9 High-Performance Tips when using MySQL with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
Although there is an SQL Standard, every relational database is ultimately unique, and you need to adjust your data access layer so that you get the most out of the relational database in use.
In this article, we are going to see what you can do to boost up performance when using MySQL with JPA and Hibernate.
Don’t use the AUTO identifier GeneratorType
Every entity needs to have an identifier that uniquely identifies the table record associated with this entity. JPA and Hibernate allow you to automatically generate entity identifiers based on three different strategies:
- IDENTITY
- SEQUENCE
- TABLE
As I explained in this article, The TABLE identifier strategy does not scale when increasing the number of database connections. More, even for one database connection, the identifier generation response time is 10 times greater than when using IDENTITY or SEQUENCE.
If you are using the AUTO GenerationType:
@Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id;
Hibernate 5 is going to fall back to using the TABLE generator, which is bad for performance.
As I explained in this article, you can easily fix this issue with the following mapping:
@Id @GeneratedValue(strategy= GenerationType.AUTO, generator="native") @GenericGenerator(name = "native", strategy = "native") private Long id;
The native generator will pick IDENTITY instead of TABLE.
IDENTITY generator disables JDBC batch inserts
Neither MySQL 5.7 nor 8.0 support SEQUENCE objects. You need to use IDENTITY. However, as I explained in this article, the IDENTITY generator prevents Hibernate from using JDBC batch inserts.
JDBC batch updates and deletes are not affected. Only the INSERT statements cannot be batched automatically by Hibernate because, by the time the Persistence Context is flushed, the INSERT statements were already executed so that Hibernate knows what entity identifier to assign to the entities that got persisted.
If you want to fix this issue, you have to execute the JDBC batch inserts with a different framework, like jOOQ.
Speed-up integration testing with Docker and tmpfs
MySQL and MariaDB are notoriously slow when having to discard the database schema and recreating it every time a new integration test is about to run. However, you can easily address this issue with the help of Docker and tmpfs.
As I explained in this article, by mapping the data folder in-memory, integration tests are going to run almost as fast as with an in-memory database like H2 or HSQLDB.
Use JSON for non-structured data
Even when you are using a RDBMS, there are many times when you want to store non-structured data:
- data coming from the client as JSON, which needs to be parsed and inserted into our system.
- image processing results which can be cached to save reprocessing them
Although not supported natively, you can easily map a Java object to a JSON column. You can even map the JSON column type to a Jackson JsonNode.
More, you don’ even have to write these custom types. You can just grab them from Maven Central:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-utils-hibernate-55</artifactId>
<version>${hypersistence-utils.version}</version>
</dependency>
Cool, right?
Use Stored Procedures to save database roundtrips
When processing large volumes of data, it’s not very efficient to move all this data in and out of the database. It’s much better to do the processing on the database side by calling a Stored Procedure.
For more details, check out this article about how you can call a MySQL Stored Procedure with JPA and Hibernate.
Watch out for ResultSet streaming
SQL streaming makes sense for two-tier applications. If you want to do ResultSet streaming, you have to pay attention to the JDBC Driver as well. On MySQL, to use a database cursor, you have two options:
- either you set the JDBC
StatementfetchSizeproperty toInteger.MIN_VALUE, - or you have to set the
useCursorFetchconnection property totrueand then you can set the JDBCStatementfetchSizeproperty to a positive integer value
However, for web-based applications, pagination is much more suitable. JPA 2.2 even introduces support for Java 1.8 Stream methods, but the Execution Plan might not be as efficient as when using SQL-level pagination.
PreparedStatements might be emulated
Since Hibernate uses PreparedStatements by default, you might think that all statements are executed like this:
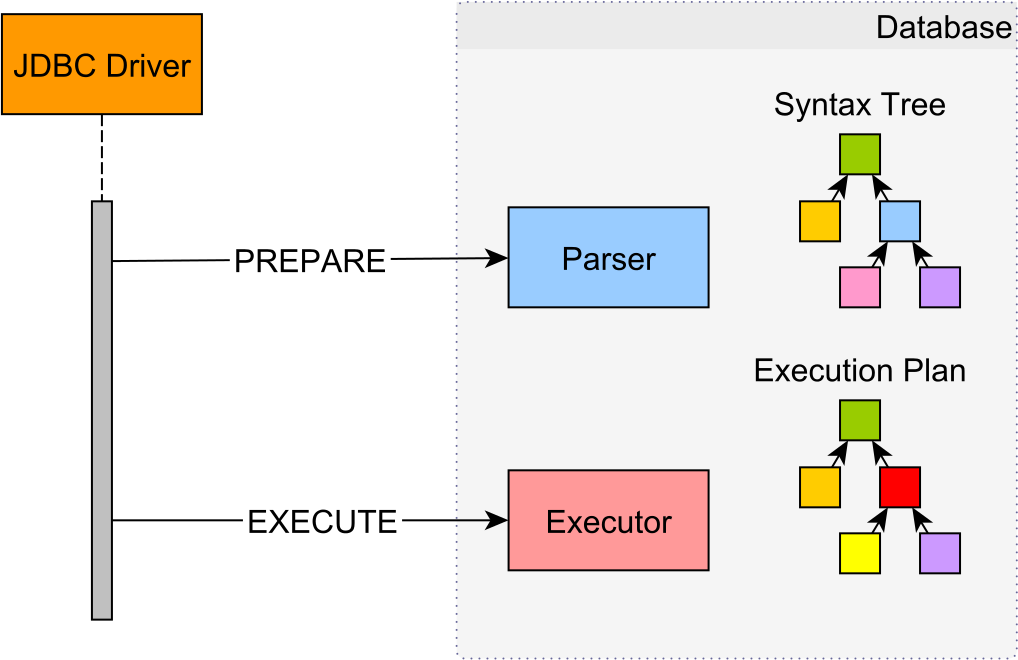
In reality, they are executed more like this:

As I explained in this article, unless you set the useServerPrepStmts MySQL JDBC Driver property, PreparedStatements are going to be emulated at the JDBC Driver level to save one extra database roundtrip.
Always end database transactions
In a relational database, every statement is executed within a given database transaction. Therefore, transactions are not optional.
However, you should always end the current running transaction, either through a commit or a rollback. Forgetting to end transactions can lead to locks being held for a very long time, as well as preventing the MVCC cleanup process from reclaiming old tuples or index entries that are no longer needed.
Handing Date/Time is not that easy
There are two very complicated things in programming:
- handling encodings
- handing Date/Time across multiple Timezones
To address the second problem, it’s better to save all timestamps in UTC timezone. However, prior to the MySQL Connector/J 8.0, you also needed to set the useLegacyDatetimeCode JDBC Driver configuration property to false. Since MySQL Connector/J 8.0, you don’t need to provide this property.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
As you can see, there are many things to keep in mind when using MySQL with JPA and Hibernate. Since MySQL is one of the most deployed RDBMS, being used by the vast majority of web applications, it’s very useful to know all these tips and adjust your data access layer to get the most out of it.








