How to synchronize bidirectional entity associations with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
While answering this StackOverflow question, I realized that it’s a good idea to summarize how various bidirectional associations should be synchronized when using JPA and Hibernate.
Therefore, in this article, you are going to learn how and also why you should always synchronize both sides of an entity relationship, no matter if it’s @OneToMany, @OneToOne or @ManyToMany.
One-To-Many
Let’s assume we have a parent Post entity which has a bidirectional association with the PostComment child entity:

The PostComment entity looks as follows:
@Entity(name = "PostComment")
@Table(name = "post_comment")
public class PostComment {
⠀
@Id
@GeneratedValue
private Long id;
⠀
private String review;
⠀
@ManyToOne(
fetch = FetchType.LAZY
)
@JoinColumn(name = "post_id")
private Post post;
⠀
//Getters and setters omitted for brevity
⠀
@Override
public boolean equals(Object o) {
if (this == o)
return true;
⠀
if (!(o instanceof PostComment))
return false;
⠀
return
id != null &&
id.equals(((PostComment) o).getId());
}
@Override
public int hashCode() {
return getClass().hashCode();
}
}
There are several things to notice in the PostComment entity mapping above.
First, the @ManyToOne association uses the FetchType.LAZY strategy because by default @ManyToOne and @OneToOne associations use the FetchType.EAGER strategy which is bad for performance.
Second, the equals and hashCode methods are implemented based on the entity identifier, as explained in this article. The reason we implemented these two methods is because Java collections may use them when calling contains, remove, or other collection-related methods.
The Post entity is mapped as follows:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
⠀
@Id
@GeneratedValue
private Long id;
⠀
private String title;
⠀
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
⠀
//Getters and setters omitted for brevity
⠀
public void addComment(PostComment comment) {
comments.add(comment);
comment.setPost(this);
}
⠀
public void removeComment(PostComment comment) {
comments.remove(comment);
comment.setPost(null);
}
}
The comments @OneToMany association is marked with the mappedBy attribute which indicates that the @ManyToOne side is responsible for handling this bidirectional association.
However, we still need to have both sides in sync as otherwise, we break the Domain Model relationship consistency, and the entity state transitions are not guaranteed to work unless both sides are properly synchronized.
If a bidirectional association is out of sync and only the child can reference a parent while the parent wouldn’t contain the child in its collection, then you risk exposing your model to tricky bugs where you make the wrong decision based on the presence or the absence of a child in the parent’s children collection.
And, in the context of Hibernate, only synchronized bidirectional associations are guaranteed to be persisted properly in the database. Even if you observe on a specific Hibernate version that it works even when the association is out of sync, it’s not guaranteed that it will work if you upgrade to a newer version of Hibernate.
For these reasons, the Post entity defines the addComment and removeComment entity state synchronization methods.
So, when you add a PostComment, you need to use the addComment method:
Post post = new Post();
post.setTitle("High-Performance Java Persistence");
PostComment comment = new PostComment();
comment.setReview("JPA and Hibernate");
post.addComment(comment);
entityManager.persist(post);
And, when you remove a PostComment, you should use the removeComent method as well:
Post post = entityManager.find(Post.class, 1L); PostComment comment = post.getComments().get(0); post.removeComment(comment);
For more details about the best way to map a
@OneToManyassociation, check out this article.
One-To-One
For the one-to-one association, let’s assume the parent Post entity has a PostDetails child entity as illustrated in the following diagram:
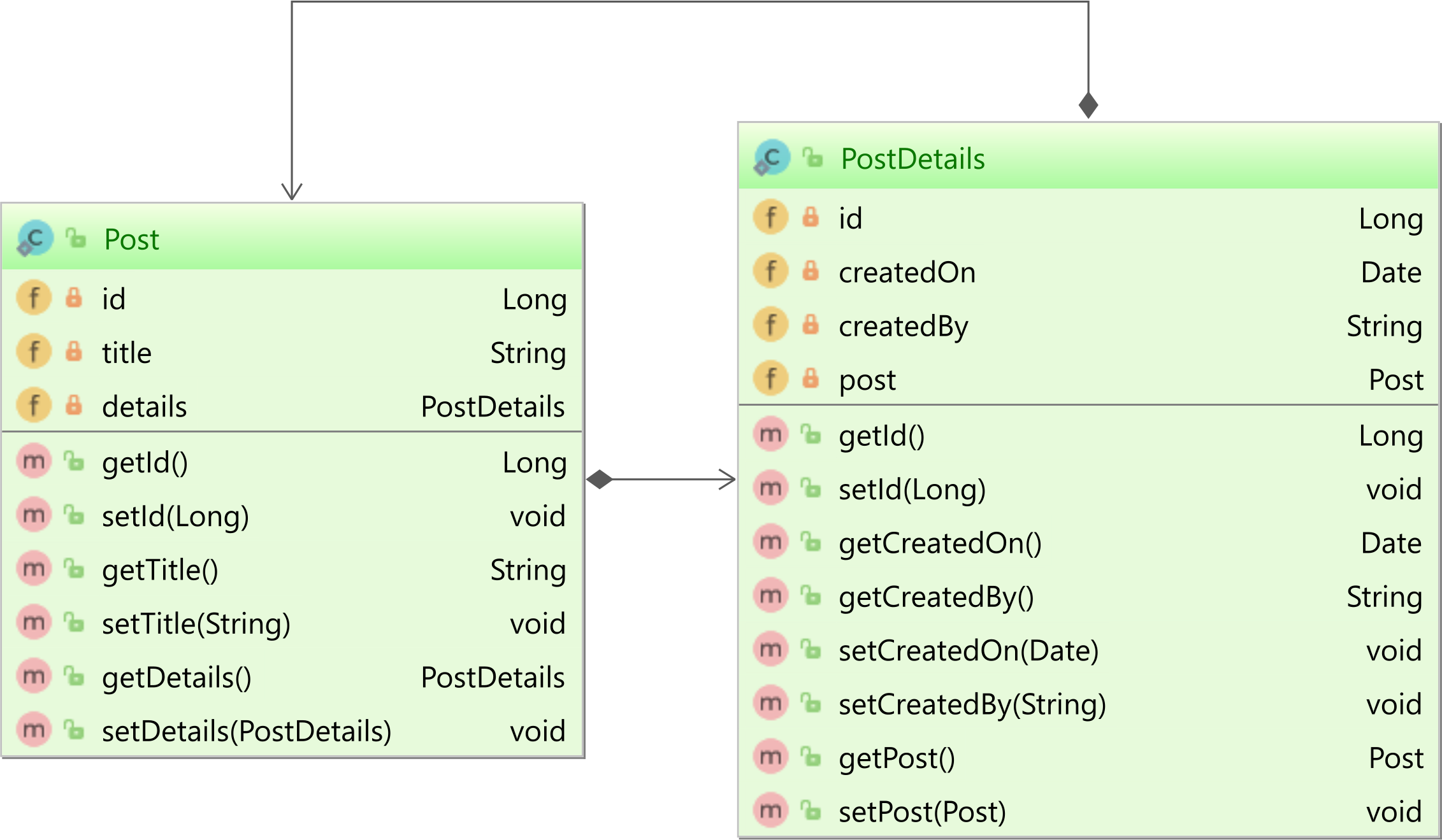
The child PostDetails entity looks like this:
@Entity(name = "PostDetails")
@Table(name = "post_details")
public class PostDetails {
⠀
@Id
private Long id;
⠀
@Column(name = "created_on")
private Date createdOn;
⠀
@Column(name = "created_by")
private String createdBy;
⠀
@OneToOne(fetch = FetchType.LAZY)
@MapsId
private Post post;
⠀
//Getters and setters omitted for brevity
}
Notice that we have set the @OneToOne fetch attribute to FetchType.LAZY, for the very same reason we explained before. We are also using @MapsId because we want the child table row to share the Primary Key with its parent table row meaning that the Primary Key is also a Foreign Key back to the parent table record.
The parent Post entity looks as follows:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
⠀
@Id
@GeneratedValue
private Long id;
⠀
private String title;
⠀
@OneToOne(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true,
fetch = FetchType.LAZY
)
private PostDetails details;
⠀
//Getters and setters omitted for brevity
⠀
public void setDetails(PostDetails details) {
if (details == null) {
if (this.details != null) {
this.details.setPost(null);
}
}
else {
details.setPost(this);
}
this.details = details;
}
}
The details @OneToOne association is marked with the mappedBy attribute which indicates that the PostDetails side is responsible for handling this bidirectional association.
The setDetails method is used for synchronizing both sides of this bidirectional association and is used both for adding and removing the associated child entity.
So, when we want to associate a Post parent entity with a PostDetails, we use the setDetails method:
Post post = new Post();
post.setTitle("High-Performance Java Persistence");
PostDetails details = new PostDetails();
details.setCreatedBy("Vlad Mihalcea");
post.setDetails(details);
entityManager.persist(post);
The same is true when we want to dissociate the Post and the PostDetails entity:
Post post = entityManager.find(Post.class, 1L); post.setDetails(null);
For more details about the best way to map a
@OneToOneassociation, check out this article.
Many-To-Many
Let’s assume the Post entity forms a many-to-many association with Tag as illustrated in the following diagram:

The Tag is mapped as follows:
@Entity(name = "Tag")
@Table(name = "tag")
public class Tag {
⠀
@Id
@GeneratedValue
private Long id;
⠀
@NaturalId
private String name;
⠀
@ManyToMany(mappedBy = "tags")
private Set<Post> posts = new HashSet<>();
⠀
//Getters and setters omitted for brevity
⠀
@Override
public boolean equals(Object o) {
if (this == o)
return true;
⠀
if (!(o instanceof Tag))
return false;
⠀
Tag tag = (Tag) o;
return Objects.equals(name, tag.name);
}
⠀
@Override
public int hashCode() {
return Objects.hash(name);
}
}
Notice the use of the @NaturalId Hibernate-specific annotation which is very useful for mapping business keys.
Because the Tag entity has a business key, we can use that for implementing equals and hashCode as explained in this article.
The Post entity is then mapped as follows:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
⠀
@Id
@GeneratedValue
private Long id;
⠀
private String title;
⠀
public Post() {}
⠀
public Post(String title) {
this.title = title;
}
⠀
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new LinkedHashSet<>();
⠀
//Getters and setters omitted for brevity
⠀
public void addTag(Tag tag) {
tags.add(tag);
tag.getPosts().add(this);
}
⠀
public void removeTag(Tag tag) {
tags.remove(tag);
tag.getPosts().remove(this);
}
⠀
@Override
public boolean equals(Object o) {
if (this == o)
return true;
⠀
if (!(o instanceof Post)) return false;
⠀
return id != null && id.equals(((Post) o).getId());
}
⠀
@Override
public int hashCode() {
return getClass().hashCode();
}
}
The tags @ManyToMany association is responsible for handling this bidirectional association, and that’s also the reason why the posts @ManyToMany association in the Tag entity is marked with the mappedBy attribute.
The addTag and removeTag methods are used for synchronizing the bidirectional association. Because we rely on the remove method from the Set interface, both the Tag and Post must implement equals and hashCode properly. While Tag can use a natural identifier, the Post entity does not have such a business key. For this reason, we used the entity identifier to implement these two methods, as explained in this article.
To associate the Post and Tag entities, we can use the addTag method like this:
Post post1 = new Post("JPA with Hibernate");
Post post2 = new Post("Native Hibernate");
Tag tag1 = new Tag("Java");
Tag tag2 = new Tag("Hibernate");
post1.addTag(tag1);
post1.addTag(tag2);
post2.addTag(tag1);
entityManager.persist(post1);
entityManager.persist(post2);
To dissociate the Post and Tag entities, we can use the removeTag method:
Post post1 = entityManager.createQuery("""
select p
from Post p
join fetch p.tags
where p.id = :id
""", Post.class)
.setParameter( "id", postId )
.getSingleResult();
Tag javaTag = entityManager.unwrap(Session.class)
.bySimpleNaturalId(Tag.class)
.getReference("Java");
post1.removeTag(javaTag);
For more details about the best way to map a
@ManyToManyassociation, check out this article.
That’s it!
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Whenever you are using a bidirectional JPA association, it is mandatory to synchronizing both ends of the entity relationship.
Not only that working with a Domain Model, which does not enforce relationship consistency, is difficult and error prone, but without synchronizing both ends of a bidirectional association, the entity state transitions are not guaranteed to work.
So, save yourself some trouble and do the right thing.








