The best way to fix the Hibernate MultipleBagFetchException
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
If you’ve been using Hibernate for some time, there is a good chance you bumped into a MultipleBagFetchException issue:
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags
In this article, we are going to see the reason Hibernate throws the MultipleBagFetchException as well as the best way to solve this issue.
Domain Model
Let’s consider that our application defines three entities: Post, PostComment, and Tag, which are associated as in the following diagram:
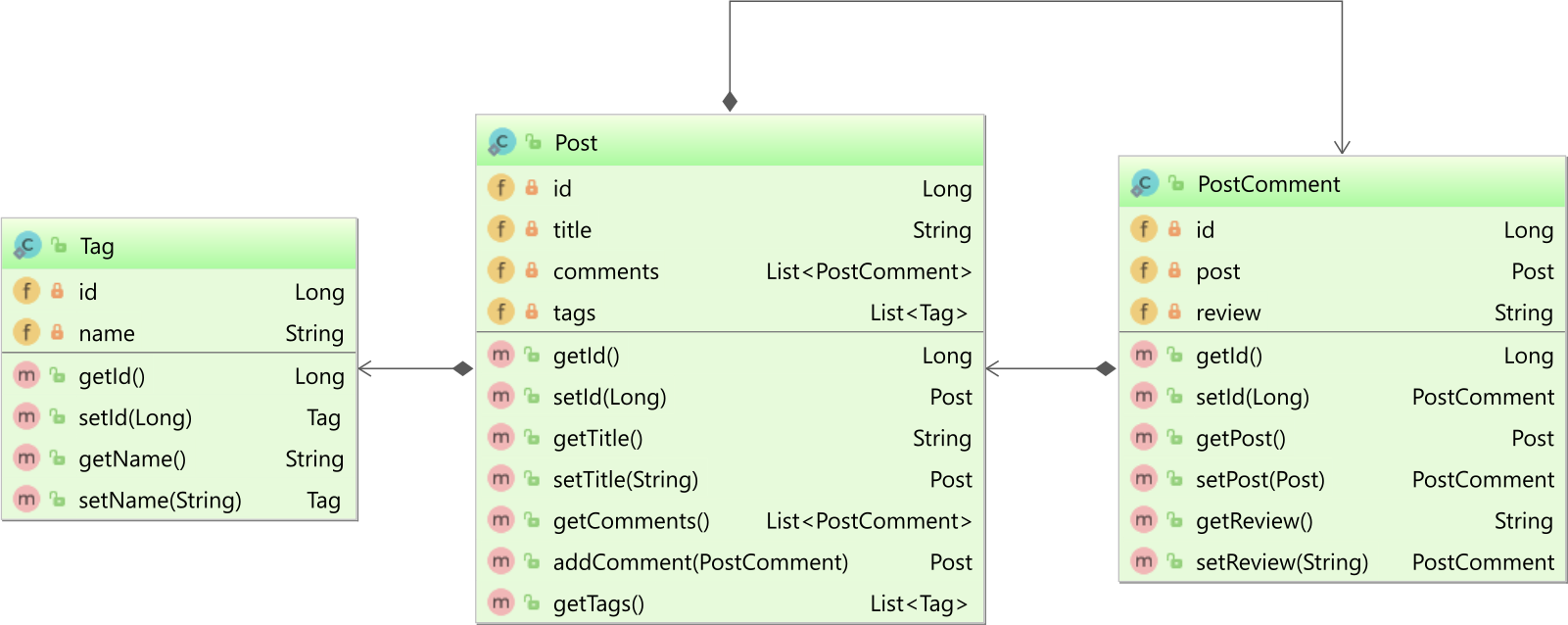
What we are mostly interested in this article is that the Post entity defines a bidirectional @OneToMany association with the PostComment child entity, as well as a unidirectional @ManyToMany association with the Tag entity.
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();
The reason why the
@ManyToManyassociation cascades only thePERSISTandMERGEentity state transitions and not theREMOVEone is because the other side is not a child entity.Since the
Tagentity lifecycle is not tied to thePostentity, cascadingREMOVEor enabling theorphanRemovalmechanism would be a mistake. For more details about this topic, check out this article.
Hibernate throwing MultipleBagFetchException
Now, if we want to fetch the Post entities with the identifier values between 1 and 50, along with all their associated PostComment and Tag entities, we would write a query like the following one:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();
However, when running the entity query above, Hibernate throws a MultipleBagFetchException while compiling the JPQL query:
MultipleBagFetchException: cannot simultaneously fetch multiple bags [ com.vladmihalcea.book.hpjp.hibernate.fetching.Post.comments, com.vladmihalcea.book.hpjp.hibernate.fetching.Post.tags ]
So, no SQL query is executed by Hibernate. The reason why a MultipleBagFetchException is thrown by Hibernate is that duplicates can occur, and the unordered List, which is called a bag in Hibernate terminology, is not supposed to remove duplicates.
How NOT to “fix” the Hibernate MultipleBagFetchException
If you google the MultipleBagFetchException, you are going to see many wrong answers, like this one on StackOverflow, which, surprisingly, has over 280 upvotes.

So simple, yet so wrong!
YouTube Video
I also published a YouTube video about the best way to fetch multiple collections at once with Spring Data JDBC, Spring Data JPA, and Hibernate.
Using Set instead of List
So, let’s change the association collection type from List to Set:
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private Set<PostComment> comments = new HashSet<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new HashSet<>();
And, now, when rerunning the previous entity query which fetched some Post entities along with their comments and tags associations, we can see that no MultipleBagFetchException is thrown.
However, this is SQL query that Hibernate executed for the aforementioned JPQL query:
SELECT
p.id AS id1_0_0_,
pc.id AS id1_1_1_,
t.id AS id1_3_2_,
p.title AS title2_0_0_,
pc.post_id AS post_id3_1_1_,
pc.review AS review2_1_1_,
t.name AS name2_3_2_,
pt.post_id AS post_id1_2_1__,
pt.tag_id AS tag_id2_2_1__
FROM
post p
LEFT OUTER JOIN
post_comment pc ON p.id = pc.post_id
LEFT OUTER JOIN
post_tag pt ON p.id = pt.post_id
LEFT OUTER JOIN
tag t ON pt.tag_id = t.id
WHERE
p.id BETWEEN 1 AND 50
So, what’s wrong with this SQL query?
The post and post_comment are associated via the post_id Foreign Key column, so the join produces a result set containing all post table rows with the Primary Key values between 1 and 50 along with their associated post_comment table rows.
The post and tag tables are also associated via the post_id and tag_id post_tag Foreign Key columns, so these two joins produce a result set containing all post table rows with the Primary Key values between 1 and 50 along with their associated tag table rows.
Now, to merge the two result sets, the database can only use a Cartesian Product, so the final result set contains 50 post rows multiplied by the associated post_comment and tag table rows.
So, if we have 50 post rows associated with 20 post_comment and 10 tag rows, the final result set will contain 10_000 records (e.g., 50 x 20 x 10), as illustrated by the following test case:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();
assertEquals(
POST_COUNT * POST_COMMENT_COUNT * TAG_COUNT,
posts.size()
);
That’s so terrible from a performance perspective!
If you want to see how you can fix the
MultipleBagFetchExceptionwhen using Spring Data JPA, then check out this article.
How to fix the Hibernate MultipleBagFetchException
To avoid a Cartesian Product, you can fetch at most one association at a time. So, instead of executing a single JPQL query that fetches two associations, we can execute two JPQL queries instead:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();
posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.tags t
where p in :posts""", Post.class)
.setParameter("posts", posts)
.getResultList();
assertEquals(POST_COUNT, posts.size());
for(Post post : posts) {
assertEquals(POST_COMMENT_COUNT, post.getComments().size());
assertEquals(TAG_COUNT, post.getTags().size());
}
The first JPQL query defines the main filtering criteria and fetches the Post entities along with the associated PostComment records.
Now, we have to fetch the Post entities along with their associated Tag entities, and, thanks to the Persistence Context, Hibernate will set the tags collection of the previously fetched Post entities.
Using MULTISET
Another way to fetch multiple collections at once using a single SQL query that does not produce an implicit Cartesian Product is to use MULTISET.
The first framework which introduced MULTISET was jOOQ, and if you’re interested in how you can use MULTISET with jOOQ, check out this article.
Another framework that has added support for MULTISET is Blaze Persistence, which is like a plugin or JPA and Hibernate. Using Blaze Persistence is very easy if you already have a JPA application. If you’re interested in knowing how to use MULTISET with Blaze Persistence, check out this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
There are so many blog posts, videos, books, and forum answers, providing the wrong solution to the MultipleBagFetchException Hibernate issues. All these resources tell you that using a Set instead of a List is the right way to avoid this exception.
However, the MultipleBagFetchException tells you that a Cartesian Product might be generated, and, most of the time, that’s undesirable when fetching entities as it can lead to terrible data access performance issues.
The best way to fetch multiple entity collections with JPA and Hibernate is to load at most one collection at a time while relying on the Hibernate Persistence Context guarantee that only a single entity object can be loading at a time in a given JPA EntityManager or Hibernate Session.









Thanks!! Never thought about the connection pool.
Sounds like you haven’t read the amazing High-Performance Java Peristence.
If you did, you’d know about the connection pools and hundreds of other tips that can help you get the most out of your database.