Professional connection pool sizing with FlexyPool
Imagine having a tool that can automatically detect JPA and Hibernate performance issues. Wouldn’t that be just awesome?
Well, Hypersistence Optimizer is that tool! And it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, or Play Framework.
So, enjoy spending your time on the things you love rather than fixing performance issues in your production system on a Saturday night!
Introduction
I previously wrote about the benefits of connection pooling and why monitoring it is of crucial importance. This post will demonstrate how FlexyPool can assist you in finding the right size for your connection pools.
Know your connection pool
The first step is to know your connection pool settings. My current application uses XA transactions, therefore we use Bitronix transaction manager, which comes with its own connection pooling solution.
Accord to the Bitronix connection pool documentation we need to use the following settings:
- minPoolSize: the initial connection pool size
- maxPoolSize: the maximum size the connection pool can grow to
- maxIdleTime: the maximum time a connection can remain idle before being destroyed
- acquisitionTimeout: the maximum time a connection request can wait before throwing a timeout. The default value of 30s is way too much for our QoS
Configuring FlexyPool
FlexyPool comes with a default metrics implementation, built on top of Dropwizard Metrics and offering two reporting mechanisms:
An enterprise system must use an central monitoring tool, such as Ganglia or Graphite and instructing FlexyPool to use a different reporting mechanism is fairly easy. Our example will export reports to CSV files and this is how you can customize the default metrics settings.
Initial settings
We only have to give a large enough maxOverflow and retryAttempts and leave FlexyPool find the equilibrium pool size.
| Name | Value | Description |
|---|---|---|
| minPoolSize | 0 | The pool starts with an initial size of 0 |
| maxPoolSize | 1 | The pool starts with a maximum size of 1 |
| acquisitionTimeout | 1 | A connection request will wait for 1s before giving up with a timeout exception |
| maxOverflow | 9 | The pool can grow up to 10 connections (initial maxPoolSize + maxOverflow) |
| retryAttempts | 30 | If the final maxPoolSize of 10 is reached and there is no connection available, a request will retry 30 times before giving up. |
Metrics time
Our application is a batch processor and we are going to let it process a large amount of data so we can gather the following metrics:
- concurrentConnectionsHistogram

- concurrentConnectionRequestsHistogram

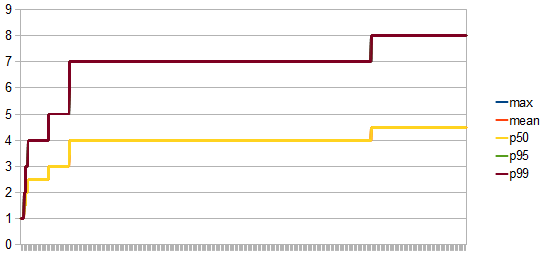
- maxPoolSizeHistogram
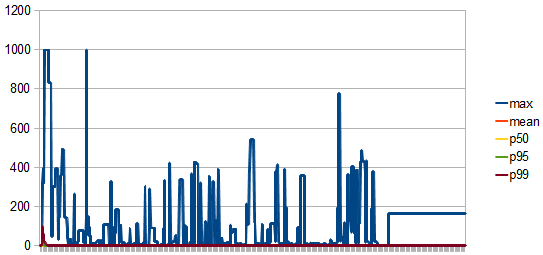
- connectionAcquireMillis
- retryAttemptsHistogram
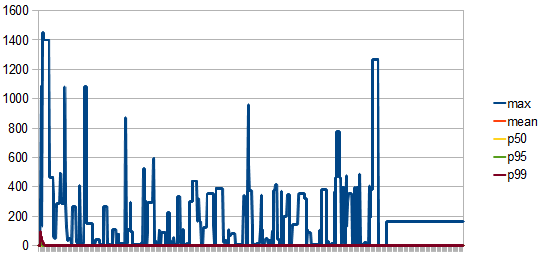
- overallConnectionAcquireMillis
- connectionLeaseMillis
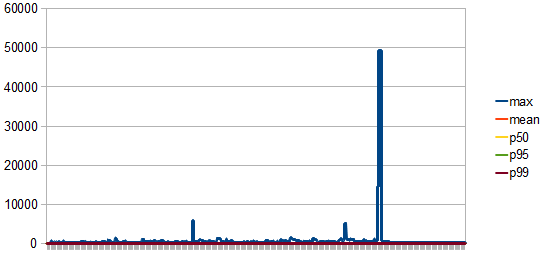
After analysing the metrics, we can draw the following conclusions:
- The max pool size should be 8
- For this max pool size there is no retry attempt.
- The connection acquiring time has stabilized after the pool has grown to its max size.
- There is a peak connection lease time of 50s causing the pool size to grow from 7 to 8. Lowering the time the connections are being held allows us to decrease the pool size as well.
If the database maximum connection count is 100 we can have at most 12 concurrent applications running.
Pushing the comfort zone
Let’s assume that instead of 12 we would need to run 19 such services. This means the pool size must be at most 5. Lowering the pool size will increase the connection request contention and the probability of connection acquire retry attempts.
We will change the maxOverflow to 4 this time while keeping the other settings unchanged:
| Name | Value | Description |
|---|---|---|
| maxOverflow | 4 | The pool can grow up to 10 connections (initial maxPoolSize + maxOverflow) |
Metrics reloaded
These are the new metrics:
- concurrentConnectionsHistogram
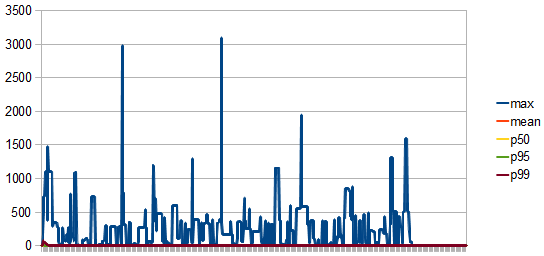
- concurrentConnectionsCountHistogram

- maxPoolSizeHistogram

- connectionAcquireMillis

- retryAttemptsHistogram

- overallConnectionAcquireMillis
- connectionLeaseMillis
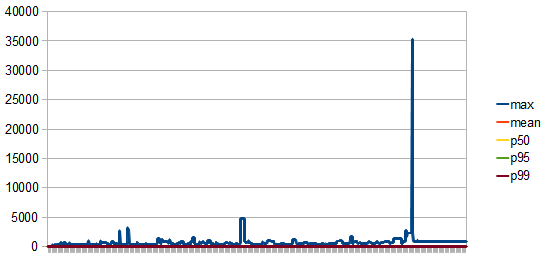
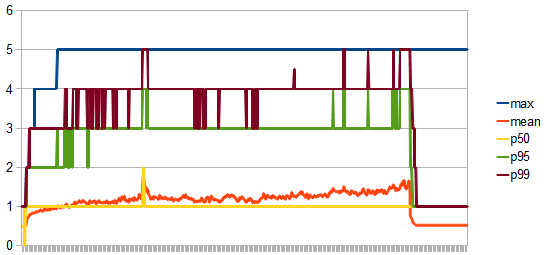
Analysing the metrics, we can conclude that:
- For the max pool size of 5 there are at most 3 retry attempts.
- The overall connection acquiring time confirms the retry attempts.
- The peak connection lease time was replicated, even if it’s around 35s this time.
I'm running an online workshop on the 20-21 and 23-24 of November about High-Performance Java Persistence.

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
FlexyPool eases connection pool sizing while offering a failover mechanism for those unforeseen situations when the initial assumptions don’t hold up anymore.
Alerts may be triggered whenever the number of retries exceeds a certain threshold, allowing us to step in as soon as possible.







