The best way to do the Spring 6 migration
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see how you can get the most out of the Spring 6 and Hibernate 6 migration.
The tips in this article are based on the work I’ve done to add support for Spring 6 in Hypersistence Optimizer and the High-Performance Java Persistence project.
Java 17
First of all, Spring 6 has bumped up the minimum Java version to 17, and that’s awesome because you can now use Text Blocks and Records.
Text Blocks
Thanks to Text Blocks, your @Query annotations are going to be much more readable:
@Query("""
select p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId
""")
List<Post> findAllWithComments(
@Param("minId") long minId,
@Param("maxId") long maxId
);
For more details about Java Text Blocks, check out this article as well.
Records
Java Records are great for DTO projections. For instance, you can define a PostRecord class like this:
public record PostCommentRecord(
Long id,
String title,
String review
) {}
And, then you can fetch the PostCommentRecord objects with the Spring Data JPA query method:
@Query("""
select new PostCommentRecord(
p.id as id,
p.title as title,
c.review as review
)
from PostComment c
join c.post p
where p.title like :postTitle
order by c.id
""")
List<PostCommentRecord> findCommentRecordByTitle(
@Param("postTitle") String postTitle
);
The reason why we could use the simple name of the PostCommentRecord Java Class in the JPQL constructor expression is that I registered the following ClassImportIntegrator from the Hypersistence Utils project:
properties.put(
"hibernate.integrator_provider",
(IntegratorProvider) () -> Collections.singletonList(
new ClassImportIntegrator(
List.of(
PostCommentRecord.class
)
)
)
);
For more details about Java Records, check out this article as well.
And that’s not all! Java 17 improves the error message for NullPointerException and adds pattern matching for switch and instanceOf.
JPA 3.1
By default, Spring 6 uses Hibernate 6.1, which in turn uses Jakarta Persistence 3.1.
Now, the 3.0 version marks the migration from Java Persistence to Jakarta Persistence, so, for this reason, you will have to replace the javax.persistence package imports with the jakarta.persistence namespace.
That is the most significant change that you will have to make in order to migrate to JPA 3. In the meantime, the 3.1 version was released, but this one includes just some minor improvements that were already supported by Hibernate.
UUID entity attributes
For instance, JPA 3 now supports UUID basic types:
@Column(
name = "external_id",
columnDefinition = "UUID NOT NULL"
)
private UUID externalId;
And you can even use them as entity identifiers:
@Id @GeneratedValue(strategy = GenerationType.UUID) private UUID id;
But that’s just a terrible idea because using an UUID for the Primary Key is going to cause a lot of issues:
- the index pages will be sparsely populated because each new UUID will be added randomly across the B+Tree clustered index.
- there are going to be more page splits because of the randomness of the Primary Key values
- the UUID is huge, needing twice as many bytes as a
bigintcolumn. Not only it affects the Primary Key but all the associated Foreign Keys as well.
More, if you’re using SQL Server, MySQL, or MariaDB, the default table is going to be organized as a Clustered Index, making all these problems even worse.
So, you are better off avoiding using the UUID for entity identifiers. If you really need to generate unique identifiers from the application, then you are better off using a 64-bit time-sorted random TSID instead.
For more details about why the standard UUIDs are not a good fit for Primary Keys and why you should use a time-sorted TSID instead, check out this article.
New JPQL functions
JPQL was enhanced with many new functions, like the CEILING, FLOOR, EXP, LN, POWER, ROUND, SIGN numeric functions.
However, the most useful one I’ve found is the EXTRACT Date/Time function:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
where EXTRACT(YEAR FROM createdOn) = :year
""", Post.class)
.setParameter("year", Year.now().getValue())
.getResultList();
This is useful because Date/Time processing usually requires database-specific functions, and having a generic function that can render the proper database-specific function is surely handy.
Auto-closable EntityManager and EntityManagerFactory
While the Hibernate Session and SessionFactory were already extending the AutoClosable interface, now the JPA EntityManager and EntityManagerFactory have followed this practice as well:

Although you might rarely need to rely on that because Spring takes care of the EntityManager on your behalf, it’s very handy when you have to process the EntityManager programmatically.
Hibernate 6
While Java 17 and JPA 3.1 bring you a few features, Hibernate 6 provides a ton of enhancements.
JDBC optimizations
Previously, Hibernate was reading the JDBC ResultSet column values using the associated column alias, and that was proven to be slow. For this reason, Hibernate 6 has switched to reading the underlying column values by their position in the underlying SQL projection.
Apart from being faster, there’s a very nice side-effect of making this change. The underlying SQL queries are now more readable.
For instance, if you run this JPQL query on Hibernate 5:
Post post = entityManager.createQuery("""
select p
from Post p
join fetch p.comments
where p.id = :id
""", Post.class)
.setParameter("id", 1L)
.getSingleResult();
The following SQL query will be executed:
SELECT
bidirectio0_.id AS id1_0_0_,
comments1_.id AS id1_1_1_,
bidirectio0_.title AS title2_0_0_,
comments1_.post_id AS post_id3_1_1_,
comments1_.review AS review2_1_1_,
comments1_.post_id AS post_id3_1_0__,
comments1_.id AS id1_1_0__
FROM post
bidirectio0_
INNER JOIN
post_comment comments1_ ON bidirectio0_.id=comments1_.post_id
WHERE
bidirectio0_.id=1
Ugly!
How, if you run the same JPQL on Hibernate 6, the following SQL query will be run instead:
SELECT
p1_0.id,
c1_0.post_id,
c1_0.id,
c1_0.review,
p1_0.title
FROM
post p1_0
JOIN
post_comment c1_0 ON p1_0.id=c1_0.post_id
WHERE
p1_0.id = 1
Much better, right?
Semantic Query Model and Criteria queries
Hibernate 6 provides a brand-new entity query parser that is able to produce a canonical model, the Semantic Query Model, from both JPQL and Criteria API.
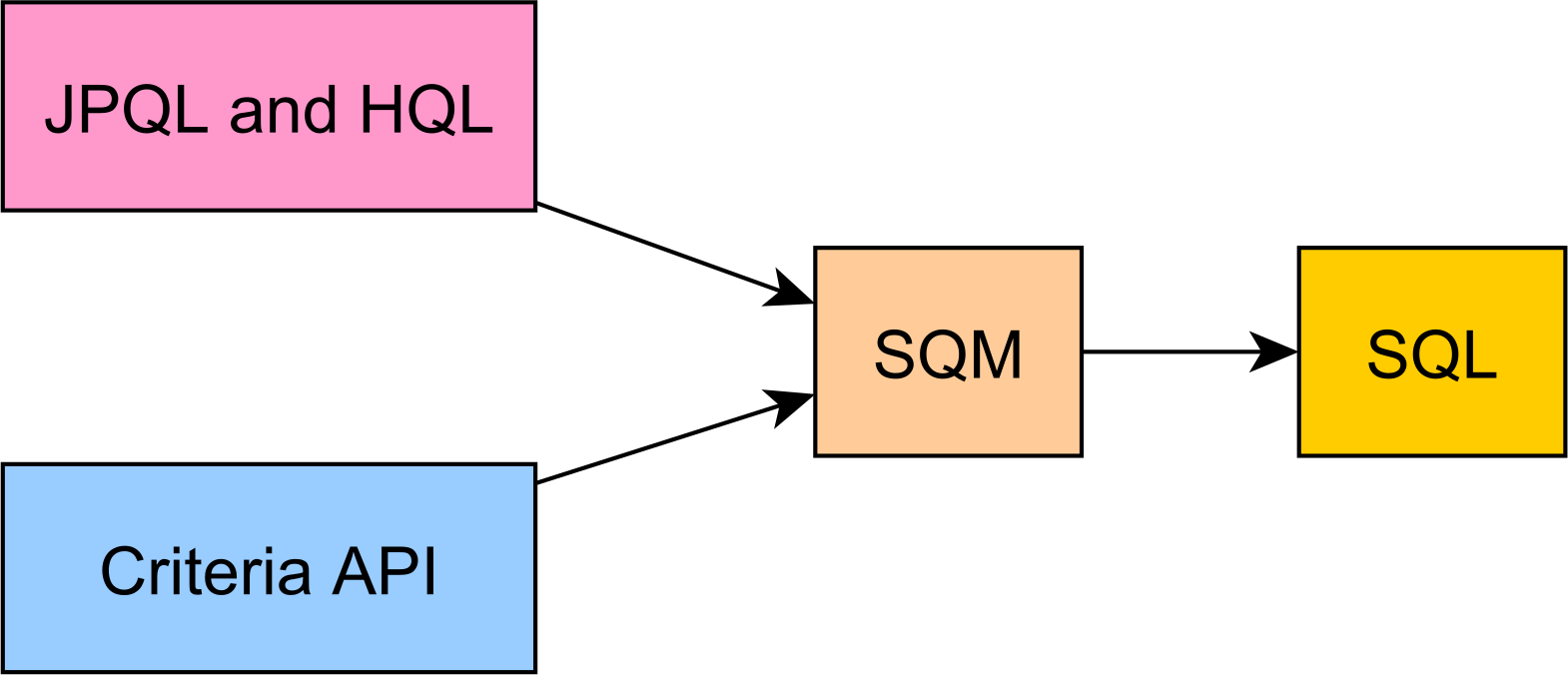
By unifying the entity query model, Criteria queries are now able to be enhanced with features that are not supported by a Jakarta Persistence, like Derived Tables or Common Table Expressions.
For more details about the Hibernate Semantic Query Model, check out this article.
The legacy Hibernate Criteria has been removed, but the Criteria API was enhanced with many new features that are available via the HibernateCriteriaBuilder.
For instance, you can use the ilike function for case-insensitive LIKE matching:
HibernateCriteriaBuilder builder = entityManager
.unwrap(Session.class)
.getCriteriaBuilder();
CriteriaQuery<Post> criteria = builder.createQuery(Post.class);
Root<Post> post = criteria.from(Post.class);
ParameterExpression<String> parameterExpression = builder
.parameter(String.class);
List<Post> posts = entityManager.createQuery(
criteria
.where(
builder.ilike(
post.get(Post_.TITLE),
parameterExpression)
)
.orderBy(
builder.asc(
post.get(Post_.ID)
)
)
)
.setParameter(parameterExpression, titlePattern)
.setMaxResults(maxCount)
.getResultList();
However, this is just a basic example. With the new HibernateCriteriaBuilder, you can now render:
- UNION ALL
- Window Functions
- Derived Tables
- CTE and Recursive CTE
Dialect enhancements
While in Hibernate 5, there were a ton of Dialect versions you had to choose from based on the underlying database version, this was greatly simplified in Hibernate 6:
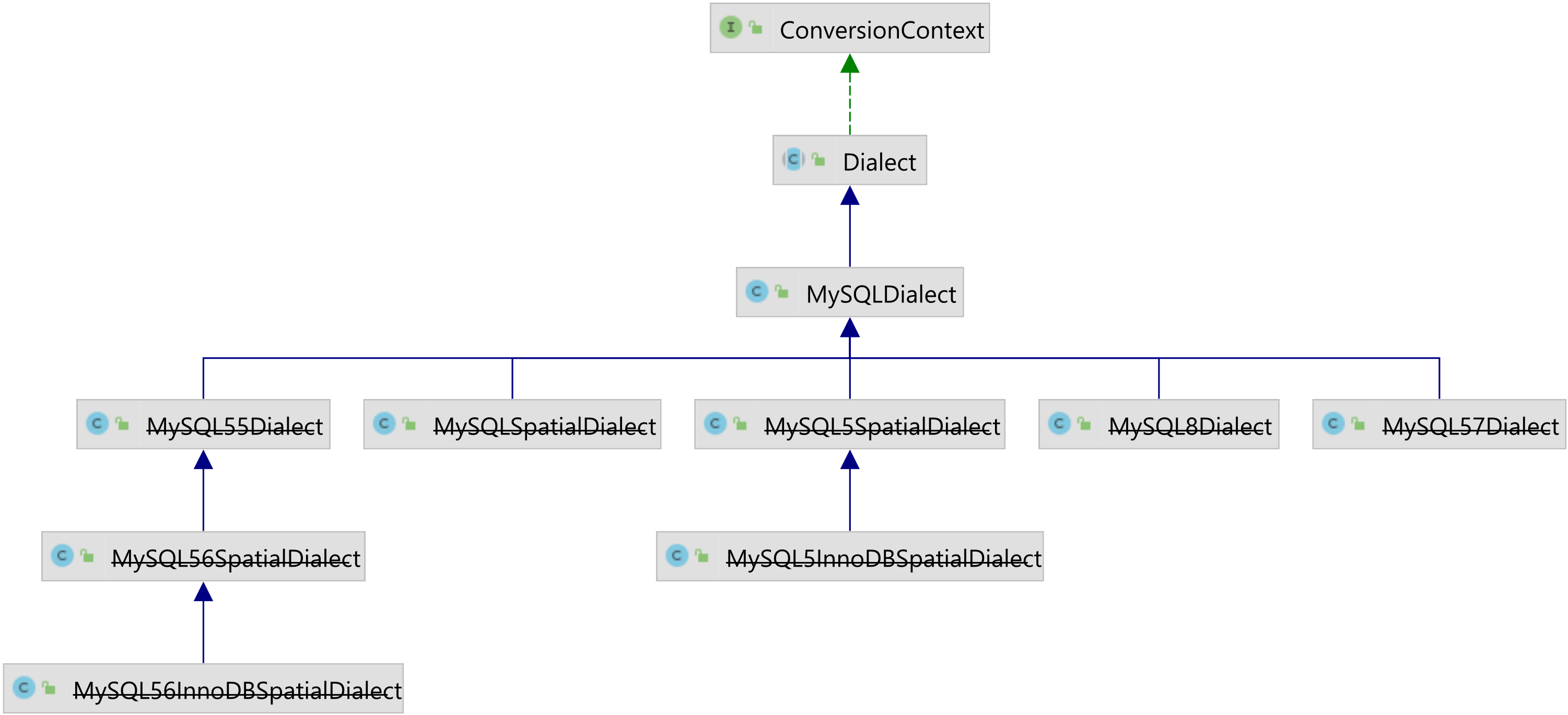
More, you don’t even need to provide the Dialect in the Spring configuration, as it can be resolved from the JDBC DatabaseMetaData.
For more details about this topic, check out this article.
Auto-deduplication
Do you remember how annoying it was to provide the DISTINCT keyword for entity deduplication whenever you were using JOIN FETCH?
List<Post> posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.comments
where p.title = :title
""", Post.class)
.setParameter("title", "High-Performance Java Persistence")
.setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false)
.getResultList();
If you forgot to send the PASS_DISTINCT_THROUGH hint, then Hibernate 5 would pass the DISTINCT keyword to the SQL query and cause the execution plan to run some extra steps that only made your query slower:
Unique
(cost=23.71..23.72 rows=1 width=1068)
(actual time=0.131..0.132 rows=2 loops=1)
-> Sort
(cost=23.71..23.71 rows=1 width=1068)
(actual time=0.131..0.131 rows=2 loops=1)
Sort Key: p.id, pc.id, p.created_on, pc.post_id, pc.review
Sort Method: quicksort Memory: 25kB
-> Hash Right Join
(cost=11.76..23.70 rows=1 width=1068)
(actual time=0.054..0.058 rows=2 loops=1)
Hash Cond: (pc.post_id = p.id)
-> Seq Scan on post_comment pc
(cost=0.00..11.40 rows=140 width=532)
(actual time=0.010..0.010 rows=2 loops=1)
-> Hash
(cost=11.75..11.75 rows=1 width=528)
(actual time=0.027..0.027 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on post p
(cost=0.00..11.75 rows=1 width=528)
(actual time=0.017..0.018 rows=1 loops=1)
Filter: (
(title)::text =
'High-Performance Java Persistence eBook has been released!'::text
)
Rows Removed by Filter: 3
For more details about how
DISTINCTworks in JPA, heck out this article as well.
That’s no longer the case, as now the entity Object reference deduplication is done automatically, so your JOIN FETCH queries no longer need the DISTINCT keyword:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
where p.title = :title
""", Post.class)
.setParameter("title", "High-Performance Java Persistence")
.getResultList();
Awesome, right?
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Spring 6 is really worth upgrading to. Besides benefiting from all the language optimizations provided by Java 17, there are tons of new features provided by all the other framework dependencies that have been integrated into Spring 6.
For instance, Hibernate 6 provides a lot of optimizations and new features that are going to address many of your daily data access requirements.
And that is also why I have launched the Spring and Hibernate 6 Migration training. So, if you like my articles, you are going to love running this training with me.








