Maximum number of database connections
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
Have you ever wondered what the maximum number of database connections provided by a given RDBMS is?
In this article, we are going to see what limits the number of database connections, no matter if you’re using Oracle, SQL Server, PostgreSQL, or MySQL.
Oracle
If you’re using Oracle, you can use the V$RESOURCE_LIMIT view to inspect the maximum limits for various system resources, as well as the current allocation numbers.
In our case, we are interested in the processes and sessions resources, so we can use the following query to gather this info:
SELECT
RESOURCE_NAME,
CURRENT_UTILIZATION,
MAX_UTILIZATION,
INITIAL_ALLOCATION,
LIMIT_VALUE
FROM
V$RESOURCE_LIMIT
WHERE
RESOURCE_NAME IN (
'processes',
'sessions'
)
And when running this SQL query on my local Oracle XE database, I get the following result:
| RESOURCE_NAME | CURRENT_UTILIZATION | MAX_UTILIZATION | INITIAL_ALLOCATION | LIMIT_VALUE | |---------------|---------------------|-----------------|--------------------|-------------| | processes | 77 | 88 | 1000 | 1000 | | sessions | 104 | 113 | 1528 | 1528 |
The processes record shows that my current Oracle database has a hard limit of 1000 OS processes that can connect to it, and the sessions row tells us that this particular Oracle XE database supports a maximum number of 1528 concurrent connections.
However, as we will soon see, using 1500 concurrent connections on my current notebook would be a terrible idea since, in reality, the maximum connection count is relative to the underlying system resources, and such a high concurrency value would easily saturate the very limited resources of my notebook.
SQL Server
According to the SQL Server documentation:
SQL Server allows a maximum of 32,767 user connections. Because
user connectionsis a dynamic (self-configuring) option, SQL Server adjusts the maximum number of user connections automatically as needed, up to the maximum value allowable.
PostgreSQL
PostgreSQL provides a max_connections setting that has a default value of 100.
Because database connections in PostgreSQL run on individual OS processes, you don’t want to set the max_connections to a very high value, as that will hurt the throughput of your database system.
MySQL
MySQL also provides a max_connections setting to control the maximum number of concurrent connections, and the default value is 151.
What limits the maximum number of connections?
In reality, even without setting a hard limit on the maximum number of connections, there will always be a maximum number of connections that provides the maximum throughput.
If you read the amazing Java Concurrency in Practice, then you are familiar with Amdahl’s law that gives the relationship between the maximum number of connections and the ability of the execution plans to parallelize, but this is just half the story.
Amdahl’s law only tells us that a system with limited resources can reach its maximum throughput, but it doesn’t take into consideration the cost of adding more connections.
That’s why a much better formula is the Universal Scalability Law, which provides the relationship between throughput and the number of concurrent connections, which tells us that after reaching the maximum throughput, adding more connections will lower the throughput since the system will have to spend resources to coordinate all the concurrent connections.
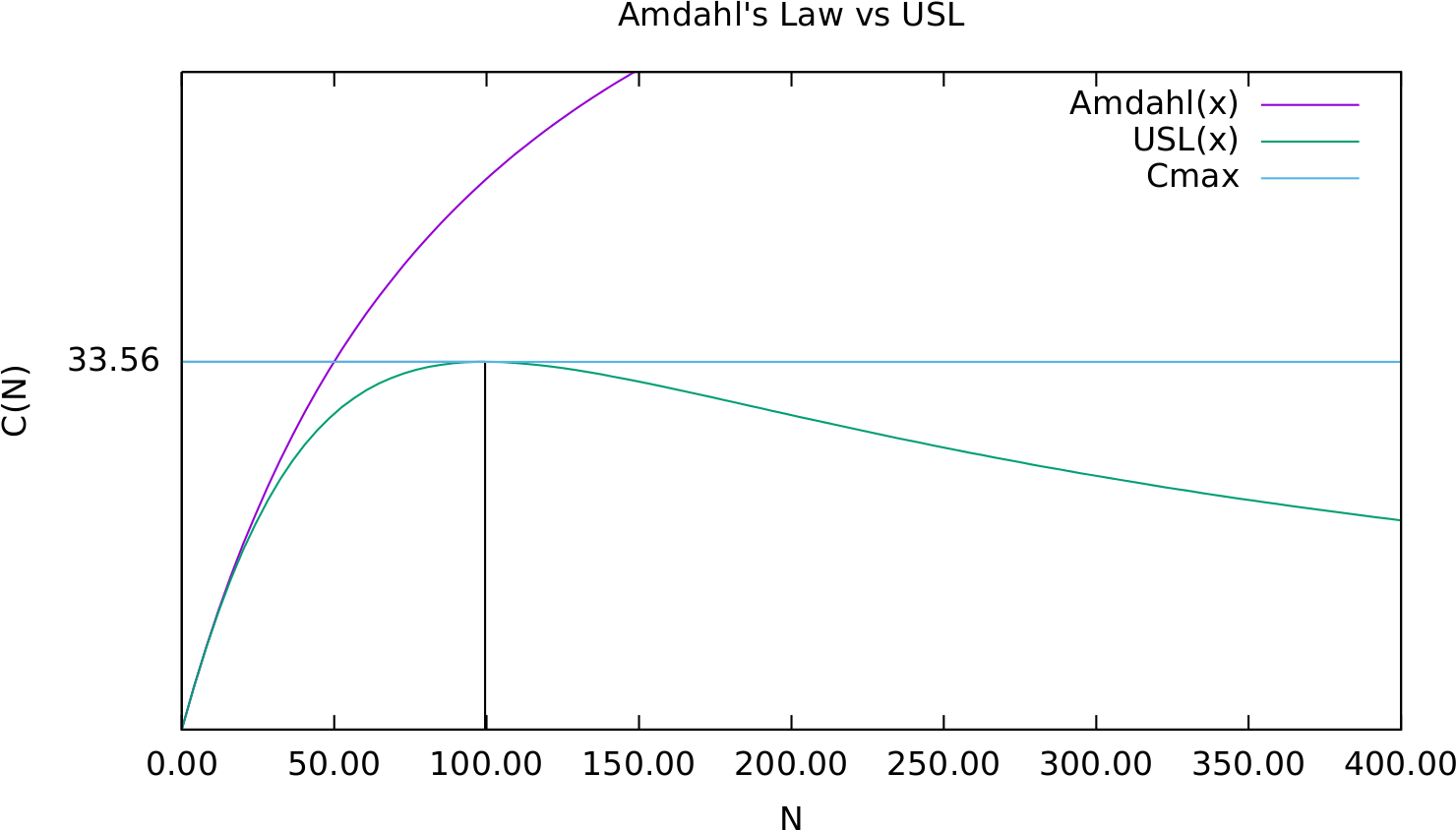
So, in reality, the maximum number of connections a given database system provides is determined by the underlying hardware resources (e.g., CPU, IO, memory), optimizer capabilities, and the load that’s incurred by the SQL statements sent by clients.
By default, the maximum number of connection connections is set way too high, risking resource starvation on the database side.
Therefore, only a performance load test will provide you with the maximum number of connections that can deliver the best throughput on your particular system. That value should be used then as the maximum number of connections that can be shared by all application nodes that connect to the database.
If the maximum number of connections is set too high, as it’s the case with many default settings, then you risk oversubscribing connection requests that starve DB resources, as explained in this very good video presentation.
How to increase the maximum number of database connections
While theoretically, a database like SQL Server allows you to open 32,767 connections, in practice, a system resource bottleneck will emerge at a much lower value.
So, there are two ways to increase the maximum number of connections:
- scaling vertically
- scaling horizontally
Vertical scaling is done by improving hardware resources, and the best real-life example of a system that has managed to scale vertically for over a decade is Stack Overflow. If you check the Stack Overflow performance stats, you will see that they manage to serve 1.3 billion page views with just two SQL Server nodes that have 1.5 TB of data to store the entire working set of table and index pages in the Buffer Pool.
Horizontal scaling is done via database replication, which adds extra resources to the system by adding more database nodes to which users can establish extra connections.

While scaling read-only transactions is easy since you can just add more replica nodes, scaling read-write transactions is harder because in a Single-Primary Replication scheme, there can only be one and only one Primary node.
How to split connections among multiple application nodes?
The Primary Node has a maximum number of connections that it can serve to its clients, but connections can be established from multiple applications (e.g., front-end nodes, batch processing tasks).
So, how can you split a limited number of connections to multiple application nodes?
There are two ways to achieve this goal:
- You can set up an application-level connection pool, like HikariCP, and use FlexyPool to determine the maximum number of connections a given application node needs.
- You can use ProxySQL or HAProxy in front of the Primary Node and let the application borrow connections from this connection pool service instead of getting them directly from the database system.
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
While many database systems provide a given limit on the maximum number of connections, in reality, that setting is not very useful as the actual limit is given by the underlying system resources (e.g., CPU, IO, memory), database optimizer algorithms, and the incoming load from clients.
Since each system is unique, you will have to determine the maximum number of connections via performance load testing. Afterward, you can increase the read-only connection limit via replication and the read-write connection limit by scaling up the Primary Node.










How load tests can show the max number? I execute the test by increasing the max number of connections until see that performance is degrading?
That’s best determined using a load test that aims for maximum throughput.
Yes, you run multiple variations of the number of connections and based on the Universal Scalability Law, you draw the throughput chart.
How to deal with the trade off of inconsistency data when replicating data base horizontally?
It’s basically the same with a single node since after you read a record from the DB and prepare the response to the client, that record can be changed by a concurrent transaction. You don’t need multiple nodes to get stale data.
Hi Vlad,
Thank You for the post. As you said 32.327 is the max limit of sql server what is the upper limit for oracle.
The upper limit is not given by a number that you configure, but by the underlying hardware and concurrency level. You can use the Universal Scalability Law to find that number.