The best way to use one-to-one table relationships
Imagine having a tool that can automatically detect JPA and Hibernate performance issues. Wouldn’t that be just awesome?
Well, Hypersistence Optimizer is that tool! And it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, or Play Framework.
So, enjoy spending your time on the things you love rather than fixing performance issues in your production system on a Saturday night!
Introduction
In this article, we are going to see what is the best way to use one-to-one table relationships.
I decided to write this article after reading this Tweet:
The goal of one-to-one table relationships is to separate data that doesn't change in sync. The separation provides better concurrency (less locking and more optimistic locking versions, better cache hits, and better data integrity as if the child association is optional, you…
— Vlad Mihalcea (@vlad_mihalcea) June 12, 2023
One-to-one table relationships
As I explained in this article, a relational database system defines three table relationship types:
- one-to-many
- one-to-one
- many-to-many
The one-to-one table relationships rely on the fact that both the parent and the child tables share the same Primary Key column values.
This is achieved by having the Primary Key column in the child table having a Foreign Key constraint that references the Primary Key column of the parent table, as illustrated by the following diagram:
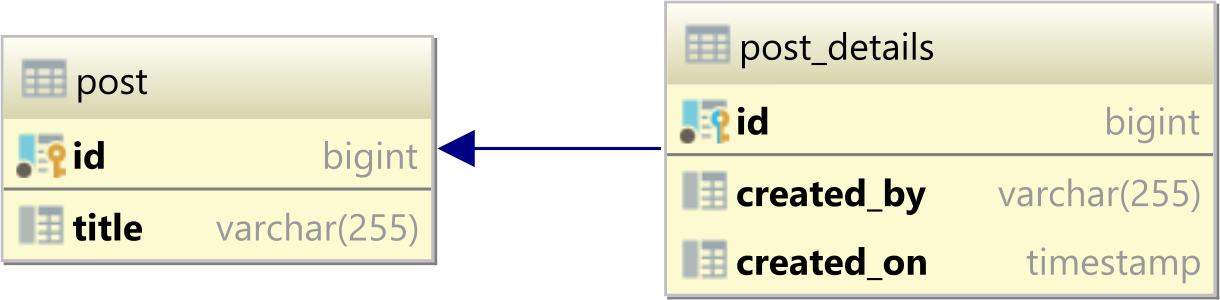
Why do we need one-to-one table relationships?
A very common question I get from my students when I run my High-Performance Java Persistence training is about the purpose of creating such a relationship when we can just move all the child table columns into the parent table.
Conditionality
In the post and post_details example above, let’s assume that we want this info to be optional.
However, when the user supplies the post_details info, we want to have both the created_by and created_on column values set. With a separate post_details table, we can easily do that since we just have to add the NOT NULL constraint on the two columns.
The fact that the post_details child record is optional is driven by its presence or absence, not by the absence of the created_by and created_on column values.
If we move the created_by and created_on columns to the post table, we would have to make the two columns nullable if this data is optional.
However, the user can still set the created_by column while leaving the created_on column null, and we don’t want that o happen. Preventing such issues will require us to create a BEFORE INSERT and UPDATE trigger to include such a validation, which is much more complex than just moving the optional data to a one-to-one child table.
Optimistic locking
Let’s consider the following use case:

In this example, we have a single post table that has multiple columns, and different users want to change different columns on the post table.
If we have a single version column, then only the first user UPDATE will go through, while the rest will get an OptimisticLockException if, at write time, the version has been changed from the one they previously read.
However, in this example, the three columns are not conflicting from a business perspective, so getting this OptimisticLockException would just affect the user experience with no benefit to our data access requirements.
To fix this issue, we can just split the post table into three tables:
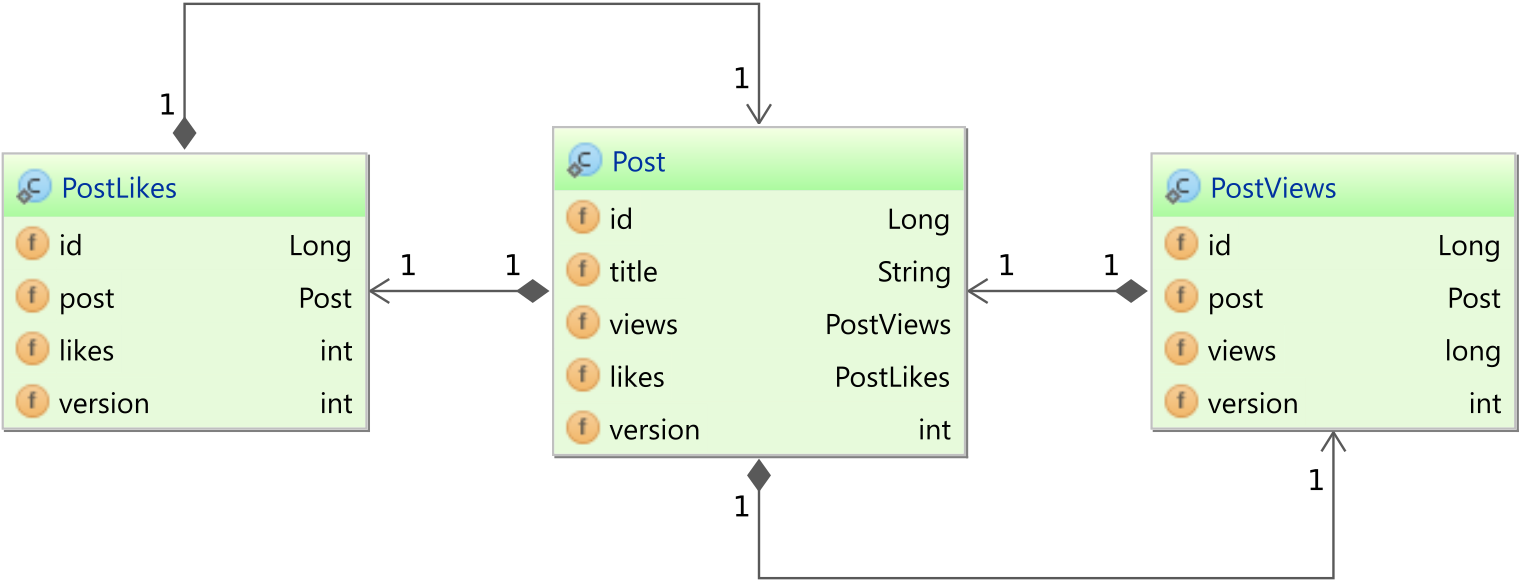
By doing this split, we can now get rid of the OptimisticLockException since all three users will apply changes to different tables:

For more details about optimistic locking, check out this article.
If we have two separate tables, then each table can define its own version column, and the two records can be changed.
Pessimistic locking
As I explained in this article, every time a transaction runs an UPDATE on a table record, that record will be locked to prevent other transactions from changing that row until the previous transaction commits or rolls back.
If, in the previous use case, our three users, Alice, Bob, and Carol, try to modify the post table, the first UPDATE will lock the post record, and the other two users executing the UPDATE statement will block until the first user decides to commit or rollback.
The larger the table, the higher the probability of locking.
However, if we split the post table into multiple tables, then instead of blocking on a single table record, we will be able to operate on multiple table records concurrently.
Buffer Pool and dirty pages
Relational database systems cache the table and index pages stored on the disk in the Buffer Pool so that the next time you need to load that page, you’d get it from memory (logical read) instead of from the disk (physician read). Since even the fastest disk drive is orders of magnitude slower than RAM, the Buffer Pool can really make a difference in terms of performance.

When you modify a table or an index, the page in the Buffer Pool is not flushed to the disk synchronously at transaction commit time but asynchronously at checkpoints.
If we have a table with hundreds of columns, then each column change will make the page dirty, and the entire page will have to be flushed to the disk.
If 99% of columns never change in that table, then the page will be flushed over and over just because a small percentage of columns are modified very frequently. By splitting the large table into multiple tables, we will operate with multiple pages, and only the ones that change will have to be flushed, leaving the rest untouched.
I'm running an online workshop on the 20-21 and 23-24 of November about High-Performance Java Persistence.

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
There is a very good reason why relational database systems offer one-to-one table relationships, and that’s because they can be really useful.
Knowing when to use them can really help you deal with some performance issues that, otherwise, would be much harder to be dealt with if we didn’t have one-to-one table relationships.








Vlad, thanks for this article! It’s terrific! 👏🏻👏🏻
It advises us on understanding how modeling our schema might help with performance and resilience.
I mean, those simple and essential guides can lead us to:
better constraints & consistency;
less locking & contention;
better latency & throughput;
You show all those guides and their benefits in a very didactic way!
Thanks, Vlad!
Thanks. I’m glad you liked it.
Stay tuned for more.