained, the persist, merge, and remove methods of the JPA EntityManager change the state of a given entity. However, the entity state is not synchronized every time an EntityManager method is called. In reality, the state changes are only synchronized when the flush EntityManager method is executed.
This cache synchronization strategy is called write-behind and looks as follows:

The advantage of using a write-behind strategy is that we can batch multiple entities when flushing the first-level cache.
The write-behind strategy is actually very common. The CPU has first, second, and third-level caches as well. And, when a registry is changed, its state is not synchronized with the main memory unless a flush is executed.
Also, as explained in this article, a relational database system maps the OS pages to the Buffer Pool in-memory pages, and, for performance reasons, the Buffer Pool is synchronized periodically during a checkpoint and not on every transaction commit.
Application-level repeatable reads
When you are fetching a JPA entity, either directly:
Post post = entityManager.find(Post.class, 1L);
Or, via a query:
Post post = entityManager.createQuery("""
select p
from Post p
where p.id = :id
""", Post.class)
.setParameter("id", 1L)
.getSingleResult();
A Hibernate LoadEntityEvent is going to be triggered. The LoadEntityEvent is handled by the DefaultLoadEventListener, which will load the entity as follows:
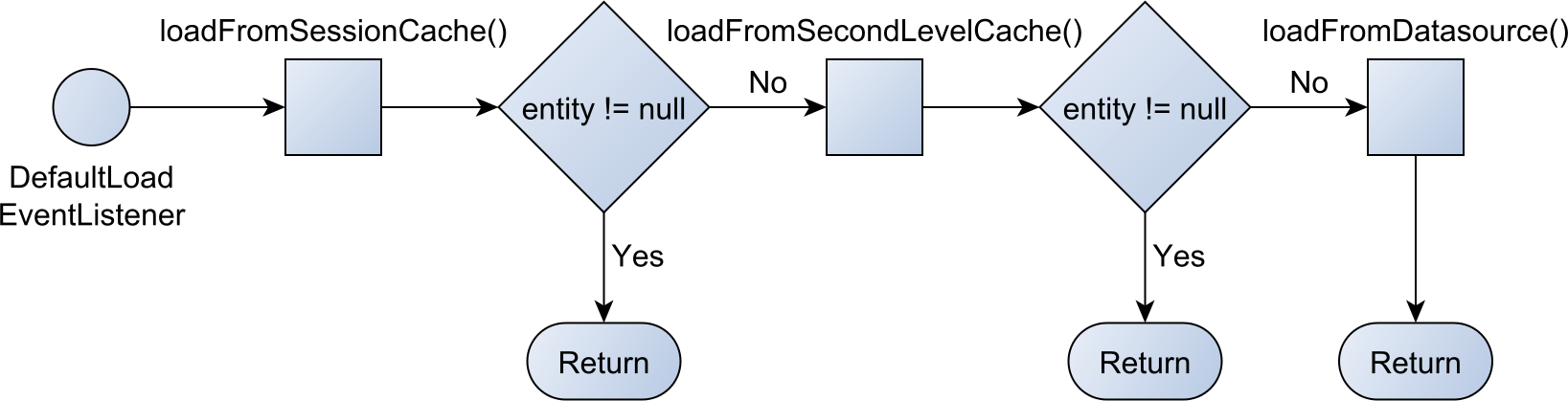
First, Hibernate checks whether the entity is already stored in the first-level cache, and if it is, the currently managed entity reference is returned.
If the JPA entity is not found in the first level-cache, Hibernate will check the second-level cache if this cache is enabled.
If the entity is not found in the first or second-level cache, then Hibernate will load it from the database using an SQL query.
The first-level cache provides application-level repeatable reads guarantee for entities because no matter how many times the entity is loaded from the Persistence Context, the same managed entity reference will be returned to the caller.
When the entity is loaded from the database, Hibernate takes the JDBC ResultSet and transforms it into a Java Object[] that’s known as the entity loaded state. The loaded state is stored in the first-level cache along with the managed entity, as illustrated by the following diagram:
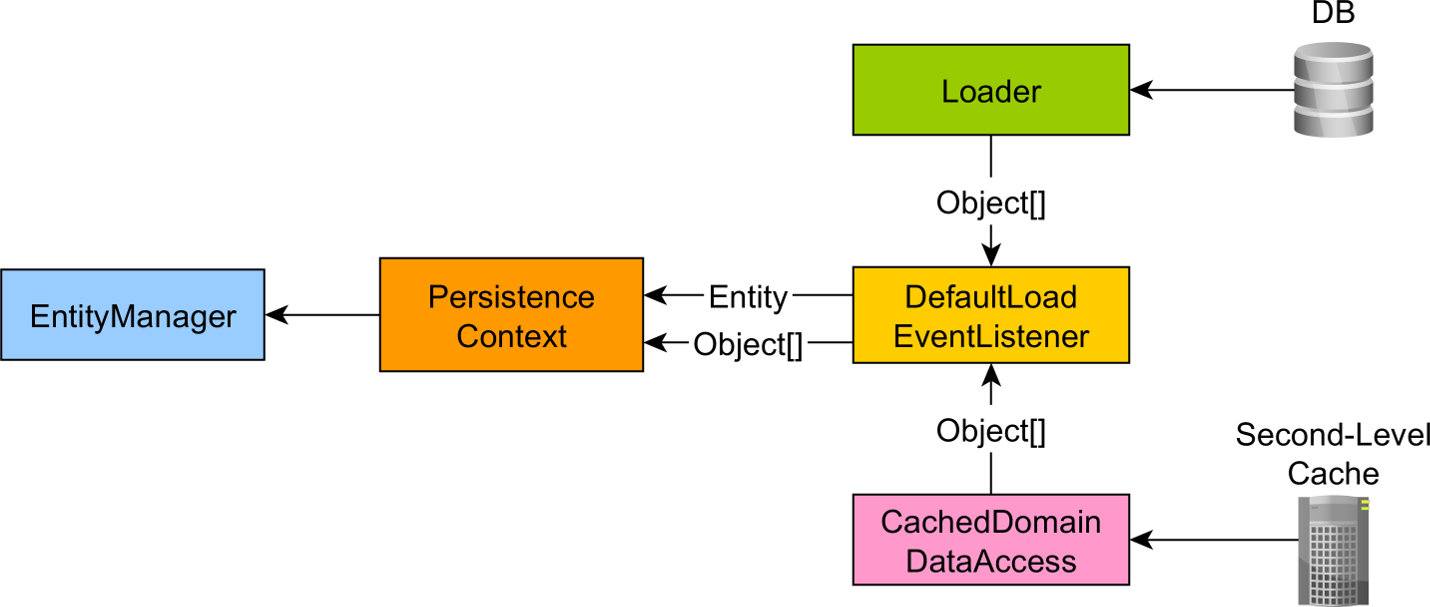
As you can see from the diagram above, the second-level cache stores the loaded state, so when loading an entity that was previously stored in the second-level cache, we can get the loaded state without having to execute the associated SQL query.
For this reason, the memory impact of loading an entity is larger than the Java entity object itself since the loaded state needs to be stored as well. When flushing the JPA Persistence Context, the loaded state will be used by the dirty checking mechanism to determine whether the entity has changed since it was first loaded. If the entity has changed, an SQL UPDATE will be generated.
So, if you are not planning to modify the entity, then it’s more efficient to load it in read-only mode as the loaded state will be discarded after instantiating the entity object.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The first-level cache is a mandatory construct in JPA and Hibernate. Since the first-level cache is bound to the currently executing thread, it cannot be shared among multiple users. For this reason, the JPA and Hibernate the first-level cache is not thread-safe.
Apart from providing application-level repeatable reads, the first-level cache can batch multiple SQL statements at flush time, therefore improving read-write transaction response time.
However, while it prevents multiple find calls from fetching the same entity from the database, it cannot prevent a JPQL or SQL from loading the latest entity snapshot from the database, only to discard it upon assembling the query result set.










That is a great articles. Thank you so much for explaining.
If you liked these articles, you are going to love my book.