Clustered Index
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see what a Clustered Index is and why it’s very important to understand how tables are organized when using a relational database system.
B+ Tree
The most common index used in a relational database system is the B+ Tree one. Like the B-Tree index, the B+ Tree is a self-balanced ordered tree data structure.
Both the B-Tree and the B+Tree start from a Root node and may have Internal Nodes and Leaf Nodes. However, unlike the B-Tree, the B+ Tree stores all the keys in the leaf nodes, and the adjacent Leaf nodes are linked via pointers, which simplifies range scans.
Without an index, whenever we are looking for a given column value, we’d need to scan all the table records and compare each column value against the provided one. The larger the table, the more pages will have to be scanned in order to find all the matching records.
On the other hand, if the column value is highly selective (e.g., a small number of records match that column value), using a B+Tree index allows us to locate a column value much faster since fewer pages will be needed to be scanned.
Clustered Index
A Clustered Index is basically a tree-organized table. Instead of storing the records in an unsorted Heap table space, the clustered index is basically a Primary Key B+Tree index whose Leaf Nodes, which are ordered by the clusters key column value, store the actual table records, as illustrated by the following diagram.
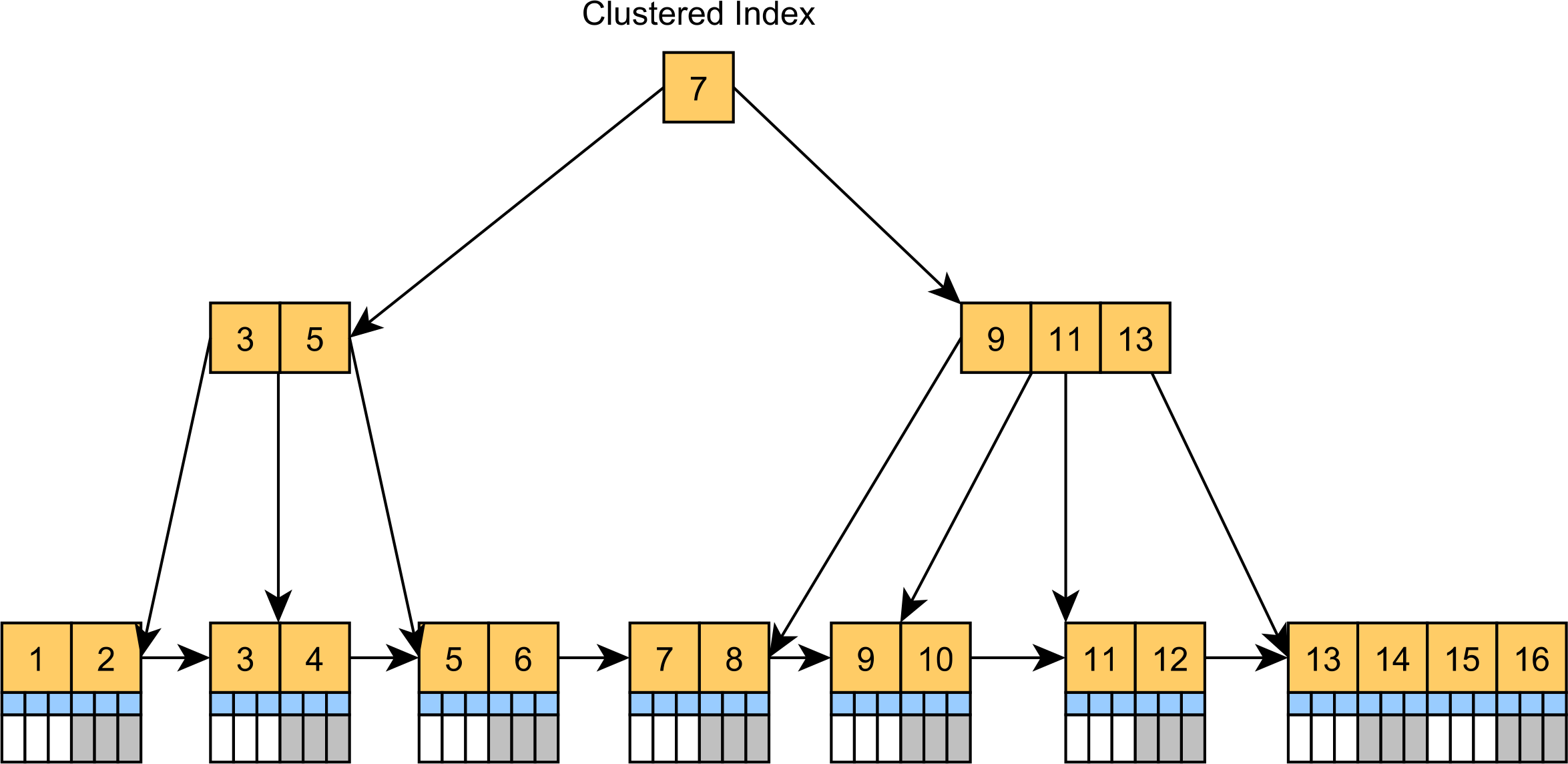
The Clustered Index is the default table structure in SQL Server and MySQL. While MySQL adds a hidden clusters index even if a table doesn’t have a Primary Key, SQL Server always builds a Clustered Index if a table has a Primary Key column. Otherwise, the SQL Server is stored as a Heap Table.
The Clustered Index can speed up queries that filter records by the clustered index key, like the usual CRUD statements. Since the records are located in the Leaf Nodes, there’s no additional lookup for extra column values when locating records by their Primary Key values.
For example, when executing the following SQL query on SQL Server:
SELECT PostId, Title FROM Post WHERE PostId = ?
You can see that the Execution Plan uses a Clustered Index Seek operation to locate the Leaf Node containing the Post record, and there are only two logical reads required to scan the Clustered Index nodes:
|StmtText | |-------------------------------------------------------------------------------------| |SELECT PostId, Title FROM Post WHERE PostId = @P0 | | |--Clustered Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[PK_Post_Id]), | | SEEK:([high_performance_sql].[dbo].[Post].[PostID]=[@P0]) ORDERED FORWARD) | Table 'Post'. Scan count 0, logical reads 2, physical reads 0
Clustered and Secondary Index
Since the Clustered Index is built using the Primary Key column values, if you want to speed up queries that use some other column, then you’ll have to add a Secondary Index.
The Secondary Index is going to store the Primary Key value in its Leaf Nodes, as illustrated by the following diagram:

So, if we create a Secondary Index on the Title column of the Post table:
CREATE INDEX IDX_Post_Title on Post (Title)
And we execute the following SQL query:
SELECT PostId, Title FROM Post WHERE Title = ?
We can see that an Index Seek operation is used to locate the Leaf Node in the IDX_Post_Title index that can provide the SQL query projection we are interested in:
|StmtText | |------------------------------------------------------------------------------| |SELECT PostId, Title FROM Post WHERE Title = @P0 | | |--Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[IDX_Post_Title]),| | SEEK:([high_performance_sql].[dbo].[Post].[Title]=[@P0]) ORDERED FORWARD)| Table 'Post'. Scan count 1, logical reads 2, physical reads 0
Since the associated PostId Primary Key column value is stored in the IDX_Post_Title Leaf Node, this query doesn’t need an extra lookup to locate the Post row in the Clustered Index.
On the other hand, if an SQL query using a Secondary Index returns a projection that needs additional column values that are not located in the Leaf Node of the Secondary Index, then the Clustered Index will have to be traversed as well. In SQL Server, this process is called a Bookmark Lookup.
So, if we execute a SQL query that reads the CreatedOn column that’s not included in the IDX_Post_Title Secondary Index:
SELECT PostId, CreatedOn FROM Post WHERE Title = ?
We can see that an Index Seek operation is used first to locate the Leaf Node in the IDX_Post_Title index that matched the provided Title, followed by a Clustered Index Seek to locate the Leaf Node where the Post record resides so that we can read the CreatedOn column value:
|StmtText | |----------------------------------------------------------------------------------------------| |SELECT PostId, CreatedOn FROM Post WHERE Title = @P0 | | |--Nested Loops(Inner Join, OUTER REFERENCES:([high_performance_sql].[dbo].[Post].[PostID]))| | |--Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[IDX_Post_Title]), | | SEEK:([high_performance_sql].[dbo].[Post].[Title]=[@P0]) ORDERED FORWARD) | | |--Clustered Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[PK_Post_Id]), | | SEEK:([high_performance_sql].[dbo].[Post].[PostID]= | | [high_performance_sql].[dbo].[Post].[PostID]) LOOKUP ORDERED FORWARD) | Table 'Post'. Scan count 1, logical reads 4, physical reads 0
And, since both the Secondary Index and the Clustered Index are traversed, 4 logical reads are needed this time.
For this reason, some relational database systems, like SQL Server, provide the INCLUDE clause to add extra column values in the secondary index Leaf Nodes so that you can avoid the Bookmark Lookup overhead.
In our case, we can change the IDX_Post_Title Index to include the CreatedOn column, like this:
CREATE NONCLUSTERED INDEX IDX_Post_Title ON Post (Title) INCLUDE (CreatedOn);
And, when running the previous SQL query:
SELECT PostId, CreatedOn FROM Post WHERE Title = ?
The Execution Plan changes to a single Index Seek on the IDX_Post_Title Secondary Index since there’s no need to traverse the Clustered Index to locate the CreatedOn column anymore:
|StmtText | |------------------------------------------------------------------------------| |SELECT PostId, CreatedOn FROM Post WHERE Title = @P0 | | |--Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[IDX_Post_Title]),| | SEEK:([high_performance_sql].[dbo].[Post].[Title]=[@P0]) ORDERED FORWARD)| Table 'Post'. Scan count 1, logical reads 2, physical reads 0
Clustered Index column size
Because the Clustered Index Key is stored in every Secondary Index, it’s very important that the Primary Key column is as compact as possible.
For instance, if you have an Employee table, there’s no need to use a bigint column as a Primary Key since an int column can accommodate over 4 billion entries, and it’s very unlikely that the company you are modeling is going to have more than 4 billion employees.
Since an int column value requires 4 bytes of storage while the bigint requires 8 bytes, you are going to save a lot of space both in the Clustered Index and all the associated Secondary Indexes.
Using the most compact column types that can still accommodate all possible values is even more important when you are thinking of the Buffer Pool. Without caching the working set in memory, queries will need a lot of disk access, which is orders of magnitude slower than RAM.
Clustered Index column monotonicity
Since B+Tree indexes are self-balanced, it’s important to choose a Primary Key column whose values are monotonically increasing for many good reasons.
First, the Leaf Node can accommodate multiple records, and adding each record one after the other will ensure a high page fill factor and a low number of pages needed to store all the records. On the other hand, if you’re using a UUID Primary Key column, a new UUID value might not find any existing Leaf Page, so more and more Leaf Pages will be allocated and filled only partially.
Second, as explained in this Percona article inserting Clustered Index entries in random order can cause many page splits, which requires more index maintenance work from the database engine.
Third, if the Clustered Index is very large and doesn’t fit entirely in memory, it’s very convenient to use monotonically increasing Primary Key values since the likelihood of finding the page cached in the Buffer Pool is higher than if the Primary Key value is randomly generated and the associated Leaf Node has been removed from the Buffer Pool.
For more details about why the standard UUIDs are not a good fit for Primary Keys and why you should use a time-sorted TSID instead, check out this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Understanding how a Clustered Index works is very important if you are using MySQL or SQL Server because this is the default table data structure.
Choosing a monotonically increasing Clustered Index key that’s also reasonably compact is going to provide better performance than using randomly allocated column values like it’s the case of UUID columns.
Also, for SQL Server, if you want to avoid Bookmark Lookups, you can use the INCLUDE clause when defining a non-clustered index that’s aimed to serve a given set of queries that require additional columns that are not used for filtering.








