Spring Data JPA MultipleBagFetchException
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to show you how to handle the MultipleBagFetchException thrown by Hibernate upon simultaneously fetching multiple collections with Spring Data JPA.
MultipleBagFetchException
As I explained previously in this article, the MultipleBagFetchException is thrown by Hibernate when you try to fetch multiple List collections at once.
By trying to fetch multiple one-to-many or many-to-many associations at once, a Cartesian Product is generated, and, even if Hibernate didn’t throw the MultipleBagFetchException, we would still want to avoid getting a Cartesian Product in our query result set.
Domain Model
Let’s assume we have a Post parent entity that has a bidirectional @OneToMany association with the PostComment entity and a unidirectional @ManyToMany association with the Tagentity:
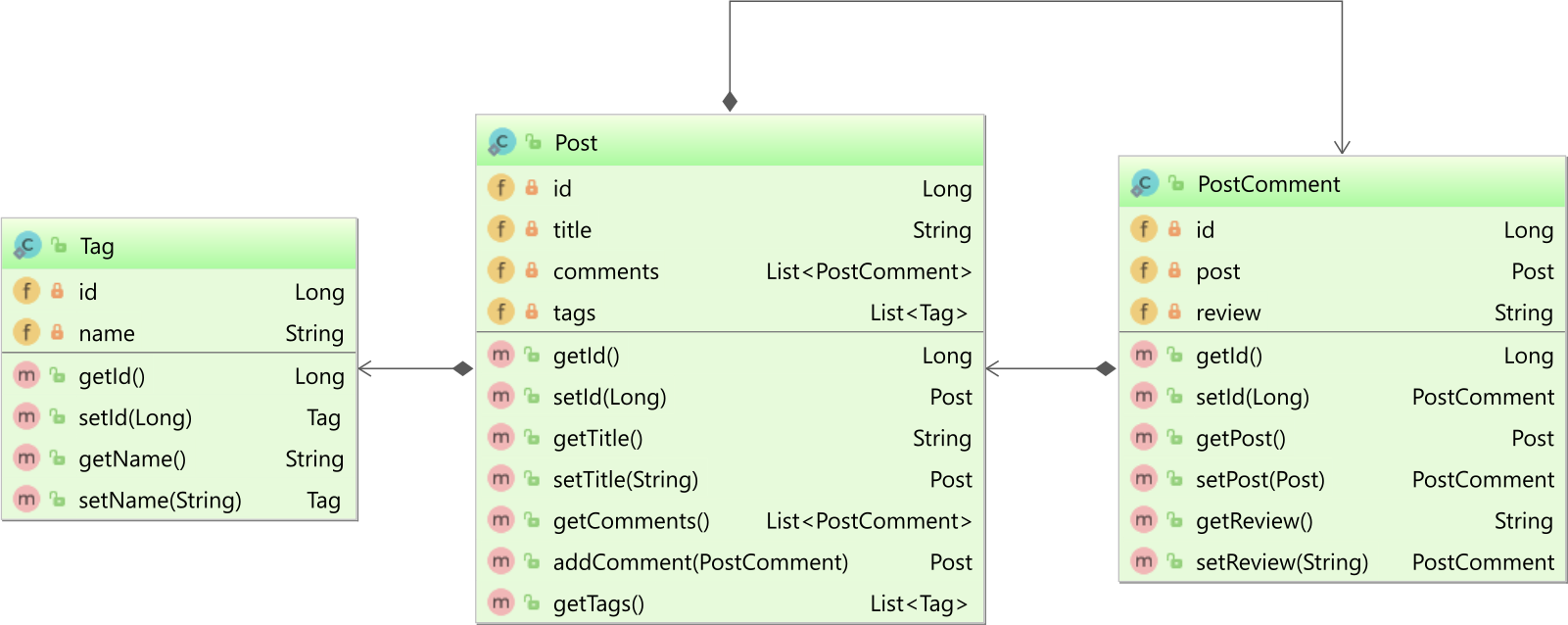
The Post entity has a comments collection and a tags collection, like this:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
⠀
@Id
private Long id;
⠀
private String title;
⠀
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
⠀
@ManyToMany(
cascade = {CascadeType.PERSIST, CascadeType.MERGE}
)
@JoinTable(name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();
}
Our goal is to fetch a number of Post entities along with their associated comments and tags collections.
Getting a MultipleBagFetchException using a Spring Data JPA Query annotation
The first approach one would take is to create a @Query method that uses JOIN FETCH on both the comments and tags collections, like in the following example:
@Repository
public interface PostRepository extends JpaRepository<Post, Long> {
⠀
@Query("""
select distinct p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithCommentsAndTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}
But, if you try to do that, your Spring application will not even start, throwing the following MultipleBagFetchException upon trying to create the JPA TypedQuery from the associated @Query annotation:
java.lang.IllegalArgumentException: org.hibernate.loader.MultipleBagFetchException:
cannot simultaneously fetch multiple bags: [
com.vladmihalcea.book.hpjp.spring.data.query.multibag.domain.Post.comments,
com.vladmihalcea.book.hpjp.spring.data.query.multibag.domain.Post.tags
]
at org.hibernate.internal.ExceptionConverterImpl
.convert(ExceptionConverterImpl.java:141)
at org.hibernate.internal.ExceptionConverterImpl
.convert(ExceptionConverterImpl.java:181)
at org.hibernate.internal.ExceptionConverterImpl
.convert(ExceptionConverterImpl.java:188)
at org.hibernate.internal.AbstractSharedSessionContract
.createQuery(AbstractSharedSessionContract.java:757)
at org.hibernate.internal.AbstractSharedSessionContract
.createQuery(AbstractSharedSessionContract.java:114)
at org.springframework.data.jpa.repository.query.SimpleJpaQuery
.validateQuery(SimpleJpaQuery.java:90)
at org.springframework.data.jpa.repository.query.SimpleJpaQuery
.<init>(SimpleJpaQuery.java:66)
at org.springframework.data.jpa.repository.query.JpaQueryFactory
.fromMethodWithQueryString(JpaQueryFactory.java:51)
How to fix the MultipleBagFetchException using a Spring Data JPA
So, while we can’t fetch both collections using a single JPA query, we can definitely use two queries to fetch all the data we need.
@Repository
public interface PostRepository extends JpaRepository<Post, Long> {
⠀
@Query("""
select distinct p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId
""")
List<Post> findAllWithComments(
@Param("minId") long minId,
@Param("maxId") long maxId
);
⠀
@Query("""
select distinct p
from Post p
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}
The findAllWithComments query will fetch the desired Post entities along with their associated PostComment entities, while the findAllWithTags query will fetch the Post entities along with their associated Tag entities.
Executing two queries will allow us to avoid the Cartesian Product in the query result set, but we’d have to aggregate the results so that we return a single collection of Post entries that contain both the comments and tags collections initialized.
And that’s where the Hibernate First-Level Cache or Persistence Context can help us achieve this goal.
The PostService defines a findAllWithCommentsAndTagsmethod that’s implemented as follows:
@Service
@Transactional(readOnly = true)
public class PostServiceImpl implements PostService {
⠀
@Autowired
private PostRepository postRepository;
⠀
@Override
public List<Post> findAllWithCommentsAndTags(
long minId, long maxId) {
⠀
List<Post> posts = postRepository.findAllWithComments(
minId,
maxId
);
⠀
return !posts.isEmpty() ?
postRepository.findAllWithTags(
minId,
maxId
) :
posts;
}
}
Since the @Transactional annotation is placed at the class level, all methods will inherit it. Therefore, the findAllWithCommentsAndTags service method is going to execute in a transactional context, meaning that both PostRepository method calls will happen in the context of the same Persistence Context.
For this reason, the findAllWithComments and findAllWithTags methods will basically return two List objects containing the very same Post object references since you can have at most one entity reference managed by a given Persistence context.
While the findAllWithComments method is going to fetch the Post entities and store them in the Persistence Context or First-Level Cache, the second method, findAllWithTags, will just merge the existing Post entities with the references fetched from the DB that now contain the tags collections initialized.
This way, both the comments and the tags collections are going to be fetched prior to returning the List of Post entities back to the service method caller.
In our integration test, we can verify that both collections have been initialized:
List<Post> posts = postService.findAllWithCommentsAndTags(
1L,
POST_COUNT
);
⠀
for (Post post : posts) {
assertEquals(
POST_COMMENT_COUNT,
post.getComments().size()
);
⠀
assertEquals(
TAG_COUNT,
post.getTags().size()
);
}
As you can see, we can read the size of the comments and tags collections even after the Persistence Context was closed since they’ve been fetched by the two entity query executed by the findAllWithCommentsAndTags service method.
YouTube Video
I also published a YouTube video about the best way to fetch multiple collections at once with Spring Data JDBC, Spring Data JPA, and Hibernate.
Using MULTISET
Another great way to fetch multiple collections at once with a single SQL query that does not produce an implicit Cartesian Product is to use MULTISET.
The first framework which introduced MULTISET was jOOQ, and if you’re interested in how you can use MULTISET with jOOQ, then check out this article.
Another framework that has also added support for MULTISET is Blaze Persistence. If you have a JPA application, Blaze Persistence is a great choice as it simply plugs into JPA offering a much better Criteria API, support for Keyset Pagination and MULTISET. If you’re interested in knowing how to use MULTISET with Blaze Persistence, check out this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Knowing how to deal with the MultipleBagFetchExceptionis very important when using Spring Data JPA, as eventually, you are going to bump into this issue.
By fetching at most one collection per query, not only that you can prevent this issue, but you will also avoid the SQL Cartesian Product that would be generated when executing a single SQL query that JOINs multiple unrelated one-to-many associations.









Just what I needed. It worked, thank you!
If you found this article useful, you are going to love my video courses.
This is one of the best articles I have ever read on this topic.
Many thanks for all the brilliant background information here and in all your other articles.
This is great stuff. I was investigating a performance issue – some requests were processed quite slowly. It took over 30 seconds to retrieve 400 objects.
The problem was that retrieving each object needed at least 15 selects, so I ended up with 6000+. Now after reading this article (and about three hours of trial and error), I rewrote the service so that only 17 selects are executed and 400 objects is returned in 1.5 seconds.
It’s a gamechanger. Thank you
I’m glad I could help