A beginner’s guide to database multitenancy
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In software terminology, multitenancy is an architectural pattern that allows you to isolate customers even if they are using the same hardware or software components. Multitenancy has become even more attractive with the widespread adoption of cloud computing.
A relational database system provides a hierarchy structure of objects which, typically, looks like this: catalog -> schema -> table. In this article, we are going to see how we can use each of these database object structures to accommodate a multitenancy architecture.
Catalog-based multitenancy
In a catalog-based multitenancy architecture, each customer uses its own database catalog. Therefore, the tenant identifier is the database catalog itself.
Since each customer will only be granted access to its own catalog, it’s very easy to achieve customer isolation. More, the data access layer is not even aware of the multitenancy architecture, meaning that the data access code can focus on business requirements only.
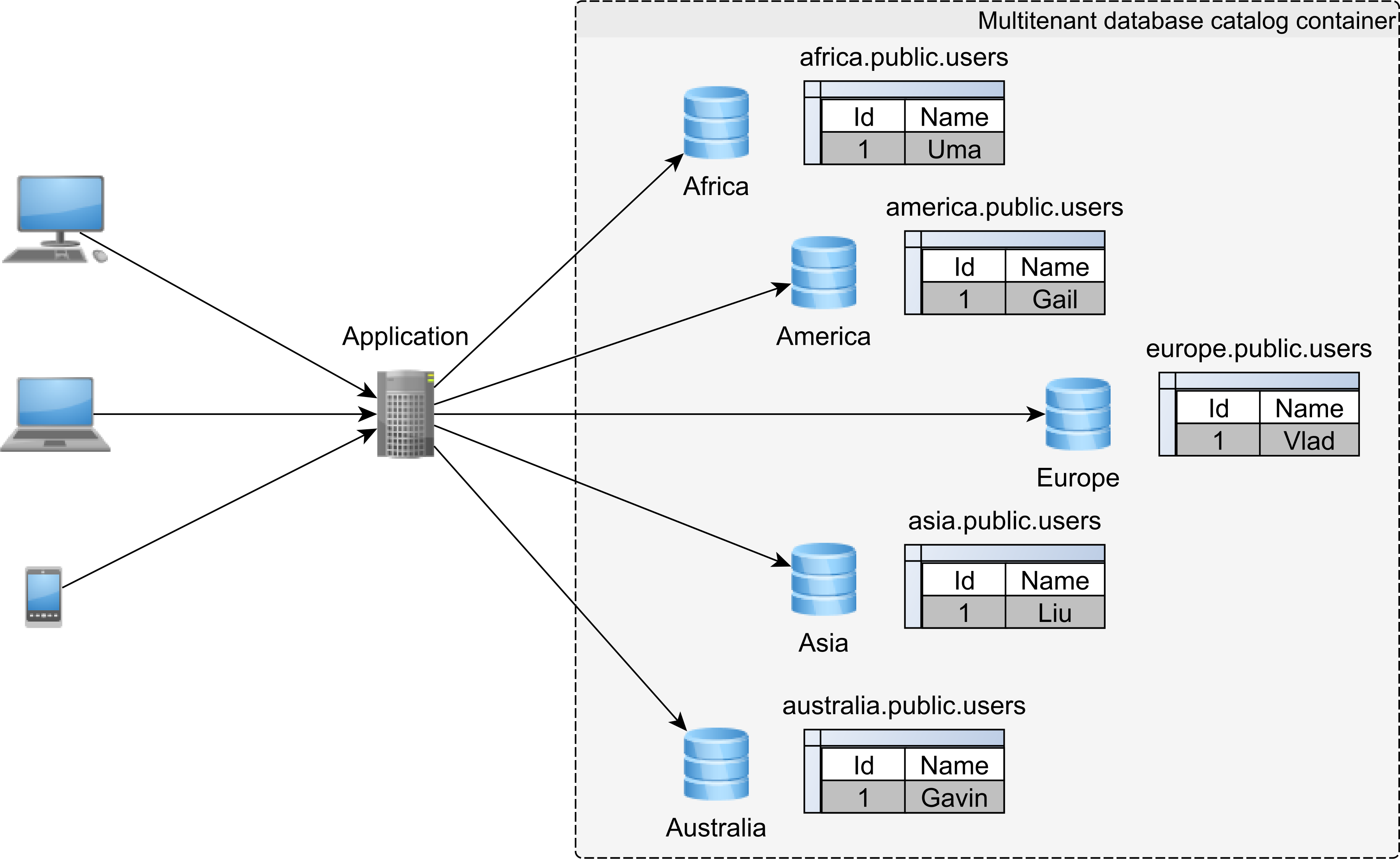
This strategy is very useful when using a relational database system that doesn’t make any distinction between a catalog and a schema, like MySQL, for instance.
The disadvantage of this strategy is that it requires more work on the Ops side: monitoring, replication, backups. However, with automation in place, this problem could be mitigated.
For more details about catalog-based multitenancy, check out this article.
Schema-based multitenancy
In a schema-based multitenancy architecture, each custom uses its own database schema. Therefore, the tenant identifier is the database schema itself.
Since each customer will only be granted access to its own schema, it’s very easy to achieve customer isolation. Also, the data access layer is not even aware of the multitenancy architecture, meaning that, just like for catalog-based multitenancy, the data access code can focus on business requirements only.

This strategy is useful for relational database systems like PostgreSQL which support multiple schemas per database (catalog). Replication, backing up, and monitoring can be set up on the catalog-level, hence all schemas could benefit from it.
However, if schemas are colocated on the same hardware, one tenant which runs a resource-intensive job might incur latency spikes in other tenants. Therefore, although data is isolated, sharing resources might make it difficult to honor the Service-Level Agreement.
For more details about schema-based multitenancy, check out this article.
Table-based multitenancy
In a table-based multitenancy architecture, multiple customers reside in the same database catalog and/or schema. To provide isolation, a tenant identifier column must be added to all tables that are shared between multiple clients.
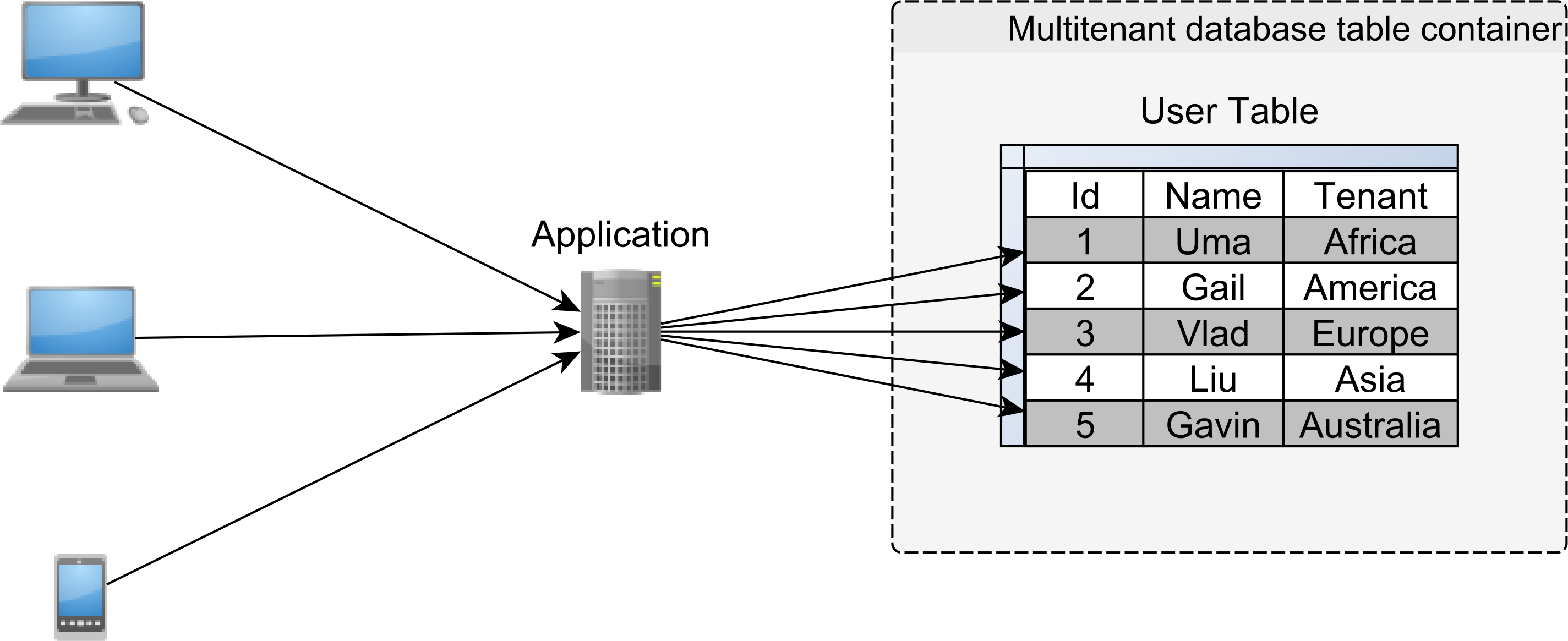
While on the Ops side, this strategy requires no additional work, the data access layer needs extra logic to make sure that each customer is allowed to see only its data and to prevent data leaking from one tenant to the other. Also, since multiple customers are stored together, tables and indexes might grow larger, putting pressure on SQL statement performance.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
As you can see, there are multiple strategies to implement a multitenancy architecture on the database side. However, each one has its own advantages and disadvantages, so you must make sure you choose the right strategy according to your project DevOps requirements.








