9 High-Performance Tips when using Oracle with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to show you 9 tips that will help you speed up your Oracle database application when using JPA and Hibernate.
To get the most out of the relational database in use, you need to make sure the data access layer resonates with the underlying database system, so, in this article, I’m going to present you several tips that can boost up the performance of your Oracle, JPA and Hibernate applications.
1. Configure the Buffer Pool and OS cache
Like any relational database system, Oracle is designed to minimize disk access as much as possible.

When a page is needed, Oracle checks the Buffer Pool to see if the page can be resolved from the cache. That’s a logical read. If there’s no page cached, Oracle loads it from the disk and stores it in the Buffer Pool. That’s a physical read. This way, the next time you request the same page, it will be loaded from the cache and not from the database.
Traditionally, database systems use two logs to mark transaction modifications:
- the undo log is used to restore uncommitted changes in case of a rollback. In Oracle, the undo log stores the diff between the latest uncommitted tuple and the previous state.
- the redo_log ensures transaction durability and stores every transaction modification since the Buffer Pool is not flushed to disk after every transaction execution. So, for this reason, the Buffer Pool is flushed periodically during checkpoints.
Since Unix-based operation systems have their own page cache, it’s important to mount the data and index partitions using Direct I/O (e.g., O_DIRECT) to avoid storing the same page in both the OS cache and the Buffer Pool.
2. Learn all supported SQL features
Oracle supports many of the SQL:2016 standard features, such as Window Functions, CTE, Recursive CTE, PIVOT, MERGE, and even the MATCH_RECOGNIZE clause that only Oracle added support for.
Besides those SQL standard features, Oracle has been provided DB-specific features as well, such as the MODEL clause.
Oracle also provides DB-specific features, such as the MODEL clause or Flashback queries.
So, if you restrict your data access queries to the SQL:92 feature list that you learned in college or on W3 Schools, you are going to miss a lot of features that can help you address very complex data access requirements.
It’s very important to read the Oracle documentation and get familiar with all the features that it offers.
And, just because you are using JPA and Hibernate, it doesn’t mean that you should only write JPQL and Criteria API queries. There’s a very good reason why the JPA EntityManager allows you to run native SQL queries because any non-trivial database application will need to execute native SQL.
3. Optimize for the execution plan cache
Unlike PostgreSQL and MySQL, Oracle provides an Execution Plan Cache that allows you to speed up the SQL query execution.
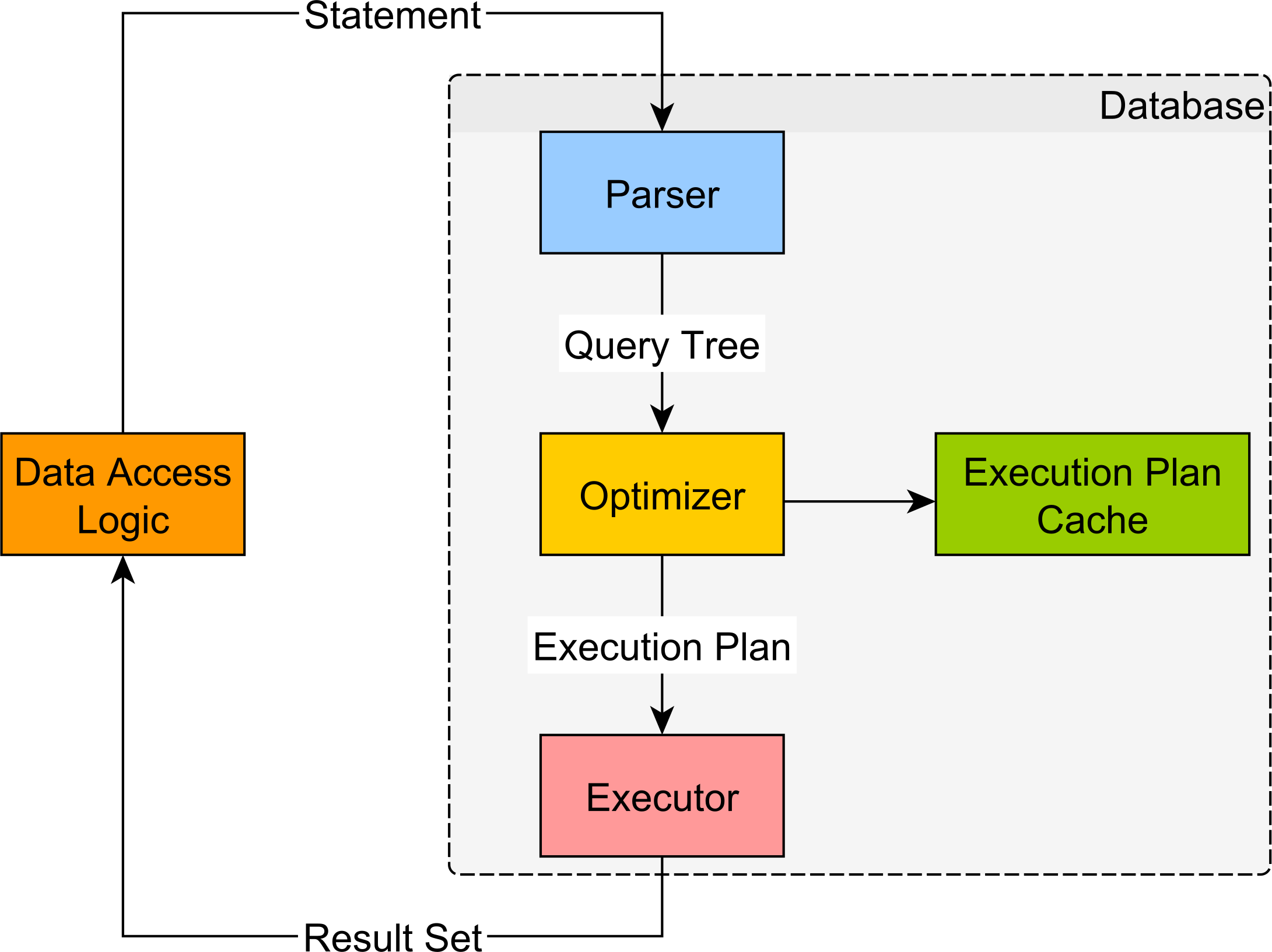
The Execution Plan Cache can even store multiple plans for a given query to match various bind parameter values that have a very skewed data distribution.
Knowing how the execution plan cache works, you should then configure your data access layer to take advantage of this very useful feature. Therefore, you should:
- Enable the
hibernate.query.in_clause_parameter_paddingHibernate feature so that IN clause queries can reuse the same plans. - Set the
hibernate.criteria.literal_handling_modeHibernate configuration property to the value ofbind.
4. Enable the JDBC statement cache mechanism
The Oracle JDBC Driver provides a statement caching mechanism that is disabled by default. So, to speed up your SQL queries, you should enable it by setting the oracle.jdbc.implicitStatementCacheSize property to a positive integer value.
You can do this declaratively via the JDBC URL connection string:
jdbc:oracle:thin:@tcp://hpjp:1521/training? oracle.jdbc.implicitStatementCacheSize=100
Or, programmatically, via the JDBC DataSource properties:
OracleDataSource dataSource = new OracleDataSource();
dataSource.setDatabaseName("high_performance_java_persistence");
dataSource.setURL(url());
dataSource.setUser(username());
dataSource.setPassword(password());
Properties properties = new Properties();
properties.put(
"oracle.jdbc.implicitStatementCacheSize",
Integer.toString(cacheSize)
);
dataSource.setConnectionProperties(properties);
5. Increase the default JDBC statement fetch size
Unlike PostgreSQL and MySQL, which prefetch the entire JDBC ResultSet, Oracle uses a fetch size of just 10. So, a query that returns 50 records requires 5 database roundtrips to fetch all the data from the database Executor.
For this reason, you should always increase the default fetch size when using Oracle. If you’re using Hibernate, you can apply this change globally to all the SQL statements via the hibernate.jdbc.fetch_size configuration property.
For instance, if you;re using Spring Boot, you can set this property in the application.properties configuration file, like this:
spring.jpa.properties.hibernate.jdbc.fetch_size=100
And, if you’re using database cursors to get a Java 8 Stream, then you can always set the fetch size to a lower value using the org.hibernate.fetchSize JPA query hint:
Stream<Post> postStream = entityManager.createQuery("""
select p
from Post p
order by p.createdOn desc
""", Post.class)
.setHint(QueryHints.HINT_FETCH_SIZE, 10)
.getResultStream();
6. Enable automatic JDBC batching
For writing data, JDBC statement batching can help you reduce the transaction response time. When using Hibernate, enabling batching is just a matter of setting some configuration properties
So, you should always set the following Hibernate settings set in your Spring Boot application.properties configuration file:
spring.jpa.properties.hibernate.jdbc.batch_size=10 spring.jpa.properties.hibernate.order_inserts=true spring.jpa.properties.hibernate.order_updates=true
7. Prefer SEQUENCE over IDENTITY
Oracle 12c added support for IDENTITY columns. However, you should use the SEQUENCE identifier generator to auto-increment Primary Keys because this will allow Hibernate to use automatic batching for the INSERT statements.
For more details, check out this article.
8. Use the Hibernate @RowId when mapping JPA entities
When using Oracle, you can annotate the JPA entities with the @RowId Hibernate annotation so that the UPDATE statement can locate the record by its ROWID instead of the Primary Key value.
For more details about this topic, check out this article.
9. Store non-structured data in JSON column types
In a relational database, it’s best to store data according to the principles of the relational model.
However, it might be that you also need to store non-structured data, in which case, a JSON column can help you deal with such a requirement.
While Oracle 21c will add a JSON column type:
CREATE TABLE book ( id NUMBER(19, 0) NOT NULL PRIMARY KEY, isbn VARCHAR2(15 CHAR), properties JSON )
If you’re using Oracle 19c, 18c, or 12c, you can store JSON objects in VARCHAR2, BLOB, or CLOB column types. It’s recommended to store small JSON objects so they can fit in a VARCHAR2(4000) column and, therefore, fit into the Buffer Pool page.
When you create the table, you can validate the stored JSON objects using a CHECK constraint:
CREATE TABLE book ( id NUMBER(19, 0) NOT NULL PRIMARY KEY, isbn VARCHAR2(15 CHAR), properties VARCHAR2(4000) CONSTRAINT ENSURE_JSON CHECK (properties IS JSON) )
To index JSON attributes that have high selectivity, you can use a B+Tree index:
CREATE INDEX book_properties_title_idx ON book b (b.properties.title)
To index JSON attributes that have low selectivity, such as boolean or Enum values, you can use a BITMAP index:
CREATE BITMAP INDEX book_properties_reviews_idx ON book (JSON_EXISTS(properties,'$.reviews'))
Because a bitmap index record references many rows of the associated indexed table, concurrent
UPDATEorDELETEstatements can lead to concurrency issues (e.g., deadlocks, lock timeouts, high response times).For this reason, they are useful for read-only columns or if the column values change very infrequently.
You can also use a generic SEARCH index for the JSON column, which will allow you to match key/value JSON attribute data:
CREATE SEARCH INDEX book_search_properties_idx ON book (properties) FOR JSON
For JPA and Hibernate, you can use the JsonType from the Hypersistence Utils project to map JSON columns, and this mapping will work with Oracle, PostgreSQL, MySQL, SQL Server, and H2.
For more details about how you can use the JsonType to map JSON columns, check out this article.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Apply all these Tips when using Oracle with JPA and Hibernate
As you can see, there are many tips you can apply when using Oracle with JPA and Hibernate.
Since Oracle is the most advanced RDBMS, it’s very useful to know how it works in order to get the most out of it.








