The best Spring Data JpaRepository
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to show you the best way to use the Spring Data JpaRepository, which, most often, is used the wrong way.
The biggest issue with the default Spring Data JpaRepository is the fact that it extends the generic CrudRepository, which is not really compatible with the JPA specification.
The JpaRepository save method paradox
There’s no such thing as a save method in JPA because JPA implements the ORM paradigm, not the Active Record pattern.
JPA is basically an entity state machine, as illustrated by the following diagram:
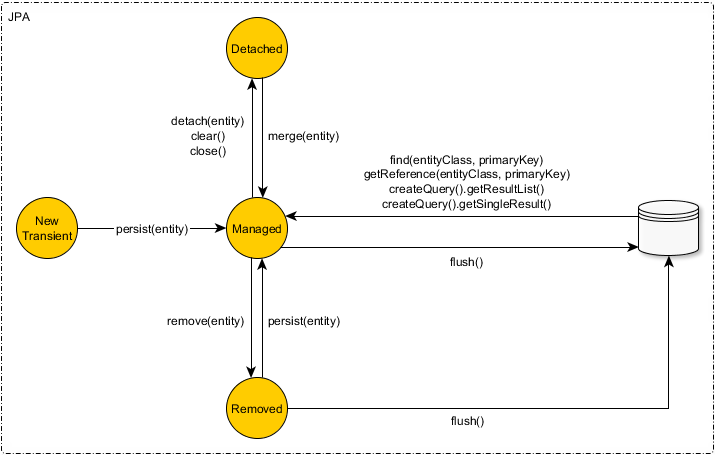
As you can clearly see, there’s no save method in JPA.
Now, Hibernate was created before JPA, hence besides implementing the JPA specification, it also provides its own specific methods, such as the update one.
While there are two methods called
saveandsaveOrUpdatein the HibernateSession, as I explained in this article, they are just an alias forupdate.In fact, starting with Hibernate 6, the
saveandsaveOrUpdatemethods are now deprecated and will be removed in a future version as they are just a mistake that got carried away from Hibernate 1.
If you create a new entity, you have to call persist so that the entity becomes managed, and the flush will generate the INSERT statement.
If the entity becomes detached and you changed it, you have to propagate the changes back to the database, in which case you can use either merge or update. The former method, merge, copies the detached entity state onto a new entity that has been loaded by the current Persistence Context and lets the flush figure out whether an UPDATE is even necessary. The latter method, update, forces the flush to trigger an UPDATE with the current entity state.
The remove method schedules the removal, and the flush will trigger the DELETE statement.
But, the JpaRepository inherits a save method from the CrudRepository, just like MongoRepository or SimpleJdbcRepository.
However, the MongoRepository and SimpleJdbcRepository take the Active Record approach, while JPA does not.
In fact, the save method of the JpaRepository is implemented like this:
@Transactional
public <S extends T> S save(S entity) {
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}
There’s no magic behind the scenes. It’s just either a call to persist or merge in reality.
The save method anti-pattern
Because the JpaRepository features a save method, the vast majority of software developers treat it as such, and you end up bumping into the following anti-pattern:
@Transactional
public void saveAntiPattern(Long postId, String postTitle) {
⠀
Post post = postRepository.findById(postId).orElseThrow();
⠀
post.setTitle(postTitle);
⠀
postRepository.save(post);
}
How familiar is that? How many times did you see this “pattern” being employed?
The problem is the save line, which, while unnecessary, it’s not cost-free. Calling merge on a managed entity burns CPU cycles by triggering a MergeEvent, which can be cascaded further down the entity hierarchy only to end up in a code block that does this:
protected void entityIsPersistent(MergeEvent event, Map copyCache) {
LOG.trace("Ignoring persistent instance");
⠀
final Object entity = event.getEntity();
final EventSource source = event.getSession();
⠀
final EntityPersister persister = source.getEntityPersister(
event.getEntityName(),
entity
);
⠀
//before cascade!
( (MergeContext) copyCache ).put( entity, entity, true );
⠀
cascadeOnMerge( source, persister, entity, copyCache );
copyValues( persister, entity, entity, source, copyCache );
⠀
event.setResult( entity );
}
Not only that the merge call doesn’t provide anything beneficial, but it actually adds extra overhead to your response time and makes the cloud provider wealthier with every such call.
And that’s not all. As I explained in this article, the generic save method is not always able to determine whether an entity is new. For instance, if the entity has an assigned identifier, Spring Data JPA will call merge instead of persist, therefore triggering a useless SELECT query. If this happens in the context of a batch processing task, then it’s even worse, you can generate lots of such useless SELECT queries.
So, don’t do that! You can do way better.
The best Spring Data JpaRepository alternative
If the save method is there, people will misuse it. That’s why it’s best not to have it at all and provide the developer with better JPA-friendly alternatives.
The following solution uses the custom Spring Data JPA Repository idiom.
So, we start with the custom HibernateRepository interface that defines the new contract for propagating entity state changes:
public interface HibernateRepository<T> {
⠀
//The findAll method will trigger an UnsupportedOperationException
⠀
@Deprecated
List<T> findAll();
⠀
//Save methods will trigger an UnsupportedOperationException
⠀
@Deprecated
<S extends T> S save(S entity);
⠀
@Deprecated
<S extends T> List<S> saveAll(Iterable<S> entities);
⠀
@Deprecated
<S extends T> S saveAndFlush(S entity);
⠀
@Deprecated
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
⠀
//Persist methods are meant to save newly created entities
⠀
<S extends T> S persist(S entity);
⠀
<S extends T> S persistAndFlush(S entity);
⠀
<S extends T> List<S> persistAll(Iterable<S> entities);
⠀
<S extends T> List<S> persistAllAndFlush(Iterable<S> entities);
⠀
//Merge methods are meant to propagate detached entity state changes
//if they are really needed
⠀
<S extends T> S merge(S entity);
⠀
<S extends T> S mergeAndFlush(S entity);
⠀
<S extends T> List<S> mergeAll(Iterable<S> entities);
⠀
<S extends T> List<S> mergeAllAndFlush(Iterable<S> entities);
⠀
//Update methods are meant to force the detached entity state changes
⠀
<S extends T> S update(S entity);
⠀
<S extends T> S updateAndFlush(S entity);
⠀
<S extends T> List<S> updateAll(Iterable<S> entities);
⠀
<S extends T> List<S> updateAllAndFlush(Iterable<S> entities);
}
The methods in the HibernateRepository interface are implemented by the HibernateRepositoryImpl class, as follows:
public class HibernateRepositoryImpl<T> implements HibernateRepository<T> {
⠀
@PersistenceContext
private EntityManager entityManager;
⠀
public List<T> findAll() {
throw new UnsupportedOperationException("Fetching all records from a given database table is a terrible idea!");
}
⠀
public <S extends T> S save(S entity) {
return unsupportedSave();
}
⠀
public <S extends T> List<S> saveAll(Iterable<S> entities) {
return unsupportedSave();
}
⠀
public <S extends T> S saveAndFlush(S entity) {
return unsupportedSave();
}
⠀
public <S extends T> List<S> saveAllAndFlush(Iterable<S> entities) {
return unsupportedSave();
}
⠀
public <S extends T> S persist(S entity) {
entityManager.persist(entity);
return entity;
}
⠀
public <S extends T> S persistAndFlush(S entity) {
persist(entity);
entityManager.flush();
return entity;
}
⠀
public <S extends T> List<S> persistAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
return result;
}
⠀
public <S extends T> List<S> persistAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
entityManager.flush();
return result;
});
}
⠀
public <S extends T> S merge(S entity) {
return entityManager.merge(entity);
}
⠀
public <S extends T> S mergeAndFlush(S entity) {
S result = merge(entity);
entityManager.flush();
return result;
}
⠀
public <S extends T> List<S> mergeAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
return result;
}
⠀
public <S extends T> List<S> mergeAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
entityManager.flush();
return result;
});
}
⠀
public <S extends T> S update(S entity) {
session().update(entity);
return entity;
}
⠀
public <S extends T> S updateAndFlush(S entity) {
update(entity);
entityManager.flush();
return entity;
}
⠀
public <S extends T> List<S> updateAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
return result;
}
⠀
public <S extends T> List<S> updateAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
entityManager.flush();
return result;
});
}
⠀
protected Integer getBatchSize(Session session) {
SessionFactoryImplementor sessionFactory = session
.getSessionFactory()
.unwrap(SessionFactoryImplementor.class);
⠀
final JdbcServices jdbcServices = sessionFactory
.getServiceRegistry()
.getService(JdbcServices.class);
⠀
if(!jdbcServices.getExtractedMetaDataSupport().supportsBatchUpdates()) {
return Integer.MIN_VALUE;
}
return session
.unwrap(AbstractSharedSessionContract.class)
.getConfiguredJdbcBatchSize();
}
⠀
protected <R> R executeBatch(Supplier<R> callback) {
Session session = session();
Integer jdbcBatchSize = getBatchSize(session);
Integer originalSessionBatchSize = session.getJdbcBatchSize();
try {
if (jdbcBatchSize == null) {
session.setJdbcBatchSize(10);
}
return callback.get();
} finally {
session.setJdbcBatchSize(originalSessionBatchSize);
}
}
⠀
protected Session session() {
return entityManager.unwrap(Session.class);
}
⠀
protected <S extends T> S unsupportedSave() {
throw new UnsupportedOperationException(
"There's no such thing as a save method in JPA, so don't use this hack!"
);
}
}
First, all the save methods trigger an UnsupportedOperationException, forcing you to evaluate which entity state transition you are actually supposed to call instead.
Unlike the dummy saveAllAndFlush, the persistAllAndFlush, mergeAllAndFlush, and updateAllAndFlush can benefit from the automatic batching mechanism even if you forgot to configure it previously, as explained in this article.
Testing time
To use the HibernateRepository, all you have to do is extend it beside the standard JpaRepository, like this:
@Repository
public interface PostRepository
extends HibernateRepository<Post>, JpaRepository<Post, Long> {
⠀
}
Notice that we extend the
HibernateRepositoryfirst and then theJpaRepository. The order is important as, this way, thefinaAllmethod will be deprecated by your IDE.
That’s it!
This time, there’s no way you can ever bump into the infamous save call anti-pattern:
try {
transactionTemplate.execute((TransactionCallback<Void>) transactionStatus -> {
postRepository.save(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
⠀
return null;
});
⠀
fail("Should throw UnsupportedOperationException!");
} catch (UnsupportedOperationException expected) {
LOGGER.warn("You shouldn't call the JpaRepository save method!");
}
Instead, you can use the persist, merge, or update method. So, if I want to persist some new entities, I can do it like this:
postRepository.persist(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
postRepository.persistAndFlush(
new Post()
.setId(2L)
.setTitle("Hypersistence Optimizer")
.setSlug("hypersistence-optimizer")
);
postRepository.persistAllAndFlush(
LongStream.range(3, 1000)
.mapToObj(i -> new Post()
.setId(i)
.setTitle(String.format("Post %d", i))
.setSlug(String.format("post-%d", i))
)
.collect(Collectors.toList())
);
And, pushing the changes from some detached entities back to the database is done as follows:
List<Post> posts = transactionTemplate.execute(transactionStatus ->
entityManager.createQuery("""
select p
from Post p
where p.id < 10
""", Post.class)
.getResultList()
);
posts.forEach(post ->
post.setTitle(post.getTitle() + " rocks!")
);
transactionTemplate.execute(transactionStatus ->
postRepository.updateAll(posts)
);
And, unlike merge, update allows us to avoid some unnecessary SELECT statements, and there’s just a single UPDATE being executed:
Query:[" update post set slug=?, title=? where id=?" ], Params:[ (high-performance-java-persistence, High-Performance Java Persistence rocks!, 1), (hypersistence-optimizer, Hypersistence Optimizer rocks!, 2), (post-3, Post 3 rocks!, 3), (post-4, Post 4 rocks!, 4), (post-5, Post 5 rocks!, 5), (post-6, Post 6 rocks!, 6), (post-7, Post 7 rocks!, 7), (post-8, Post 8 rocks!, 8), (post-9, Post 9 rocks!, 9) ]
Awesome right?
The BaseJpaRepository alternative
As I explained in this article, a more straightforward approach is to replace the JpaRepository with the BaseJpaRepository from the Hypersistence Utils project.
The BaseJpaRepository is available on Maven Central, so the first thing we need to do is add the Hypersistence Utils dependency.
For instance, if you are using Maven, then you need to add the following dependency to your project pom.xml configuration file.
For Hibernate 6.5, 6.4, and 6.3:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-utils-hibernate-63</artifactId>
<version>${hypersistence-utils.version}</version>
</dependency>
For Hibernate 5.5 and 5.6:
<dependency>
<groupId>io.hypersistence</groupId>
<artifactId>hypersistence-utils-hibernate-55</artifactId>
<version>${hypersistence-utils.version}</version>
</dependency>
Afterward, you need to include the BaseJpaRepositoryImpl in the @EnableJpaRepositories configuration like this:
@EnableJpaRepositories(
value = "your.repository.package",
repositoryBaseClass = BaseJpaRepositoryImpl.class
)
public class JpaConfiguration {
...
}
And that’s it!
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
JPA has no such thing as a save method. It’s just a hack that had to be implemented in the JpaRepository because the method is inherited from the CrudRepository, which is a base interface shared by almost Spring Data projects.
Using the HibernateRepository, not only that you can better reason which method you need to call, but you can also benefit from the update method that provides better performance for batch processing tasks.










Thank you for your expert reply!