How does a relational database execute SQL statements and prepared statements
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, we are going to see how a relational database executes SQL statements and prepared statements.
SQL statement lifecycle
The main database modules responsible for processing a SQL statement are:
- the Parser,
- the Optimizer,
- the Executor.
A SQL statement execution looks like in the following diagram.
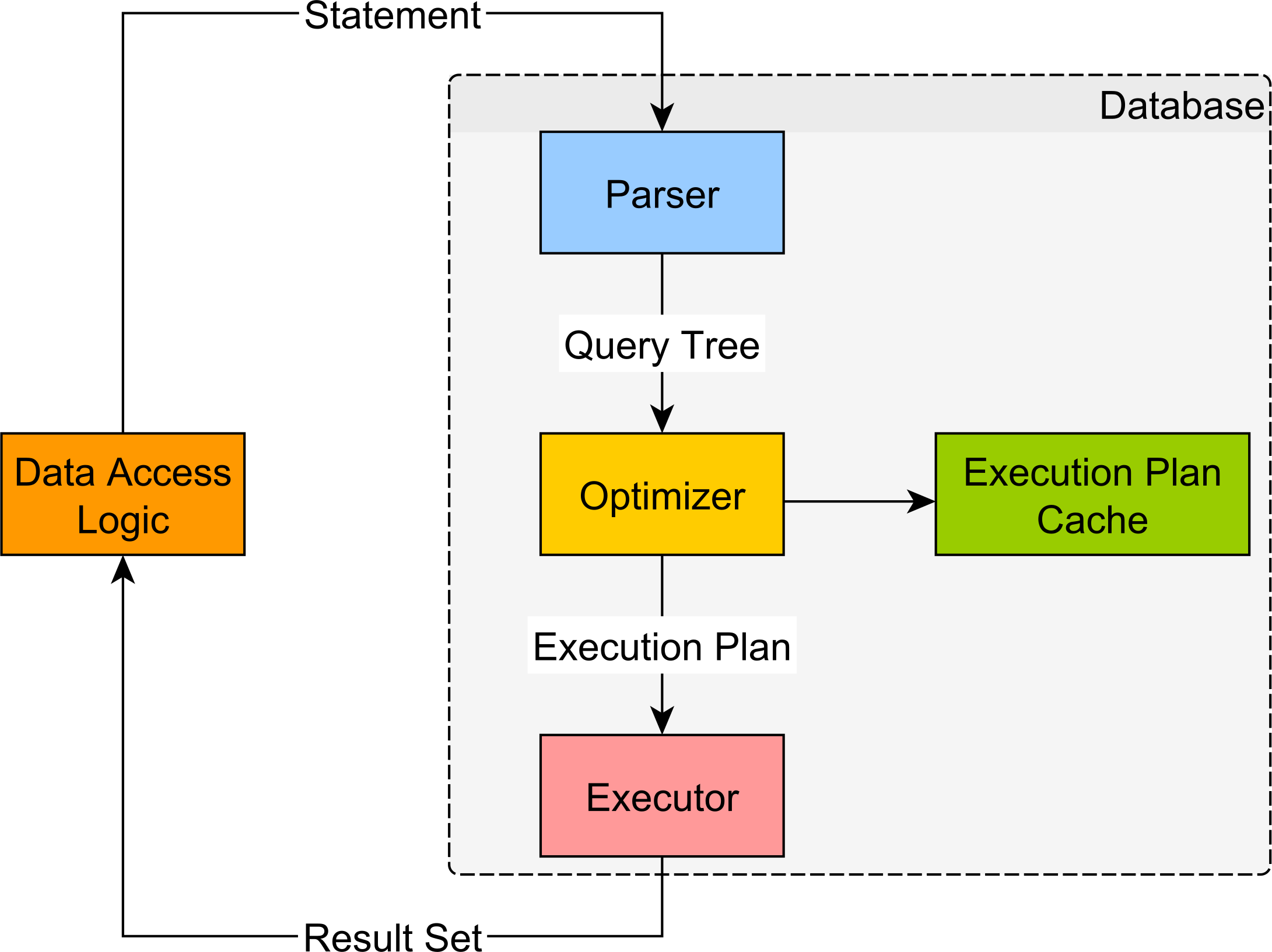
Parser
The Parser checks the SQL statement and ensures its validity. The statements are verified both syntactically (the statement keywords must be properly spelled and following the SQL language guidelines) and semantically (the referenced tables and column do exist in the database).
During parsing, the SQL statement is transformed into a database-internal representation, called the syntax tree (also known as parse tree or query tree).
If the SQL statement is a high-level representation (being more meaningful from a human perspective), the syntax tree is the logical representation of the database objects required for fulfilling the current statement.
Optimizer
For a given syntax tree, the database must decide the most efficient data fetching algorithm.
Data is retrieved by following an access path, and the Optimizer needs to evaluate multiple data traversing options like:
- The access method for each referencing table (table scan or index scan).
- For index scans, it must decide which index is better suited for fetching this result set.
- For each joining relation (e.g. table, views, or Common Table Expression), it must choose the best-performing join type (e.g., Nested Loops Joins, Hash Joins, Merge Joins).
- The joining order becomes very important, especially for Nested Loops Joins.
The list of access paths, chosen by the Optimizer, is assembled into an execution plan.
Because of a large number of possible action plan combinations, finding a good execution plan is not a trivial task.
The more time is spent on finding the best possible execution plan, the higher the transaction response time will get, so the Optimizer has a fixed time budget for finding a reasonable plan.
The most common decision-making algorithm is the Cost-Based Optimizer (CBO).
Each access method translates to a physical database operation, and its associated cost in resources can be estimated.
The database stores various statistics like table sizes and data cardinality (how much the column values differ from one row to the other) to evaluate the cost of a given database operation.
The cost is calculated based on the number of CPU cycles and I/O operations required for executing a given plan.
When finding an optimal execution plan, the Optimizer might evaluate multiple options, and, based on their overall cost, it chooses the one requiring the least amount of time to execute.
By now, it is clear that finding a proper execution plan is resource intensive, and, for this purpose, some database vendors offer execution plan caching (to eliminate the time spent on finding the optimal plan).
While caching can speed up statement execution, it also incurs some additional challenges (making sure the plan is still optimal across multiple executions).
Each execution plan has a given memory footprint, and most database systems use a fixed-size cache (discarding the least used plans to make room for newer ones).
DDL (Data Definition Language) statements might corrupt execution plans, making them obsolete, so the database must use a separate process for validating the existing execution plans relevancy.
However, the most challenging aspect of caching is to ensure that only a good execution plan goes in the cache, since a bad plan, getting reused over and over, can really hurt application performance.
Executor
From the Optimizer, the execution plan goes to the Executor where it is used to fetch the associated data and build the result set.
The Executor makes use of the Storage Engine (for loading data according to the current execution plan) and the Transaction Engine (to enforce the current transaction data integrity guarantees).
The Executor simply runs the execution plan which is like a runtime-generated program that tells the Executor how to fetch the data the client requires.
Prepared statements
Because statement parsing and the execution plan generation are resource intensive operations, some database providers offer an execution plan cache.
The statement string value is used as input to a hashing function, and the resulting value becomes the execution plan cache entry key.
If the statement string value changes from one execution to the other, the database cannot reuse an already generated execution plan.
For this purpose, dynamic-generated JDBC statements are not suitable for reusing execution plans.
Server-side prepared statements allow the data access logic to reuse the same execution plan for multiple executions. A prepared statement is always associated with a single SQL statement, and bind parameters are used to vary the runtime execution context.
Because prepared statements take the SQL query at creation time, the database can precompile the associated SQL statement prior to executing it.
During the pre-compilation phase, the database validates the SQL statement and parses it into a syntax tree. When it comes to executing the PreparedStatement, the driver sends the actual parameter values, and the database can jump to compiling and running the actual execution plan.
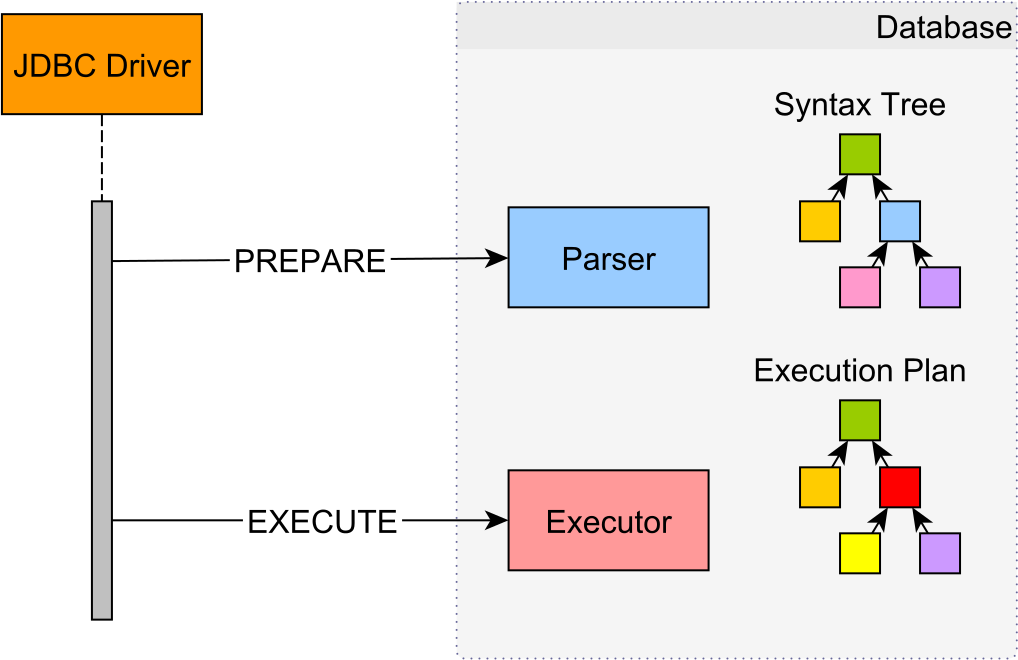
Conceptually, the prepare and the execution phases happen in separate database roundtrips. However, some database systems choose to optimize this process, therefore, multiplexing these two phases into a single database roundtrip.
Because of index selectivity, in the absence of the actual bind parameter values, the Optimizer cannot compile the syntax tree into an execution plan.
Since disk access is required for fetching every additional row-level data, indexing is suitable when selecting only a fraction of the whole table data. Most database systems take this decision based on the index selectivity of the current bind parameter values.
Because each disk access requires reading a whole block of data, accessing too many dispersed blocks can actually perform worse than scanning the whole table (random access is slower than sequential scans).
For prepared statements, the execution plan can either be compiled on every execution or it can be cached and reused.
Recompiling the plan can generate the best data access paths for any given bind variable set while paying the price of additional database resources usage.
Reusing a plan can spare database resources, but it might not be suitable for every parameter value combination.
PostgreSQL
Prior to 9.2, a prepared statement was planned and compiled entirely during the prepare phase, so the execution plan was generated in the absence of the actual bind parameter values.
Although meant to spare database resources, this strategy was very sensitive to skewed data.
Since PostgreSQL 9.2, the prepare phase only parses and rewrites a statement, while the optimization and the planning phase are deferred until execution time. This way, the rewritten syntax tree is optimized according to the actual bind parameter values, and an optimal execution plan is generated.
For a single execution, a plain statement requires only a one database roundtrip while a prepared statement needs two (a prepare request and an execution call).
To avoid the networking overhead, by default, JDBC PreparedStatement(s) do both the prepare and the execute phases over a single database request.
A client-side prepared statement must run at least 5 times for the driver to turn it into a server-side statement.
The default execution count value is given by the prepareThreshold parameter, which is configurable as a connection property or through a driver-specific API.
After several executions, if the performance is not sensitive to bind parameter values, the Optimizer might choose to turn the plan into a generic one and cache it for reuse.
MySQL
When preparing a statement, the MySQL Parser generates a syntax tree which is further validated and pre-optimized by a resolution mechanism. The syntax tree undergoes several data-insensitive transformations, and the final output is a permanent tree.
Since MySQL 5.7.4, all permanent transformations (rejoining orders or subquery optimizations) are done in the prepare phase, so the execution phase only applies data-sensitive transformations.
MySQL does not cache execution plans, so every statement execution is optimized for the current bind parameter values, therefore avoiding data skew issues.
Since version 5.0.5, the MySQL JDBC driver only emulates server-side prepared statements. To switch to server-side prepared statements, both the useServerPrepStmts and the cachePrepStmts connection properties must be set to true.
Before activating this feature, it is better to check the latest Connector/J release notes and validate this feature is safe for use.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Being a declarative language, SQL describes the what and not the how.
The actual database structures and the algorithms used for fetching and preparing the desired result set are hidden away from the database client, which only has to focus on properly defining the SQL statement.








