How to fetch a one-to-many DTO projection with JPA and Hibernate
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to show you how you can fetch a one-to-many relationship as a DTO projection when using JPA and Hibernate.
While entities make it very easy to fetch additional relationships, when it comes to DTO projections, you need to use a ResultTransformer to achieve this goal.
Table relationships
Let’s assume we have the following post and post_comment tables, which form a one-to-many relationship via the post_id Foreign Key column in the post_comment table.
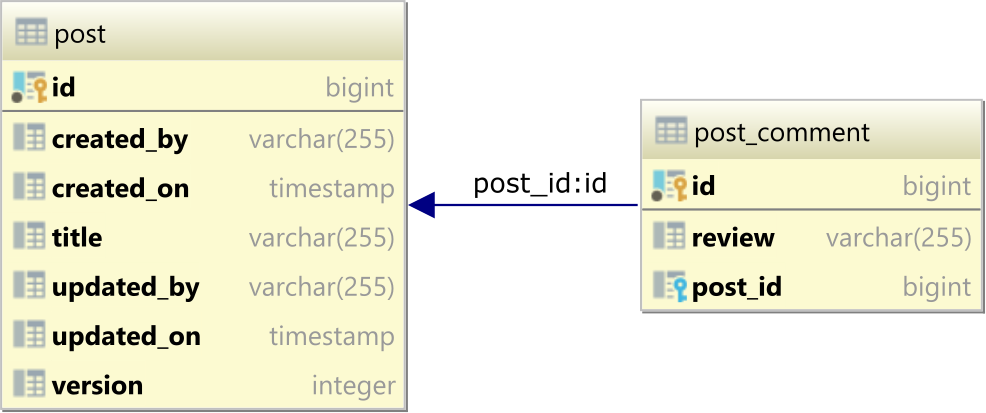
Fetching a one-to-many JPA entity projection
The aforementioned post table can be mapped to the following Post entity:
@Entity(name = "Post")
@Table(name = "post")
public class Post {
@Id
private Long id;
private String title;
@Column(name = "created_on")
private LocalDateTime createdOn;
@Column(name = "created_by")
private String createdBy;
@Column(name = "updated_on")
private LocalDateTime updatedOn;
@Column(name = "updated_by")
private String updatedBy;
@Version
private Integer version;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL, orphanRemoval = true)
private List<PostComment> comments = new ArrayList<>();
//Getters and setters omitted for brevity
public Post addComment(PostComment comment) {
comments.add(comment);
comment.setPost(this);
return this;
}
}
And the post_comment table is mapped to the following PostComment entity:
@Entity
@Table(name = "post_comment")
public class PostComment {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Post post;
private String review;
//Getters and setters omitted for brevity
}
The one-to-many table relationship is mapped as a bidirectional @OneToMany JPA association, and for this reason, we can easily fetch the association using the JOIN FETCH JPQL directive:
List<Post> posts = entityManager.createQuery("""
select distinct p
from Post p
join fetch p.comments pc
order by pc.id
""")
.setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false)
.getResultList();
The
HINT_PASS_DISTINCT_THROUGHis needed as we don’t want the DISTINCT JPQL keyword to be passed to the underlying SQL query. For more details about this JPA query hint, check out this article.
When running the JPQL query above, Hibernate generates the following SQL statement:
SELECT p.id AS id1_0_0_,
pc.id AS id1_1_1_,
p.created_by AS created_2_0_0_,
p.created_on AS created_3_0_0_,
p.title AS title4_0_0_,
p.updated_by AS updated_5_0_0_,
p.updated_on AS updated_6_0_0_,
p.version AS version7_0_0_,
pc.post_id AS post_id3_1_1_,
pc.review AS review2_1_1_,
pc.post_id AS post_id3_1_0__,
pc.id AS id1_1_0__
FROM post p
INNER JOIN post_comment pc ON p.id=pc.post_id
ORDER BY pc.id
The entity projection selects all entity properties and, while this is very useful when we want to modify an entity, for read-only projections, this can be an overhead.
Fetching a one-to-many DTO projection with JPA and Hibernate
Considering we have a use case that only requires fetching the id and title columns from the post table, as well as the id and review columns from the post_comment tables, we could use the following JPQL query to fetch the required projection:
select p.id as p_id,
p.title as p_title,
pc.id as pc_id,
pc.review as pc_review
from PostComment pc
join pc.post p
order by pc.id
When running the projection query above, we get the following results:
| p.id | p.title | pc.id | pc.review | |------|-----------------------------------|-------|---------------------------------------| | 1 | High-Performance Java Persistence | 1 | Best book on JPA and Hibernate! | | 1 | High-Performance Java Persistence | 2 | A must-read for every Java developer! | | 2 | Hypersistence Optimizer | 3 | It's like pair programming with Vlad! |
However, we don’t want to use a tabular-based ResultSet or the default List<Object[]>JPA or Hibernate query projection. We want to transform the aforementioned query result set to a List of PostDTO objects, each such object having a comments collection containing all the associated PostCommentDTO objects:
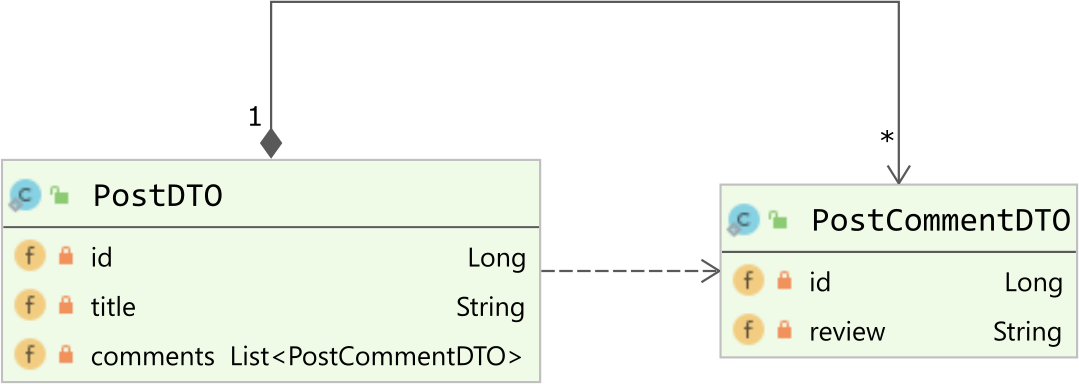
As I explained in this article, we can use a Hibernate ResultTransformer, as illustrated by the following example:
List<PostDTO> postDTOs = entityManager.createQuery("""
select p.id as p_id,
p.title as p_title,
pc.id as pc_id,
pc.review as pc_review
from PostComment pc
join pc.post p
order by pc.id
""")
.unwrap(org.hibernate.query.Query.class)
.setResultTransformer(new PostDTOResultTransformer())
.getResultList();
assertEquals(2, postDTOs.size());
assertEquals(2, postDTOs.get(0).getComments().size());
assertEquals(1, postDTOs.get(1).getComments().size());
The PostDTOResultTransformer is going to define the mapping between the Object[] projection and the PostDTO object containing the PostCommentDTO child DTO objects:
public class PostDTOResultTransformer
implements ResultTransformer {
private Map<Long, PostDTO> postDTOMap = new LinkedHashMap<>();
@Override
public Object transformTuple(
Object[] tuple,
String[] aliases) {
Map<String, Integer> aliasToIndexMap = aliasToIndexMap(aliases);
Long postId = longValue(tuple[aliasToIndexMap.get(PostDTO.ID_ALIAS)]);
PostDTO postDTO = postDTOMap.computeIfAbsent(
postId,
id -> new PostDTO(tuple, aliasToIndexMap)
);
postDTO.getComments().add(
new PostCommentDTO(tuple, aliasToIndexMap)
);
return postDTO;
}
@Override
public List transformList(List collection) {
return new ArrayList<>(postDTOMap.values());
}
}
The aliasToIndexMap is just a small utility that allows us to build a Map structure that associates the column aliases and the index where the column value is located in the Object[] tuple array:
public Map<String, Integer> aliasToIndexMap(
String[] aliases) {
Map<String, Integer> aliasToIndexMap = new LinkedHashMap<>();
for (int i = 0; i < aliases.length; i++) {
aliasToIndexMap.put(aliases[i], i);
}
return aliasToIndexMap;
}
The postDTOMap is where we are going to store all PostDTO entities that, in the end, will be returned by the query execution. The reason we are using the postDTOMap is that the parent rows are duplicated in the SQL query result set for each child record.
The computeIfAbsent method allows us to create a PostDTO object only if there is no existing PostDTO reference already stored in the postDTOMap.
The PostDTO class has a constructor that can set the id and title properties using the dedicated column aliases:
public class PostDTO {
public static final String ID_ALIAS = "p_id";
public static final String TITLE_ALIAS = "p_title";
private Long id;
private String title;
private List<PostCommentDTO> comments = new ArrayList<>();
public PostDTO(
Object[] tuples,
Map<String, Integer> aliasToIndexMap) {
this.id = longValue(tuples[aliasToIndexMap.get(ID_ALIAS)]);
this.title = stringValue(tuples[aliasToIndexMap.get(TITLE_ALIAS)]);
}
//Getters and setters omitted for brevity
}
The PostCommentDTO is built in a similar fashion:
public class PostCommentDTO {
public static final String ID_ALIAS = "pc_id";
public static final String REVIEW_ALIAS = "pc_review";
private Long id;
private String review;
public PostCommentDTO(
Object[] tuples,
Map<String, Integer> aliasToIndexMap) {
this.id = longValue(tuples[aliasToIndexMap.get(ID_ALIAS)]);
this.review = stringValue(tuples[aliasToIndexMap.get(REVIEW_ALIAS)]);
}
//Getters and setters omitted for brevity
}
That’s it!
Using the PostDTOResultTransformer, the SQL result set can be transformed into a hierarchical DTO projection, which is much convenient to work with, especially if it needs to be marshalled as a JSON response:
postDTOs = {ArrayList}, size = 2
0 = {PostDTO}
id = 1L
title = "High-Performance Java Persistence"
comments = {ArrayList}, size = 2
0 = {PostCommentDTO}
id = 1L
review = "Best book on JPA and Hibernate!"
1 = {PostCommentDTO}
id = 2L
review = "A must read for every Java developer!"
1 = {PostDTO}
id = 2L
title = "Hypersistence Optimizer"
comments = {ArrayList}, size = 1
0 = {PostCommentDTO}
id = 3L
review = "It's like pair programming with Vlad!"
If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
While entities make it very easy to fetch relationships, selecting all columns is not efficient if we only need a subset of entity properties.
On the other hand, DTO projections are more efficient from a SQL fetching perspective but require a little bit of work to associate parent and child DTOs. Luckily, the Hibernate ResultTransformer offers a very flexible solution to this problem, and we can fetch a one-to-many relation even as a DTO projection.









Thanks for the tip.
I wrote this helper class to map aliases to objects, you can use this helper in different Repositories. No need to cast and work with index / objects / aliases anymore 🙂
public class AliasObjectMapper { private final Map<String, Object> aliasToIndexMap = new HashMap<>(); public AliasObjectMapper(Object[] objects, String[] aliases) { for (int i = 0; i < objects.length; i++) { aliasToIndexMap.put( aliases[i].toLowerCase(), objects[i] ); } } public <T> T get(String alias) { return (T) aliasToIndexMap.get(alias.toLowerCase()); } }And so you can use it:
@Override public Property transformTuple(Object[] objects, String[] aliases) { AliasIndexMapper aliasIndexMapper = new AliasIndexMapper(objects, aliases); Long propertyId = aliasIndexMapper.get(PostDTO.ID_ALIAS);