Seize the deal!
07
Days
:
01
Hours
:
38
Minutes
:
54
Seconds
You missed out!

High-Performance
Video Course Bundle
Save $199.6

High-Performance Spring Persistence
Video Course
Save $79.6
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
In this article, we are going to see why there is no benefit in using the Set collection type when mapping a bidirectional JPA OneToMany association.
While the @OneToMany annotation can be used to map both unidirectional and bidirectional associations, as I explained this article, you should avoid the unidirectional mapping since it can lead to very inefficient SQL statements.
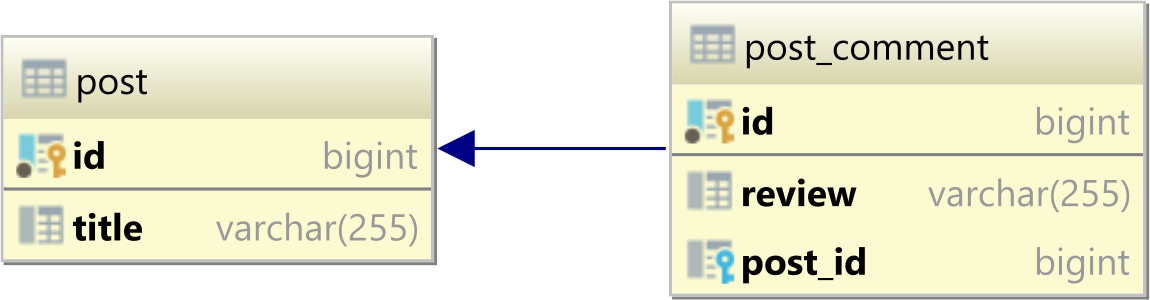
The goal of the bidirectional JPA OneToMany association is to map the one-to-many table relationship, which consists of two tables that form a parent-child relationship via a Foreign Key column in the child table.
If we have a parent post table and a post_comment child table, the one-to-many table relationship is given by the post_id column in the child table that has a Foreign Key constraint that associates it with the id column of the post table, as illustrated by the following diagram:
With JPA, we can map this table relationship to the following bidirectional OneToMany association:

The PostComment entity maps the post_id Foreign Key column using the JPA @ManyToOne annotation:
@ManyToOne(fetch = FetchType.LAZY) private Post post;
And on the Post entity, we usually map the other side of this bidirectional association as a List of child entities:
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL, orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
As I explained in this article, bidirectional JPA associations require the add/remove utility methods that allow us to synchronize both sides of this association whenever we want to add or remove a child entity:
public Post addComment(PostComment comment) {
comments.add(comment);
comment.setPost(this);
return this;
}
⠀
public Post removeComment(PostComment comment) {
comments.remove(comment);
comment.setPost(null);
return this;
}
In order for the remove method to work correctly, we need the child entity to implement the equals method according to the Java equality contract, which requires the equals method to be reflexive, symmetric, transitive, and consistent.
And if we are implementing a certain equals logic, we need to make sure that the hashCode is implemented accordingly as well so that two entity objects that are equal share the same hashCode value.
In the case of JPA entities, equality is given by the identity of the associated table record, not by the content of the entity, which is mutable.
As I explained in this article, if the associated table record has a non-null business key, we can safely use that for equals and hashCode.
Unfortunately, most of the time, we don’t have a business key in every database table that we are mapping as a JPA entity, so instead, we need to use the entity identifier. However, if the identifier is auto-generated, then we need to implement equals as explained in this article:
@Override
public boolean equals(Object o) {
if (this == o)
return true;
⠀
if (!(o instanceof PostComment))
return false;
⠀
return id != null &&
id.equals(((PostComment) o).getId());
}
@Override
public int hashCode() {
return getClass().hashCode();
}
For equals, we can only compare the id if it’s not null since a not null identifier is associated with an actual table record while a null identifier indicates that the entity represents a future record that doesn’t yet exist in the database.
The hashCode method uses the hashCode of the entity class to guarantee the consistency part of the Java equality contract and provide a constant hashCode value across all entity state transitions.
While the List collection type is the most obvious choice, it’s not uncommon to see examples where a Set is used instead, as in the following example:
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL, orphanRemoval = true
)
private Set<PostComment> comments = new HashSet<>();
But, what’s the point of that? A Set will never contain two entities objects that are equal. However, considering that for JPA entities, equality is based on the identity of the associated table record, every child entity stored in the Set will be distinct because it has a distinct Primary Key or business key.
It might be the case that a
Setcollection type is used to avoid theMultipleBagFetchExceptionwhen fetching multiple collections at once.However, this is not recommended since it will lead to Cartesian Product issues. For more details about this topic, check out this article.
If we are using the aforementioned equals and hashCode implementations that are based on auto-generated identifiers, then using the constant hashCode will slow down the Set significantly because we will end up with a single internal bucket in which the Set will search all elements to make sure that non of the existing ones is equal to the one we want to add.
To visualize this issue, let’s consider the following test case:
long createListStartNanos = System.nanoTime();
List<Post> postList = new ArrayList<>(collectionSize);
for (int i = 0; i < collectionSize; i++) {
Post post = new Post().setId((long) i);
postList.add(i, post);
}
LOGGER.info(
"Creating a List with [{}] elements took : [{}] μs",
collectionSize,
TimeUnit.NANOSECONDS.toMicros(
System.nanoTime() - createListStartNanos
)
);
long createSetStartNanos = System.nanoTime();
Set<Post> postSet = new HashSet<>();
for (int i = 0; i < collectionSize; i++) {
Post post = new Post().setId((long) i);
postSet.add(post);
}
LOGGER.info(
"Creating a Set with [{}] elements took : [{}] μs",
collectionSize,
TimeUnit.NANOSECONDS.toMicros(
System.nanoTime() - createSetStartNanos
)
);
When running this test case for various collection sizes, we get the following results:
| Collection size | List creation time | Set creation time | | --------------- | ------------------ | ------------------| | 50 | 30 μs | 819 μs | | 100 | 41 μs | 1824 μs | | 500 | 151 μs | 10351 μs | | 1000 | 429 μs | 19933 μs |
While creating the ArrayList is very fast, the HashSet could be orders of magnitude slower because of the constant hashCode value.
Therefore, since we don’t even have duplicate child entities when fetching data from the database, the List is a much better choice for a bidirectional JPA OneToMany collection.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



For bidirectional JPA OneToMany associations, the Set collection type is not a very good choice since the elements we fetch from the DB are already distinct from the table record identity perspective.
Using a List is a much better choice as the entities will be stored in the same order they were fetched from the database, and when adding a new element, the collection does not have the same overhead as the Set, especially when using the auto-generated identifier for equals and hashCode.







