Why you should never use the TABLE identifier generator with JPA and Hibernate
Imagine having a tool that can automatically detect JPA and Hibernate performance issues. Wouldn’t that be just awesome?
Well, Hypersistence Optimizer is that tool! And it works with Spring Boot, Spring Framework, Jakarta EE, Java EE, Quarkus, or Play Framework.
So, enjoy spending your time on the things you love rather than fixing performance issues in your production system on a Saturday night!
Introduction
From a data access perspective, JPA supports two major types of identifiers:
- assigned
- generated
The assigned identifiers must be manually set on every given entity prior to being persisted. For this reason, assigned identifiers are suitable for natural keys.
For synthetic Primary Keys, we need to use a generated entity identifier, which is supported by JPA through the use of the @GeneratedValue annotation.
There are four types of generated identifier strategies which are defined by the GenerationType enumeration:
AUTOIDENTITYSEQUENCETABLE
The AUTO identifier generator strategy chooses one of the other three strategies (IDENTITY, SEQUENCE or TABLE) based on the underlying relational database capabilities.
While IDENTITY maps to an auto-incremented column (e.g. IDENTITY in SQL Server or AUTO_INCREMENT in MySQL) and SEQUENCE is used for delegating the identifier generation to a database sequence, the TABLE generator has no direct implementation in relational databases.
This post is going to analyze why the TABLE generator is a poor choice for every enterprise application that cares for performance and scalability.
TABLE generator
To understand how the TABLE generator works, consider the following Post entity mapping:
@Entity
@Table(name = "post")
public class Post {
@Id
@GeneratedValue(strategy=GenerationType.TABLE)
private Long id;
}
The following output is obtained when inserting a new Post entity:
SELECT tbl.next_val FROM hibernate_sequences tbl WHERE tbl.sequence_name=default FOR UPDATE INSERT INTO hibernate_sequences (sequence_name, next_val) VALUES (default, 1) UPDATE hibernate_sequences SET next_val=2 WHERE next_val=1 AND sequence_name=default SELECT tbl.next_val FROM hibernate_sequences tbl WHERE tbl.sequence_name=default FOR UPDATE UPDATE hibernate_sequences SET next_val=3 WHERE next_val=2 AND sequence_name=default DEBUG - Flush is triggered at commit-time INSERT INTO post (id) values (1, 2)
The table generator benefits from JDBC batching, but every table sequence update incurs three steps:
- The lock statement is executed to ensure that the same sequence value is not allocated for two concurrent transactions.
- The current value is incremented in the data access layer.
- The new value is saved back to the database and the secondary transaction is committed so to release the row-level lock.
Unlike identity columns and sequences, which can increment the sequence in a single request, the TABLE generator entails a significant performance overhead. For this reason, Hibernate comes with a series of optimizers which can improve performance for both SEQUENCE and TABLE generators, like the pooled or pooled-lo optimizers.
Although it is a portable identifier generation strategy, the
TABLEgenerator introduces a serializable execution (the row-level lock), which can hinder scalability.Compared to this application-level sequence generation technique, identity columns and sequences are highly optimized for high concurrency scenarios and should be the preferred choice
The cost of transactional row-level locks when emulating a sequence
Because of the mismatch between the identifier generator and the transactional write-behind cache, JPA offers an alternative sequence-like generator that works even when sequences are not natively supported.
A database table is used to hold the latest sequence value, and row-level locking is employed to prevent two concurrent connections from acquiring the same identifier value.
A database sequence is a non-transactional object because the sequence value allocation happens outside of the transactional context associated with the database connection requesting a new identifier.
Database sequences use dedicated locks to prevent concurrent transactions from acquiring the same value, but locks are released as soon as the counter is incremented. This design ensures minimal contention even when the sequence is used concomitantly by multiple concurrent transactions. Using a database table as a sequence is challenging, as, to prevent two transactions from getting the same sequence value, row-level locking must be used. However, unlike the sequence object locks, the row-level lock is transactional, and, once acquired, it can only be released when the current transaction ends (either committing or rolling back).
This would be a terrible scalability issue because a long-running transaction would prevent any other transaction from acquiring a new sequence value. To cope with this limitation, a separate database transaction is used for fetching a new sequence value. This way, the row-level lock associated with incrementing the sequence counter value can be released as soon as the sequence update transaction ends.
For local transactions (e.g. RESOURCE_LOCAL in JPA terminology), a new transaction means fetching another database connection and committing it after executing the sequence processing logic. This can put additional pressure on the underlying connection pool, especially if there is already a significant contention for database connections.
In a JTA environment, the currently running transaction must be suspended, and the sequence value is fetched in a separate transaction. The JTA transaction manager has to do additional work to accommodate the transaction context switch, and that can also have an impact on the overall application performance.
Without any application-level optimization, the row-level locking approach can become a performance bottleneck if the sequence logic is called way too often.
Performance testing time
To evaluate the concurrency cost of each identifier generators, the following test measures the time it takes to insert 100 Post entities when multiple running threads are involved.
JDBC batching is enabled, and the connection pool is adjusted to accommodate the maximum number of database connection required (e.g. 32). In reality, the application might not be configured with so many database connections, and the TABLE generator connection acquisition cost might be even higher.
The first relational database system under test supports identity columns, so it is worth measuring how the identifier and the TABLE generator compete because the Hibernate IDENTITY generator does not support JDBC batching for INSERT statements, as explained in this article. Each test iteration increases contention by allocating more worker threads that need to execute the same database insert load.

Even if it cannot benefit from JDBC batching, the IDENTITY generator still manages to outperform the TABLE generator, which uses a pooled optimizer with an increment size of 100.
The more threads are used, the less efficient the table generator becomes. On the other hand, identity columns scale much better with more concurrent transactions. Even if does not support JDBC batching, native identity columns are still a valid choice, and, in future, Hibernate might even support batch inserts for those as well.
The gap between the sequence and the table generator is even higher because, just like the table generator, the sequence generator can also take advantage of the pooled optimizer as well as JDBC batch inserts.
Running the same test against a relational database supporting sequences, the following results are being recorded:
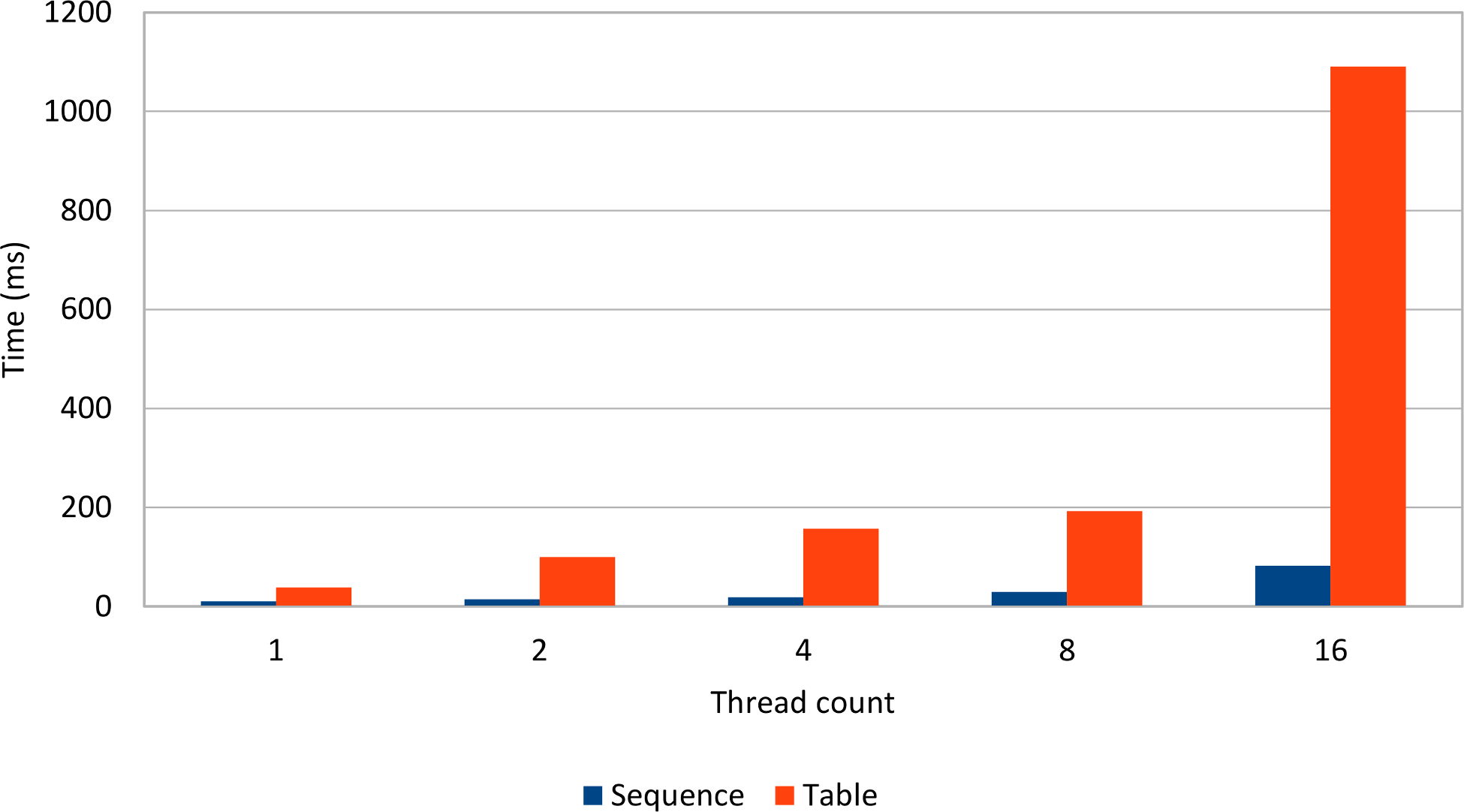
The performance impact of the TABLE generator becomes noticeable in highly concurrent environments, where the row-level locking and the database connection switch introduces a serial execution.
I'm running an online workshop on the 20-21 and 23-24 of November about High-Performance Java Persistence.

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.



Conclusion
The row-level locking solution employed by the TABLE generator incurs a serialization portion which hinders concurrency, as explained by the Universal Scalability Law (which is a generalization of Amdhal’s Law).
Because they use lightweight synchronization mechanisms, database sequences scale better than row-level locking concurrency control mechanisms. Database sequences are the most efficient Hibernate identifier choice, allowing sequence call optimizers and without compromising JDBC batching.
If you want database portability, you don’t really need the
TABLEgenerator. You can mix theSEQUENCEand theIDENTITYgenerator as explained in this article.







