Hibernate database schema multitenancy
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
As I explained in this article, multitenancy is an architectural pattern which allows you to isolate customers even if they are using the same hardware or software components.
There are multiple ways you can achieve multitenancy, and in this article, we are going to see how you can implement a multitenancy architecture using the database schema as the unit of isolation.
Schema-based multitenancy database architecture
Schema-based multitenancy can be achieved using any relational database system which drives a distinction between a catalog and a schema. In this article, we are going to use PostgreSQL to demonstrate how we can implement a schema-based multitenancy architecture with JPA and Hibernate.
If we are running the following PostgreSQL query in the current database catalog:
select nspname as "Schema" from pg_catalog.pg_namespace where nspname not like 'pg_%';
PostgreSQL will list the following database schemas:
| Database |
|---|
| asia |
| europe |
| information_schema |
| performance_schema |
| sys |
Notice the asia and europe database schemas. These schemas are the two tenants we are going to use in our applications. So, if a user is located in Europe, she will connect to the europe schema while if the user is located in Asia, she will be redirected to the asia database schema.
All tenants contain the same database tables. For our example, let’s assume we are using the following users and posts tables:
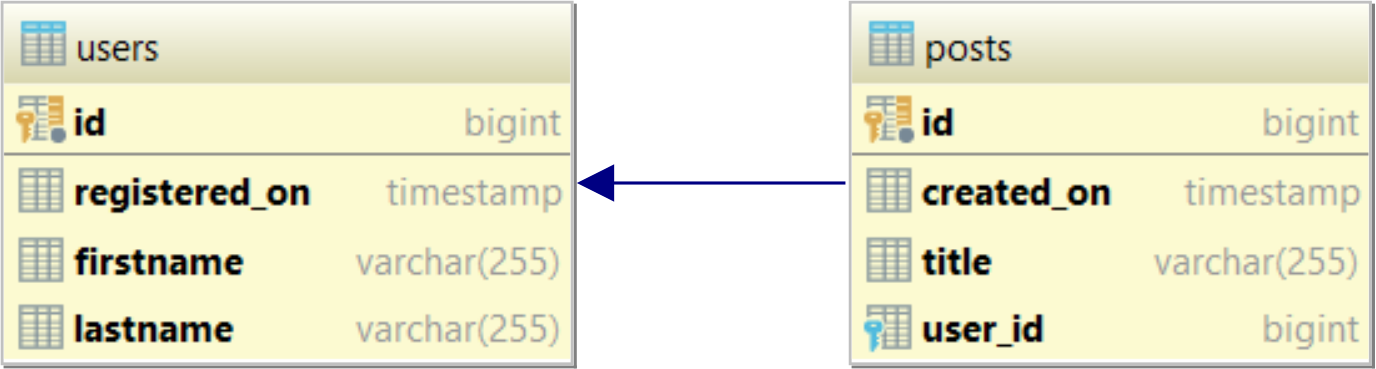
Domain Model
The aforementioned database tables can be mapped to the following JPA entities:
@Entity(name = "User")
@Table(name = "users")
public class User {
@Id
@GeneratedValue
private Long id;
private String firstName;
private String lastName;
@Column(name = "registered_on")
@CreationTimestamp
private LocalDateTime createdOn;
//Getters and setters omitted for brevity
}
@Entity(name = "Post")
@Table(name = "posts")
public class Post {
@Id
@GeneratedValue
private Long id;
private String title;
@Column(name = "created_on")
@CreationTimestamp
private LocalDateTime createdOn;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
//Getters and setters omitted for brevity
}
Hibernate multitenancy configuration
There are 3 settings we need to take care of when implementing a multitenancy architecture with Hibernate:
- the multitenancy strategy
- the
MultiTenancyConnectionProviderimplementation - the
CurrentTenantIdentifierResolverimplementation
Hibernate multitenancy strategy
The Hibernate MultiTenancyStrategy Java enumeration is used to specify what type of multitenancy architecture is being employed. For schema-based multitenancy, we need to use the MultiTenancyStrategy.SCHEMA value and pass it via the hibernate.multiTenancy configuration property:
<property name="hibernate.multiTenancy" value="SCHEMA"/>
MultiTenancyConnectionProvider implementation
Now, in order for Hibernate to properly route database connection requests to the database schema each user is associated to, we need to provide a MultiTenancyConnectionProvider implementation via the hibernate.multi_tenant_connection_provider configuration property:
properties.put(
AvailableSettings.MULTI_TENANT_CONNECTION_PROVIDER,
MultiTenantConnectionProvider.INSTANCE
);
In our example, the MultiTenantConnectionProvider class looks like this:
public class MultiTenantConnectionProvider
extends AbstractMultiTenantConnectionProvider {
public static final MultiTenantConnectionProvider INSTANCE =
new MultiTenantConnectionProvider();
private final Map<String, ConnectionProvider> connectionProviderMap =
new HashMap<>();
Map<String, ConnectionProvider> getConnectionProviderMap() {
return connectionProviderMap;
}
@Override
protected ConnectionProvider getAnyConnectionProvider() {
return connectionProviderMap.get(
TenantContext.DEFAULT_TENANT_IDENTIFIER
);
}
@Override
protected ConnectionProvider selectConnectionProvider(
String tenantIdentifier) {
return connectionProviderMap.get(
tenantIdentifier
);
}
}
The connectionProviderMap is used to store the Hibernate ConnectionProvider associated with a given tenant identifier. The Hibernate ConnectionProvider is a factory of database connections, hence each database schema will have its own ConnectionProvider instance.
To register a ConnectionProvider with our MultiTenantConnectionProvider we are going to use the following addTenantConnectionProvider method:
private void addTenantConnectionProvider(
String tenantId,
DataSource tenantDataSource,
Properties properties) {
DatasourceConnectionProviderImpl connectionProvider =
new DatasourceConnectionProviderImpl();
connectionProvider.setDataSource(tenantDataSource);
connectionProvider.configure(properties);
MultiTenantConnectionProvider.INSTANCE
.getConnectionProviderMap()
.put(
tenantId,
connectionProvider
);
}
We are using the JDBC DataSource to build a Hibernate DatasourceConnectionProviderImpl which is further associated with a given tenant identifier and stored in the connectionProviderMap.
For instance, we can register a default DataSource which is not associated with any tenant like this:
addTenantConnectionProvider(
TenantContext.DEFAULT_TENANT_IDENTIFIER,
defaultDataSource,
properties()
);
The default DataSource is going to be used by Hibernate when bootstrapping the EntityManagerFactory or whenever we don’t provide a given tenant identifier, which might be the case for the administration features of our enterprise system.
Now, to register the actual tenants, we can use the following addTenantConnectionProvider utility method:
private void addTenantConnectionProvider(
String tenantId) {
PGSimpleDataSource defaultDataSource = (PGSimpleDataSource) database()
.dataSourceProvider()
.dataSource();
Properties properties = properties();
PGSimpleDataSource tenantDataSource = new PGSimpleDataSource();
tenantDataSource.setDatabaseName(defaultDataSource.getDatabaseName());
tenantDataSource.setCurrentSchema(tenantId);
tenantDataSource.setServerName(defaultDataSource.getServerName());
tenantDataSource.setUser(defaultDataSource.getUser());
tenantDataSource.setPassword(defaultDataSource.getPassword());
properties.put(
Environment.DATASOURCE,
dataSourceProxyType().dataSource(tenantDataSource)
);
addTenantConnectionProvider(tenantId, tenantDataSource, properties);
}
And our two tenants will be registered like this:
addTenantConnectionProvider("asia");
addTenantConnectionProvider("europe");
CurrentTenantIdentifierResolver implementation
The last thing we need to supply to Hibernate is the implementation of the CurrentTenantIdentifierResolver interface. This is going to be used to locate the tenant identifier associated with the current running Thread.
For our application, the CurrentTenantIdentifierResolver implementation looks like this:
public class TenantContext {
public static final String DEFAULT_TENANT_IDENTIFIER = "public";
private static final ThreadLocal<String> TENANT_IDENTIFIER =
new ThreadLocal<>();
public static void setTenant(String tenantIdentifier) {
TENANT_IDENTIFIER.set(tenantIdentifier);
}
public static void reset(String tenantIdentifier) {
TENANT_IDENTIFIER.remove();
}
public static class TenantIdentifierResolver
implements CurrentTenantIdentifierResolver {
@Override
public String resolveCurrentTenantIdentifier() {
String currentTenantId = TENANT_IDENTIFIER.get();
return currentTenantId != null ?
currentTenantId :
DEFAULT_TENANT_IDENTIFIER;
}
@Override
public boolean validateExistingCurrentSessions() {
return false;
}
}
}
When using Spring, the
TenantContextcan use aRequestScopebean that provides the tenant identifier of the current Thread, which was resolved by an AOP Aspect prior to calling theServicelayer.
To provide the CurrentTenantIdentifierResolver implementation to Hibernate, you need to use the hibernate.tenant_identifier_resolver configuration property:
properties.setProperty(
AvailableSettings.MULTI_TENANT_IDENTIFIER_RESOLVER,
TenantContext.TenantIdentifierResolver.class.getName()
);
Testing time
Now, when running the folloiwng test case:
TenantContext.setTenant("europe");
User vlad = doInJPA(entityManager -> {
LOGGER.info(
"Current schema: {}",
entityManager.createNativeQuery(
"select current_schema()")
.getSingleResult()
);
User user = new User();
user.setFirstName("Vlad");
user.setLastName("Mihalcea");
entityManager.persist(user);
return user;
});
Hibernate is going to insert the User entity in the europe tenant:
INFO [main]: SchemaMultitenancyTest - Current schema: europe
LOG: execute <unnamed>: BEGIN
LOG: execute <unnamed>: select nextval ('hibernate_sequence')
LOG: execute <unnamed>:
insert into users (
registered_on,
firstName,
lastName,
id
)
values (
$1,
$2,
$3,
$4
)
DETAIL: parameters:
$1 = '2018-08-29 09:38:13.042',
$2 = 'Vlad',
$3 = 'Mihalcea',
$4 = '1'
LOG: execute S_1: COMMIT
Notice the europe database identifier in the MySQL log.
Assuming other user logs in and is associated with the asia tenant:
TenantContext.setTenant("asia");
When persisting the following User entity:
doInJPA(entityManager -> {
LOGGER.info(
"Current schema: {}",
entityManager.createNativeQuery(
"select current_schema()")
.getSingleResult()
);
User user = new User();
user.setFirstName("John");
user.setLastName("Doe");
entityManager.persist(user);
});
Hibernate will insert it in the asia database schema:
INFO [main]: SchemaMultitenancyTest - Current schema: asia
LOG: execute <unnamed>: BEGIN
LOG: execute <unnamed>: select nextval ('hibernate_sequence')
LOG: execute <unnamed>:
insert into users (
registered_on,
firstName,
lastName,
id
)
values (
$1,
$2,
$3,
$4
)
DETAIL: parameters:
$1 = '2018-08-29 09:39:52.448',
$2 = 'John',
$3 = 'Doe',
$4 = '1'
LOG: execute S_1: COMMIT
When switching back to the europe tenant and persisting a Post entity associated with the vlad User entity we have previously saved into the database:
TenantContext.setTenant("europe");
doInJPA(entityManager -> {
LOGGER.info(
"Current schema: {}",
entityManager.createNativeQuery(
"select current_schema()")
.getSingleResult()
);
Post post = new Post();
post.setTitle("High-Performance Java Persistence");
post.setUser(vlad);
entityManager.persist(post);
});
Hibernate will execute the statements to the europe database schema:
INFO [main]: SchemaMultitenancyTest - Current schema: europe
LOG: execute <unnamed>: BEGIN
LOG: execute <unnamed>: select nextval ('hibernate_sequence')
LOG: execute <unnamed>:
insert into users (
registered_on,
firstName,
lastName,
id
)
values (
$1,
$2,
$3,
$4
)
DETAIL: parameters:
$1 = '2018-08-29 09:43:00.683',
$2 = 'High-Performance Java Persistence',
$3 = '1',
$4 = '2'
LOG: execute S_1: COMMIT
Cool, right?
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
Implementing a multitenancy architecture with Hibernate is fairly easy, yet very powerful. The schema-based multitenancy strategy is very suitable for database systems that draw a clear distinction between a database catalog and a schema, like PostgreSQL.









