The best UUID type for a database Primary Key
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see what UUID (Universally Unique Identifier) type works best for a database column that has a Primary Key constraint.
While the standard 128-bit random UUID is a very popular choice, you’ll see that this is a terrible fit for a database Primary Key column.
Standard UUID and database Primary Key
A universally unique identifier (UUID) is a 128-bit pseudo-random sequence that can be generated independently without the need for a single centralized system in charge of ensuring the identifier’s uniqueness.
The RFC 4122 specification defines five standardized versions of UUID, which are implemented by various database functions or programming languages.
For instance, the UUID() MySQL function returns a version 1 UUID number.
And the Java UUID.randomUUID() function returns a version 4 UUID number.
For many devs, using these standard UUIDs as a database identifier is very appealing because:
- The ids can be generated by the application. Hence no central coordination is required.
- The chance of identifier collision is extremely low.
- The id value being random, you can safely send it to the UI as the user would not be able to guess other identifier values and use them to see other people’s data.
But, using a random UUID as a database table Primary Key is a bad idea for multiple reasons.
First, the UUID is huge. Every single record will need 16 bytes for the database identifier, and this impacts all associated Foreign Key columns as well.
Second, the Primary Key column usually has an associated B+Tree index to speed up lookups or joins, and B+Tree indexes store data in sorted order.
However, indexing random values using B+Tree causes a lot of problems:
- Index pages will have a very low fill factor because the values come randomly. So, a page of 8kB will end up storing just a few elements, therefore wasting a lot of space, both on the disk and in the database memory, as index pages could be cached in the Buffer Pool.
- Because the B+Tree index needs to rebalance itself in order to maintain its equidistant tree structure, the random key values will cause more index page splits and merges as there is no pre-determined order of filling the tree structure.
If you’re using SQL Server or MySQL, then it’s even worse because the entire table is basically a clustered index.
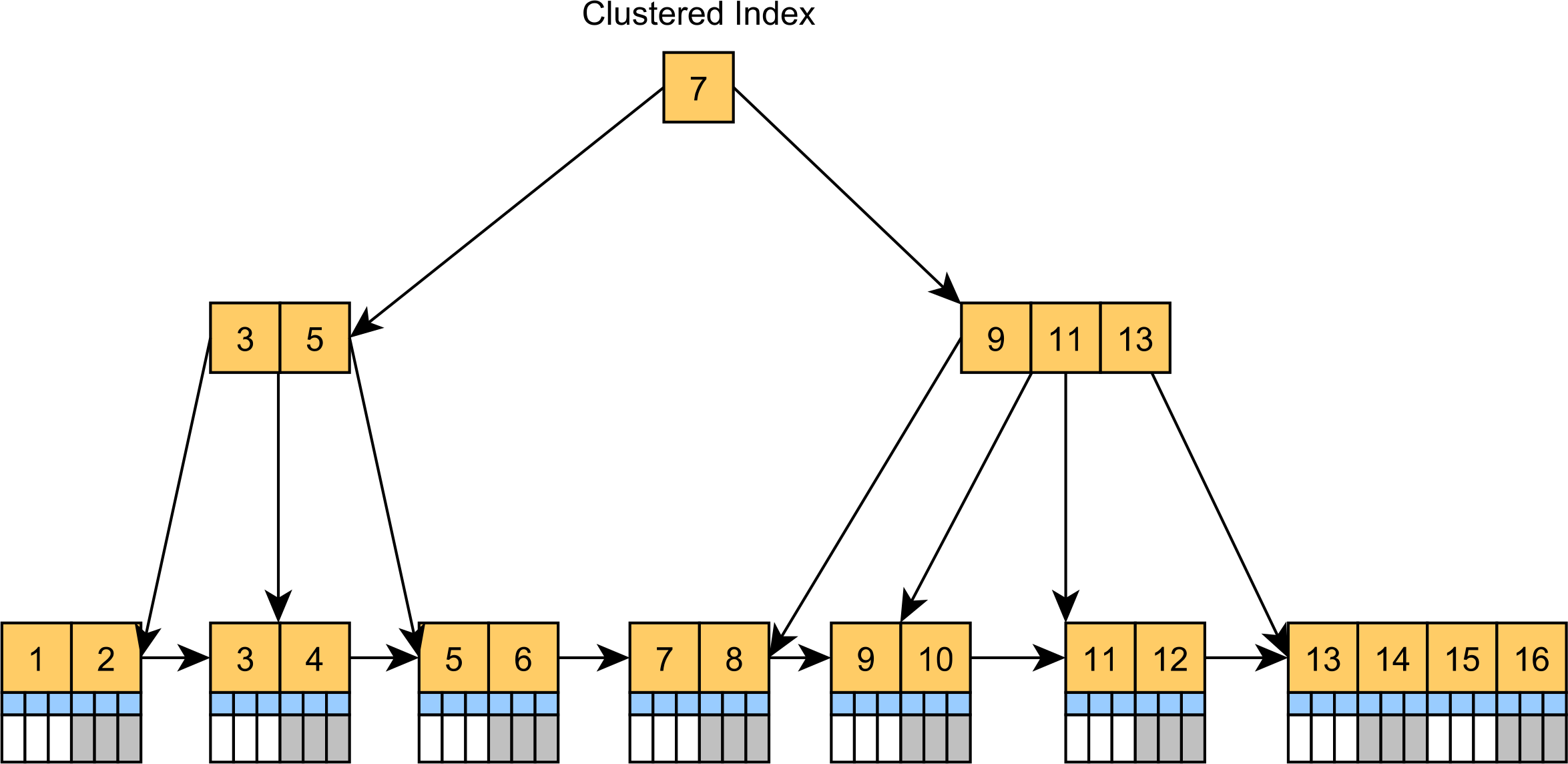
And all these problems will affect the secondary indexes as well because they store the Primary Key value in the secondary index leaf nodes.

In fact, almost any database expert will tell you to avoid using the standard UUIDs as database table Primary Keys:
- Percona: UUIDs are Popular, but Bad for Performance
- UUID or GUID as Primary Keys? Be Careful!
- Identity Crisis: Sequence v. UUID as Primary Key
TSID – Time-Sorted Unique Identifiers
If you plan to store UUID values in a Primary Key column, then you are better off using a TSID (time-sorted unique identifier).
One such implementation is offered by the Hypersistence TSID OSS library, which provides a 64-bit TSID that’s made of two parts:
- a 42-bit time component
- a 22-bit random component
The random component has two parts:
- a node identifier (0 to 20 bits)
- a counter (2 to 22 bits)
The node identifier can be provided by the tsid.node system property when bootstrapping the application:
-Dtsid.node="12"
The node identifier can also be provided via the TSID_NODE environment variable:
export TSID_NODE="12"
The library is available on Maven Central, so you can get it via the following dependency:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-tsid</artifactId>
<version>${hypersistence-tsid.version}</version>
</dependency>
You can create a TSID object like this:
TSID tsid = TSID.fast();
From the Tsid object, we can extract the following values:
- the 64-bit numerical value,
- the Crockford’s Base32 String value that encodes the 64-bit value,
- the Unix milliseconds since epoch that is stored in the
42-bit sequence
To visualize these values, we can print them into the log:
long tsidLong = tsid.toLong();
String tsidString = tsid.toString();
long tsidMillis = tsid.getUnixMilliseconds();
LOGGER.info(
"TSID numerical value: {}",
tsidLong
);
LOGGER.info(
"TSID string value: {}",
tsidString
);
LOGGER.info(
"TSID time millis since epoch value: {}",
tsidMillis
);
And we get the following output:
TSID numerical value: 470157774998054993 TSID string value: 0D1JP05FJBA2H TSID time millis since epoch value: 1689931148668
When generating ten values:
for (int i = 0; i < 10; i++) {
LOGGER.info(
"TSID numerical value: {}",
TSID.fast().toLong()
);
}
We can see that the values are monotonically increasing:
TSID numerical value: 470157775044192338 TSID numerical value: 470157775044192339 TSID numerical value: 470157775044192340 TSID numerical value: 470157775044192341 TSID numerical value: 470157775044192342 TSID numerical value: 470157775044192343 TSID numerical value: 470157775044192344 TSID numerical value: 470157775048386649 TSID numerical value: 470157775048386650 TSID numerical value: 470157775048386651
Awesome, right?
Using the TSID in your application
Because the default TSID factories come with a synchronized random value generator, it’s better to use a custom TsidFactory that provides the following optimizations:
- It can generate the random values using a
ThreadLocalRandom, therefore avoiding Thread blocking on synchronized blocks - It can use a small number of node bits, therefore leaving us more bits for the random-generated numerical value.
So, we can define the following TsidUtil that provides us a TsidFactory to use whenever we want to generate a new TSID object:
public class TsidUtils {
public static final String TSID_NODE_COUNT_PROPERTY =
"tsid.node.count";
public static final String TSID_NODE_COUNT_ENV =
"TSID_NODE_COUNT";
⠀
public static TSID.Factory TSID_FACTORY;
⠀
static {
String nodeCountSetting = System.getProperty(
TSID_NODE_COUNT_PROPERTY
);
if (nodeCountSetting == null) {
nodeCountSetting = System.getenv(
TSID_NODE_COUNT_ENV
);
}
⠀
int nodeCount = nodeCountSetting != null ?
Integer.parseInt(nodeCountSetting) :
256;
⠀
TSID_FACTORY = getTsidFactory(nodeCount);
}
⠀
private TsidUtils() {
throw new UnsupportedOperationException(
"TsidUtils is not instantiable!"
);
}
⠀
public static TSID randomTsid() {
return TSID_FACTORY.generate();
}
⠀
public static TSID.Factory getTsidFactory(int nodeCount) {
int nodeBits = ((int) (Math.log(nodeCount) / Math.log(2))) + 1;
⠀
return TSID.Factory.builder()
.withRandomFunction(
TSID.Factory.THREAD_LOCAL_RANDOM_FUNCTION
)
.withNodeBits(nodeBits)
.build();
}
⠀
public static TSID.Factory getTsidFactory(int nodeCount, int nodeId) {
int nodeBits = ((int) (Math.log(nodeCount) / Math.log(2))) + 1;
⠀
return TSID.Factory.builder()
.withRandomFunction(TSID.Factory.THREAD_LOCAL_RANDOM_FUNCTION)
.withNodeBits(nodeBits)
.withNode(nodeId)
.build();
}
}
When running this test case that operates 16 threads on 2 nodes:
int threadCount = 16;
int iterationCount = 100_000;
CountDownLatch endLatch = new CountDownLatch(threadCount);
ConcurrentMap<TSID, Integer> tsidMap = new ConcurrentHashMap<>();
long startNanos = System.nanoTime();
AtomicLong collisionCount = new AtomicLong();
int nodeCount = 2;
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
TSID.Factory tsidFactory = TsidUtils.getTsidFactory(
nodeCount,
threadId % nodeCount
);
⠀
for (int j = 0; j < iterationCount; j++) {
TSID tsid = tsidFactory.generate();
Integer existingTsid = tsidMap.put(
tsid,
(threadId * iterationCount) + j
);
if(existingTsid != null) {
collisionCount.incrementAndGet();
}
}
⠀
endLatch.countDown();
}).start();
}
LOGGER.info("Starting threads");
endLatch.await();
LOGGER.info(
"{} threads generated {} TSIDs in {} ms with {} collisions",
threadCount,
new DecimalFormat("###,###,###").format(
threadCount * iterationCount
),
TimeUnit.NANOSECONDS.toMillis(
System.nanoTime() - startNanos
),
collisionCount
);
We get the following result:
16 threads generated 1,600,000 TSIDs in 1179 ms with 0 collisions
The thread id is included in the random part, so up to 256 threads there shouldn’t be any collisions when generating the TSID.
In the unlikely case that you get a collision and you end up with a constraint violation, you can use the
@Retryannotation to retry the business method and avoid the collision to propagate to the client.Check out this article for more details about how you can use the
@Retryannotation.
Using the TSID as a Primary Key value
Since the TSID is a time-sorted 64-bit number, the best way to store it in the database is to use a bigint column type:
CREATE TABLE post (
id bigint NOT NULL,
title varchar(255),
PRIMARY KEY (id)
)
And on the application side, you need to use a 64-bit number, like the Java Long object type:
@Entity
@Table(name = "post")
public class Post {
⠀
@Id
private Long id;
⠀
private String title;
}
That’s it!
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Using the standard UUID as a Primary Key value is not a good idea unless the first bytes are monotonically increasing.
For this reason, using a time-sorted TSID is a much better idea. Not only that it requires half the number of bytes as a standard UUID, but it fits better as a B+Tree index key.
While SQL Server offers a time-sorted GUID via the NEWSEQUENTIALID, the size of the GUID is 128 bits, so it’s twice as large as a TSID.
The same issue is with version 7 of the UUID specification, which provides a time-sorted UUID. However, it uses the same canonical format (128 bits) which is way too large. The impact of the Primary Key column storage is amplified by every referencing Foreign Key columns.
If all your Primary keys are 128-bit UUIDs, then the Primary Key and Foreign Key indexes are going to require a lot of space, both on the disk and in the database memory, as the Buffer Pool holds both table and index pages.









You should convert any 64-bit identifiers (like TSID, but also SnowFlakeID, NanoID, end Mongo’s ObjectID) to a String before sending them to a javascript frontend as JSON. That is because JavaScript uses IEEE754 (64 bits) for numbers, giving you 53-bit precision. As stipulated here: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number#integer_range_for_number, any integer values falling outside of this range can be expected to become corrupted when the JSON parser coerces them to Number type.
This can be done using the TSID.encode/decode or TSID.format/unformat methods
Thanks for the tip
Thanks for a great article! So I have a question, my springboot application runs with multiple pods using k8s. So if I use TSID to generate random strings to generate unique keys for requests and store them in the database. So does TSID ensure the creation of a unique chain when there are many requests performed simultaneously on different pods? Thank you.
If you use the nodeID, then you can be sure that there won’t be any conflicts.
Hi all, does anyone have a standard implementation of the functions to transform the TSID from string to bigint and vice versa in MySQL?
It is always a bit time-consuming to track down the numeric ID (long/bigint) when testing or debugging if I only have the string version of the record (exposed to the public via web).
Thank you very much
The
hypersistence-tsidproject allows you to generate theLongTSID so that you don’t have to convert it from String.In MySQL, you can use the
CONVfunction in MySQL to try to convert from base 32 to base 10, like thisCONV(tsid_column, 32, 10).Very interesting, thanks for sharing. I have not read this article before, but came upon this page describing the problem: https://www.cybertec-postgresql.com/en/unexpected-downsides-of-uuid-keys-in-postgresql/. Since we generate the ID in the Java app, I added a hack on top of UUID.random(), taking System.currentTimeMillis(), shifting it by 22 bits (the top 22 bits of the 64-bit value will be the same until the year 2109, so provide no info), and using them to replace the top 42 bits of the UUID (the variant and version bits are stored elsewhere, already generated correctly by Javas UUID.random()).
Another good Postgres-specific analysis is here: https://buildkite.com/blog/goodbye-integers-hello-uuids.
Of course that does not solve the size issue, so kudos for pointing me to TSID!
You’re welcome and stay tuned for more.
Thanks for the another great article ! I have a question about TSID and… database data-fixing scripts. Let’s say that there is a need to add a record manually to a database – what will be the best way of generating TSID (or something TSID-like) in a SQL script?
You can try to use one SQL script available on the Internet.
Great article, Vlad! Just a comment for the MySQL users: MySQL can generate timestamp-based (type 1) UUIDs. Those can be stored in binary form with their time-low and time-high parts swapped. This addresses most storage and query performance concerns.
That’s good to know.