A beginner’s guide to CDC (Change Data Capture)
Are you struggling with performance issues in your Spring, Jakarta EE, or Java EE application?
Imagine having a tool that could automatically detect performance issues in your JPA and Hibernate data access layer long before pushing a problematic change into production!
With the widespread adoption of AI agents generating code in a heartbeat, having such a tool that can watch your back and prevent performance issues during development, long before they affect production systems, can save your company a lot of money and make you a hero!
Hypersistence Optimizer is that tool, and it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, Micronaut, or Play Framework.
So, rather than allowing performance issues to annoy your customers, you are better off preventing those issues using Hypersistence Optimizer and enjoying spending your time on the things that you love!
Introduction
In this article, I’m going to explain what CDC (Change Data Capture) is, and why you should use it to extract database row-level changes.
In OLTP (Online Transaction Processing) systems, data is accessed and changed concurrently by multiple transactions, and the database changes from one consistent state to another. An OLTP system always shows the latest state of our data, therefore facilitating the development of front-end applications that require near real-time data consistency guarantees.
However, an OLTP system is no island, being just a small part of a larger system that encapsulates all data transformation needs required by a given enterprise. When integrating an OLTP system with a Cache, a Data Warehouse, or an In-Memory Data Grid, we need an ETL process to collect the list of events that changed the OLTP system data over a given period of time.
In this article, we are going to see various methods used for capturing events and propagating them to other data processing systems.
Trigger-based CDC (Change Data Capture)
Traditionally, the most common technique used for capturing events was to use database or application-level triggers. The reason why this technique is still very widespread is due to its simplicity and familiarity.
The Audit Log is a separate structure that records every insert, update or delete action that happens on a per-row basis.
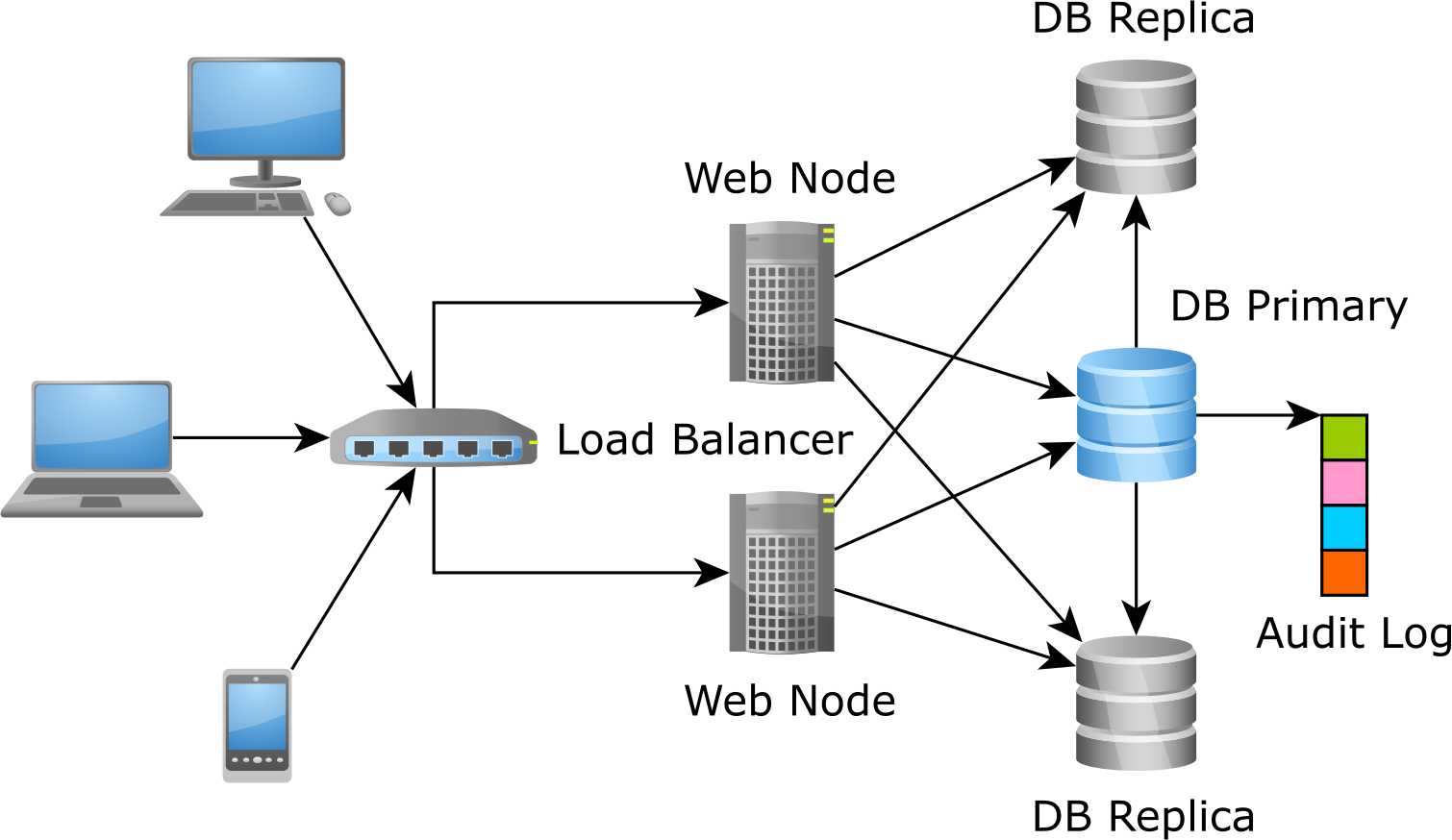
Database triggers
Every RDBMS supports triggers, although with slightly different syntax and capabilities.
PostgreSQL offers a dedicated page for implementing a trigger-based Audit Log.
Application-level triggers
There are frameworks, such as Hibernate Envers, which emulate database triggers at the application level. The advantage is that you don’t need to mind the database-specific syntax for triggers since events are captured anyway by the Persistence Context. The disadvantage is you can’t log data change events that don’t flow through the application (e.g., changes coming from a database console or from other systems that share the same RDBMS).
Transaction log-based CDC (Change Data Capture)
Although the database or application-level triggers are a very common choice for CDC, there is a better way. The Audit Log is just a duplicate of the database transaction log (a.k.a redo log or Write-Ahead Log) which already stores row-based modifications.
Therefore, you don’t really need to create a new Audit Log structure using database or application-level triggers, you just need to scan the transaction log and extract the CDC events from it.
Historically, each RDBMS used its own way of decoding the underlying transaction log:
- Oracle offers GoldenGate
- SQL Server offers built-in support for CDC
- MySQL, being so widely used for web applications, has been allowing you to capture CDC events through various 3rd party solutions, like LinkedIn’s DataBus
But there’s a new guy in town! Debezium is a new open-source project developed by RedHat, which offers connectors for Oracle, MySQL, PostgreSQL, and even MongoDB.
Not only that you can extract CDC events, but you can propagate them to Apache Kafka, which acts as a backbone for all the messages needed to be exchanged between various modules of a large enterprise system.

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
If you are using an OLTP application, CDC comes in handy when it comes to integrating with other modules in the current enterprise system. Some might argue that using Event Sourcing is better and can even replace OLTP systems entirely since you log every event upfront and derive the latest snapshot afterward.
While Event Sourcing has a lot of value, there are many applications that can benefit from the OLTP data model because the events are validated prior to being persisted, meaning that anomalies are eliminated by the database concurrency control mechanisms.
Otherwise, Google, who pioneered MapReduce for BigData through its Bigtable data storage, wouldn’t have invested so much effort into building a globally-distributed ACID-compliant database system such as Spanner, which was designed for building mission-critical online transaction processing (OLTP) applications.








