Optimistic vs. Pessimistic Locking
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to explain what is the difference between optimistic and pessimistic locking, as well as when you should employ one or the other concurrency control strategies.
Conflicts
At the Networking course in college, I learned that there are two ways of dealing with conflicts or collisions:
- detect and retry, and that’s exactly what Ethernet does
- avoid them by blocking other concurrent transmitters, just like Wi-Fi does.
Dealing with conflicts is actually the same even when using a database system.
We could allow the conflict to occur, but then we need to detect it upon committing our transaction, and that’s exactly how optimistic locking works.
If the cost of retrying is high, we could try to avoid the conflict altogether via locking, which is the principle behind how pessimistic locking works.
The Lost Update anomaly
Let’s consider the Lost Update anomaly, which can happen on any database running under the Read Committed isolation level:
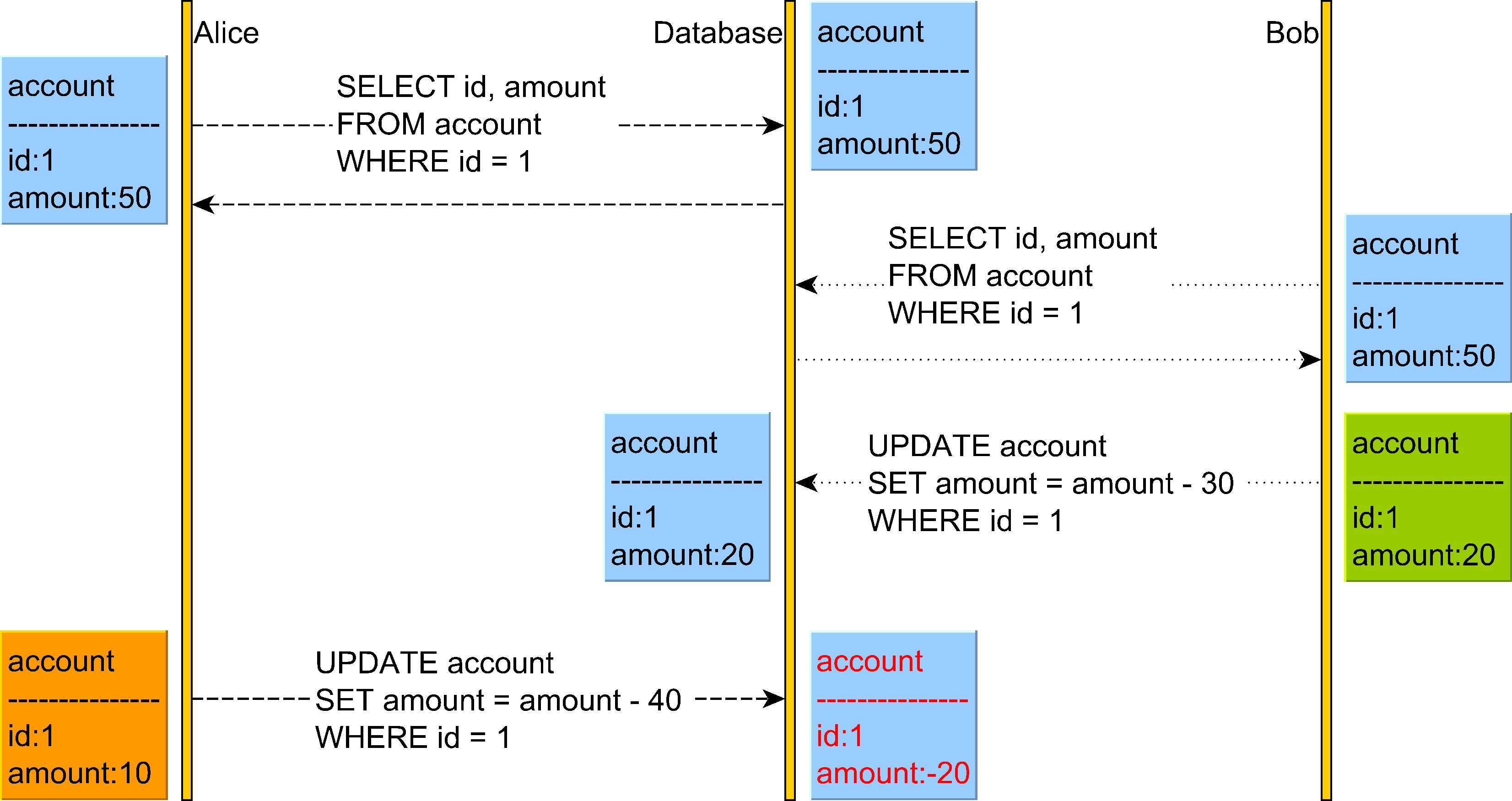
The diagram above illustrates the following situation:
- Alice reads the account balance, and the value is
50. - Right afterward, Bob changes the account balance from
50to20and commits. - Alice’s transaction is still running, and thinking that the account balance is still
50, she withdraws40thinking that the final balance will be10. - However, since the valance has changed, Alice’s UPDATE is going to leave the account balance in a negative value.
This transaction schedule is not Serializable because it’s neither equivalent to Alice’s reads and writes followed by Bob’s read and writes or Bob executing his transaction first followed by Alice executing her transaction right after.
The reads and the writes are interleaves, and that’s why the Lost Update anomaly is generated.
Pessimistic Locking
Pessimistic locking aims to avoid conflicts by using locking.

In the diagram above, both Alice and Bob will acquire a read (shared) lock on the account table row upon reading it.
Because both Alice and Bob hold the read (shared) lock on the account record with the identifier value of 1, neither of them can change it until one releases the read lock they acquired. This is because a write operation requires a write (exclusive) lock acquisition, and read (shared) locks prevent write (exclusive) locks.
For this reason, Bob’s UPDATE blocks until Alice releases the shared lock she has acquired previously.
When using SQL Server, the database acquires the shared locks automatically when reading a record under Repeatable Read or Serializable isolation level because SQL Server uses the 2PL (Two-Phase Locking) algorithm by default.
MySQL also uses pessimistic locking by default when using the Serializable isolation level and optimistic locking for the other less-strict isolation levels.
Optimistic Locking
Optimistic Locking allows a conflict to occur, but it needs to detect it at write time. This can be done using either a physical or a logical clock. However, since logical clocks are superior to physical clocks when it comes to implementing a concurrency control mechanism, we are going to use a version column to capture the read-time row snapshot information.
The version column is going to be incremented every time an UPDATE or DELETE statement is executed while also being used for matching the expected row snapshot in the WHERE clause.
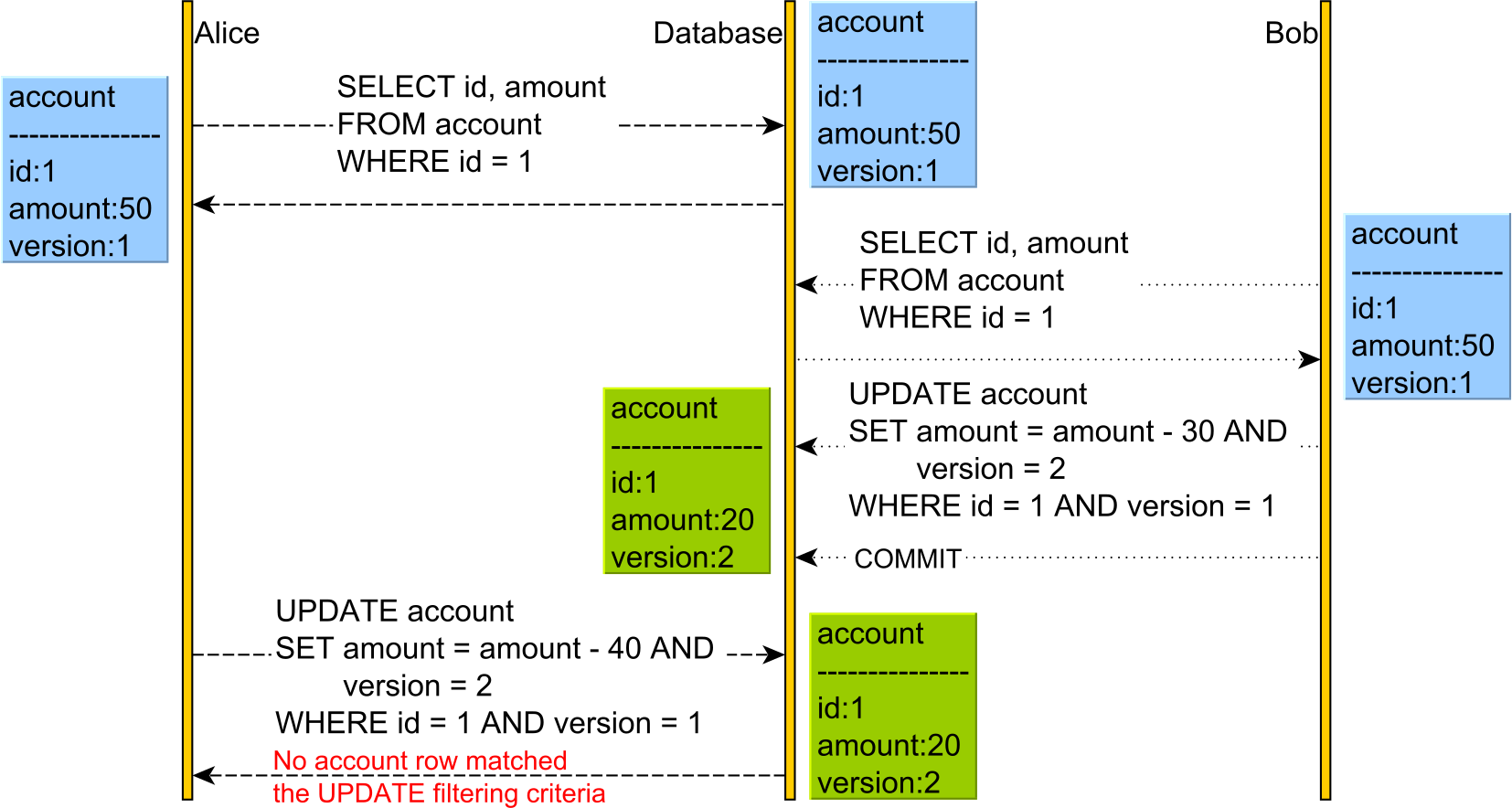
So, when reading the account record, both users read its current version. However, when Bob changes the account balance, he also changes the version from 1 to 2.
Afterward, when Alice wants to change the account balance, her UPDATE statement will not match any record since the version column value is no longer 1, but 2.
Therefore, the executeUpdate method of the UPDATE PreapredStatement is going to return a value of 0, meaning that no record was changed, and the underlying data access framework will throw an OptimisticLockException that will cause Alice’s transaction to rollback.
So, the Lost Update is prevented by rolling back the subsequent transactions that are operating on state data.
Nowadays, many relational database systems use optimistic locking to provide ACID guarantees. Oracle, PostgreSQL, and the InnoDB MySQL engine use MVCC (Multi-Version Concurrency Control), which is based on optimistic locking.
So, in MVCC, readers don’t block writers and writers don’t block readers, allowing conflicts to occur. However, at commit time, conflicts are detected by the transaction engine and the conflicting transactions are rolled back.
Application-level transactions
Relational database systems have emerged in the late ’70s and early ’80s when clients would connect to a mainframe via a terminal. However, nowadays, that’s not the case when using a web browser.
So, we no longer execute reads and writes in the context of the same database transaction, and Serializability is no longer sufficient to prevent a Lost Update in a long conversation.
For instance, considering we have the following use case:
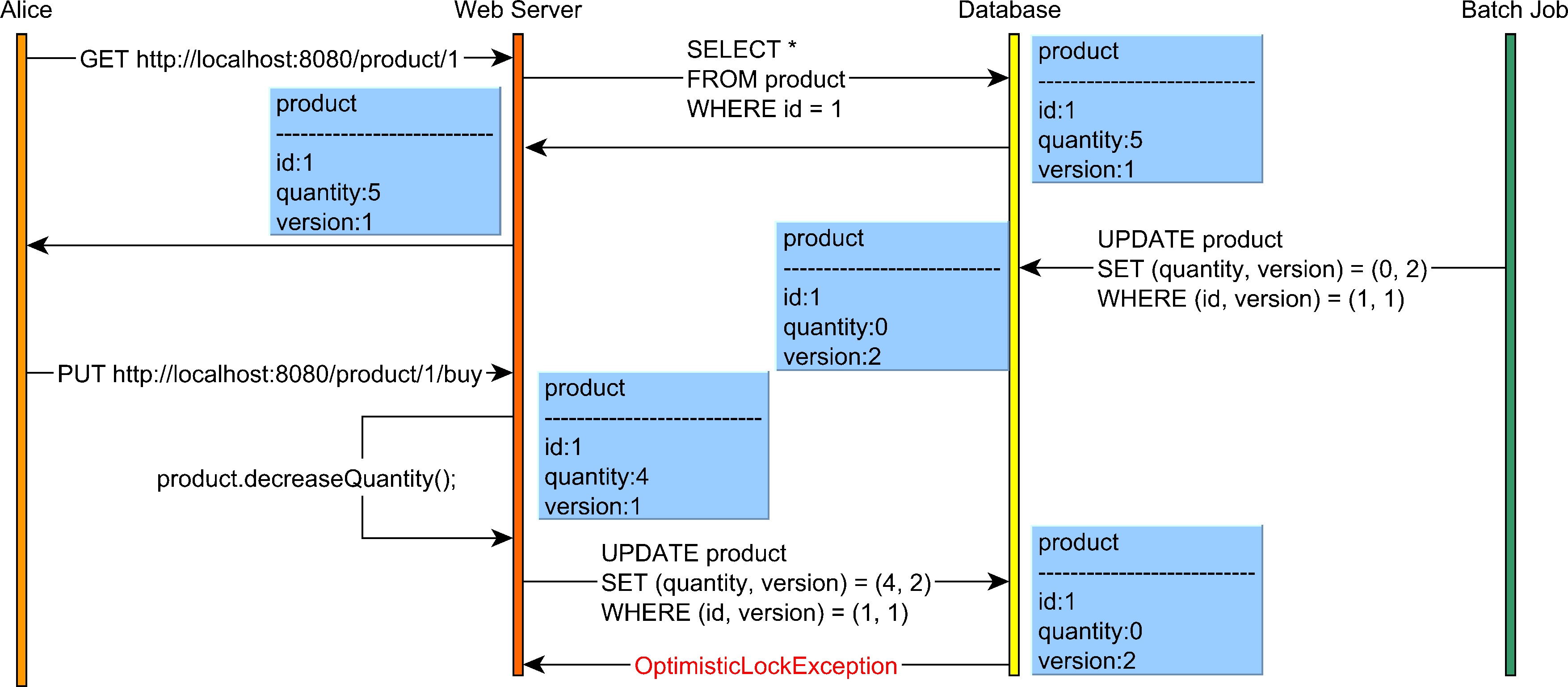
Pessimistic locking would not help us in this case since Alice’s read and the write happen in different HTTP requests and database transactions.
So, optimistic locking can help you prevent Lost Updates even when using application-level transactions that incorporate the user-think time as well.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Both pessimistic and optimistic locking are useful techniques. Pessimistic locking is suitable when the cost of retrying a transaction is very high or when contention is so large that many transactions would end up rolling back if optimistic locking were used.
On the other hand, optimistic locking works even across multiple database transactions since it doesn’t rely on locking physical records.









Thank you