A beginner’s guide to database locking and the lost update phenomena
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
A database is highly concurrent system. There’s always a chance of update conflicts, like when two concurring transactions try to update the same record. If there would be only one database transaction at any time then all operations would be executed sequentially. The challenge comes when multiple transactions try to update the same database rows as we still have to ensure consistent data state transitions.
The SQL standard defines three consistency anomalies (phenomena):
- Dirty reads, prevented by Read Committed, Repeatable Read and Serializable isolation levels
- Non-repeatable read, prevented by Repeatable Read and Serializable isolation levels
- Phantom reads, prevented by the Serializable isolation level
A lesser-known phenomenon is the lost updates anomaly and that’s what we are going to discuss in this current article.
Isolation levels
Most database systems use Read Committed as the default isolation level (MySQL using Repeatable Read instead). Choosing the isolation level is about finding the right balance of consistency and scalability for our current application requirements.
All the following examples are going to be run on PostgreSQL. Other database systems may behave differently according to their specific ACID implementation.
PostgreSQL uses both locks and MVCC (Multiversion Concurrency Control). In MVCC read and write locks are not conflicting, so readers don’t block writers and writers don’t block readers.
Because most applications use the default isolation level, it’s very important to understand the Read Committed characteristics:
- Queries only see data committed before the query began and also the current transaction uncommitted changes
- Concurrent changes committed during a query execution won’t be visible to the current query
- UPDATE/DELETE statements use locks to prevent concurrent modifications
If two transactions try to update the same row, the second transaction must wait for the first one to either commit or rollback and if the first transaction has been committed, then the second transaction DML WHERE clause must be reevaluated to see if the match is still relevant.

In this example, Bob’s UPDATE must wait for Alice’s transaction to end (commit/rollback) in order to proceed further.
Read Committed accommodates more concurrent transactions than other stricter isolation levels, but less locking leads to better chances of losing updates.
Lost updates
If two transactions are updating different columns of the same row, then there is no conflict. The second update blocks until the first transaction is committed and the final result reflects both update changes.
If the two transactions want to change the same columns, the second transaction will overwrite the first one, therefore losing the first transaction update.
So an update is lost when a user overrides the current database state without realizing that someone else changed it between the moment of data loading and the moment the update occurs.
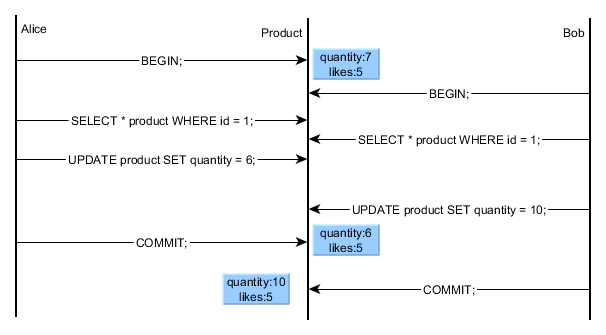
In this example Bob is not aware that Alice has just changed the quantity from 7 to 6, so her UPDATE is overwritten by Bob’s change.
The typical find-modify-flush ORM strategy
Hibernate (like any other ORM tool) automatically translates entity state transitions to SQL queries. You first load an entity, change it and let the Hibernate flush mechanism synchronize all changes with the database.
public Product incrementLikes(Long id) {
Product product = entityManager.find(Product.class, id);
product.incrementLikes();
return product;
}
public Product setProductQuantity(Long id, Long quantity) {
Product product = entityManager.find(Product.class, id);
product.setQuantity(quantity);
return product;
}
As I’ve already pointed out, all UPDATE statements acquire write locks, even in Read Committed isolation. The persistence context write-behind policy aims to reduce the lock holding interval but the longer the period between the read and the write operations the more chances of getting into a lost update situation.
Hibernate includes all row columns in an UPDATE statement. This strategy can be changed to include only the dirty properties (through the @DynamicUpdate annotation) but the reference documentation warns us about its effectiveness:
Although these settings can increase performance in some cases, they can actually decrease performance in others.
So let’s see how Alice and Bob concurrently update the same Product using an ORM framework:
| Alice | Bob |
|---|---|
|
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 7) WHERE ID = 1; | |
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (5, 10) WHERE ID = 1; | |
|
store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
|
|
store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
|
|
store=# SELECT * FROM PRODUCT WHERE ID = 1;
ID | LIKES | QUANTITY |
Again Alice’s update is lost without Bob ever knowing he overwrote her changes. We should always prevent data integrity anomalies, so let’s see how we can overcome this phenomenon.
Repeatable Read
As I explained in this article, unless you are using MySQL, Repeatable Read can prevent lost updates across concurrent database transactions. On MySQL and all the other databases, Serializable, which offers an even stricter isolation level, should prevent the Lost Update anomaly.
On PostgreSQL, when using Repeatable Read, the Lost Update anomaly is prevented like this:
| Alice | Bob |
|---|---|
|
store=# BEGIN; store=# SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
store=# BEGIN; store=# SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 7) WHERE ID = 1; | |
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (5, 10) WHERE ID = 1; | |
|
store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
|
|
ERROR: could not serialize access due to concurrent update store=# SELECT * FROM PRODUCT WHERE ID = 1; ERROR: current transaction is aborted, commands ignored until end of transaction block (1 ROW) |
This time, Bob couldn’t overwrite Alice’s changes and his transaction was aborted. In PostgreSQL, a Repeatable Read query will see the data snapshot as of the start of the current transaction. Changes committed by other concurrent transactions are not visible to the current transaction.
If two transactions attempt to modify the same record, the second transaction will wait for the first one to either commit or rollback. If the first transaction commits, then the second one must be aborted to prevent lost updates.
SELECT FOR UPDATE
Another solution would be to use the FOR UPDATE with the default Read Committed isolation level. This locking clause acquires the same write locks as with UPDATE and DELETE statements.
| Alice | Bob |
|---|---|
|
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1 FOR UPDATE; ID | LIKES | QUANTITY |
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1 FOR UPDATE; |
|
store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 7) WHERE ID = 1; store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; ID | LIKES | QUANTITY |
|
|
id | likes | quantity —-+——-+———- 1 | 6 | 7 (1 row) store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 10) WHERE ID = 1; |
Bob couldn’t proceed with the SELECT statement because Alice has already acquired the write locks on the same row. Bob will have to wait for Alice to end her transaction and when Bob’s SELECT is unblocked he will automatically see her changes, therefore Alice’s UPDATE won’t be lost.
Both transactions should use the FOR UPDATE locking. If the first transaction doesn’t acquire the write locks, the lost update can still happen.
| Alice | Bob |
|---|---|
|
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity |
|
|
store=# BEGIN; store=# SELECT * FROM PRODUCT WHERE ID = 1 FOR UPDATE id | likes | quantity |
|
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 7) WHERE ID = 1; | |
|
store=# UPDATE PRODUCT SET (LIKES, QUANTITY) = (6, 10) WHERE ID = 1; store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity |
|
|
store=# SELECT * FROM PRODUCT WHERE ID = 1;
id | likes | quantity store=# COMMIT; |
|
|
store=# SELECT * FROM PRODUCT WHERE ID = 1;
id | likes | quantity |
Alice’s UPDATE is blocked until Bob releases the write locks at the end of his current transaction. But Alice’s persistence context is using a stale entity snapshot, so she overwrites Bob changes, leading to another lost update situation.
Optimistic Locking
My favorite approach is to replace pessimistic locking with an optimistic locking mechanism. Like MVCC, optimistic locking defines a versioning concurrency control model that works without acquiring additional database write locks.
The product table will also include a version column that prevents old data snapshots to overwrite the latest data.
| Alice | Bob |
|---|---|
|
store=# BEGIN; BEGIN store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity | version |
store=# BEGIN; BEGIN store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity | version |
|
store=# UPDATE PRODUCT SET (LIKES, QUANTITY, VERSION) = (6, 7, 3) WHERE (ID, VERSION) = (1, 2); UPDATE 1 |
|
| store=# UPDATE PRODUCT SET (LIKES, QUANTITY, VERSION) = (5, 10, 3) WHERE (ID, VERSION) = (1, 2); | |
|
store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity | version |
|
|
UPDATE 0 store=# COMMIT; store=# SELECT * FROM PRODUCT WHERE ID = 1; id | likes | quantity | version |
Every UPDATE takes the load-time version into the WHERE clause, assuming no one has changed this row since it was retrieved from the database. If some other transaction manages to commit a newer entity version, the UPDATE WHERE clause will no longer match any row and so the lost update is prevented.
Hibernate uses the PreparedStatement#executeUpdate result to check the number of updated rows. If no row was matched, it then throws a StaleObjectStateException (when using Hibernate API) or an OptimisticLockException (when using JPA).
Like with Repeatable Read, the current transaction and the persistence context are aborted, with respect to atomicity guarantees.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Lost updates can happen unless you plan on preventing such situations. Other than optimistic locking, all pessimistic locking approaches are effective only in the scope of the same database transaction when both the SELECT and the UPDATE statements are executed in the same physical transaction.










Muchas gracias por compartir este grandioso material, me a ayudado mucho