A beginner’s guide to database deadlock
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see how a deadlock can occur in a relational database system, and how Oracle, SQL Server, PostgreSQL, or MySQL recover from a deadlock situation.
Database locking
Relational database systems use various locks to guarantee transaction ACID properties.
For instance, no matter what relational database system you are using, locks will always be acquired when modifying (e.g., UPDATE or DELETE) a certain table record. Without locking a row that was modified by a currently running transaction, Atomicity would be compromised.
Using locking for controlling access to shared resources is prone to deadlocks, and the transaction scheduler alone cannot prevent their occurrences.
Database deadlock
A deadlock happens when two concurrent transactions cannot make progress because each one waits for the other to release a lock, as illustrated in the following diagram.
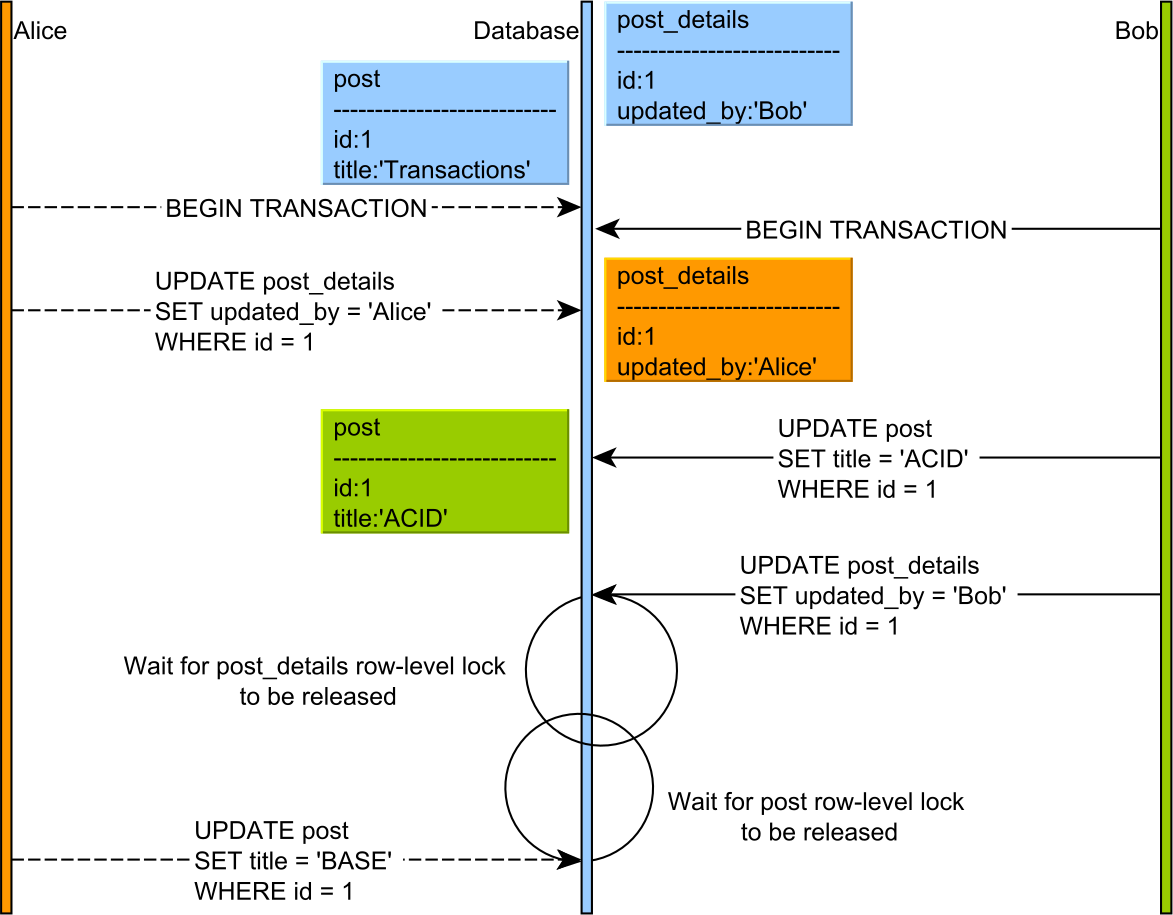
Because both transactions are in the lock acquisition phase, neither one releases a lock prior to acquiring the next one.
Recovering from a deadlock situation
If you’re using a Concurrency Control algorithm that relies on locks, then there is always the risk of running in a deadlock situation. Deadlocks can occur in any concurrency environment, not just in a database system.
For instance, a multithreading program can deadlock if two or more threads are waiting on locks that were previously acquired so that no thread can make any progress. If this happens in a Java application, the JVM cannot just force a Thread to stop its execution and release its locks.
Even if the Thread class exposes a stop method, that method has been deprecated since Java 1.1 because it can cause objects to be left in an inconsistent state after a thread is stopped. Instead, Java defines an interrupt method, which acts as a hint as a thread that gets interrupted can simply ignore the interruption and continue its execution.
For this reason, a Java application cannot recover from a deadlock situation, and it is the responsibility of the application developer to order the lock acquisition requests in such a way that deadlocks can never occur.
However, a database system cannot enforce a given lock acquisition order since it’s impossible to foresee what other locks a certain transaction will want to acquire further. Preserving the lock order becomes the responsibility of the data access layer, and the database can only assist in recovering from a deadlock situation.
The database engine runs a separate process that scans the current conflict graph for lock-wait cycles (which are caused by deadlocks).
When a cycle is detected, the database engine picks one transaction and aborts it, causing its locks to be released, so that the other transaction can make progress.
Unlike the JVM, a database transaction is designed as an atomic unit of work. Hence, a rollback leaves the database in a consistent state.
Deadlock priority
While the database chooses to roll back one of the two transactions being stuck, it’s not always possible to predict which one will be rolled back. As a rule of thumb, the database might choose to roll back the transaction with a lower rollback cost.
Oracle
According to the Oracle documentation, the transaction that detected the deadlock is the one whose statement will be rolled back.
SQL Server
SQL Server allows you to control which transaction is more likely to be rolled back during a deadlock situation via the DEADLOCK_PRIORITY session variable.
The DEADLOCK_PRIORITY session can accept any integer between -10 and 10, or pre-defined values such as LOW (-5), NORMAL (0) or HIGH (5).
In case of a deadlock, the transaction will roll back, unless the other transaction has a lower deadlock priority value. If both transactions have the same priority value, then SQL Server rolls back the transaction with the least rollback cost.
PostgreSQL
As explained in the documentation, PostgreSQL does not guarantee which transaction is to be rolled back.
MySQL
MySQL tries to roll back the transaction that modified the least number of records, as releasing fewer locks is less costly.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Understanding how deadlocks can occur when using a database system is very important since it allows you to handle unexpected transaction rollbacks properly.
Preventing rollbacks is not always possible, and, if a deadlock occurred, the client is supposed to retry the operations that were previously executed by the aborted transaction.
Database systems using the 2PL (Two-Phase Locking) concurrency control mechanism (e.g., SQL Server, MySQL under the Serializable isolation level) are more prone to deadlocks, compared to database systems that rely on MVCC (Multi-Version Concurrency Control), such as Oracle, PostgreSQL, or MySQL under any isolation level below Serializable.








